Monitoring Practices and Tools for Kubernetes
Monitoring Kubernetes isn’t just about monitoring resource utilization—it's about proactively identifying performance issues, optimizing resource allocation, and maintaining the health of your entire system. With the rise of microservices and distributed architectures, real-time monitoring has become a non-negotiable practice for DevOps teams and system administrators.
Kubernetes' dynamic nature, with its self-healing, scaling, and orchestration capabilities, can easily hide underlying problems. Without real-time insights into the state of your clusters, you risk running into bottlenecks, performance degradation, or even full-scale failures. That's why having a robust, reliable monitoring strategy tailored to Kubernetes is vital for ensuring consistent performance and stability.
In this guide, we will walk you through the key metrics, tools, and best practices for monitoring Kubernetes effectively. From tracking node and pod health to integrating comprehensive tools like OpenObserve for metrics and traces, monitoring Kubernetes becomes not only manageable but also insightful, empowering your team to detect and resolve issues before they escalate.
Key Practices for Monitoring Kubernetes Clusters
When managing Kubernetes, maintaining performance across all clusters is a critical task that ensures the entire system runs efficiently. The distributed and dynamic nature of Kubernetes means that any hidden issues can cause bottlenecks or even lead to unexpected downtime. Monitoring helps you detect these performance issues early and avoid disruptions.
- Identifying Performance Issues in Kubernetes Clusters
Kubernetes is designed for flexibility, but it can create challenges in identifying performance bottlenecks. Whether it’s high CPU usage, memory constraints, or inefficient resource allocation, monitoring helps pinpoint these issues. By closely tracking node and pod metrics, you can spot performance problems early and take action to prevent more extensive system failures. - Ensuring Optimal Resource Utilization
One key reason to monitor Kubernetes is to ensure that resources—such as CPU, memory, and disk space—are allocated effectively. Misallocated resources can lead to underperformance or unnecessary costs. Monitoring tools provide real-time feedback, allowing you to adjust your resources dynamically to meet your application's needs. - Importance of Real-Time Insights for Cluster Stability
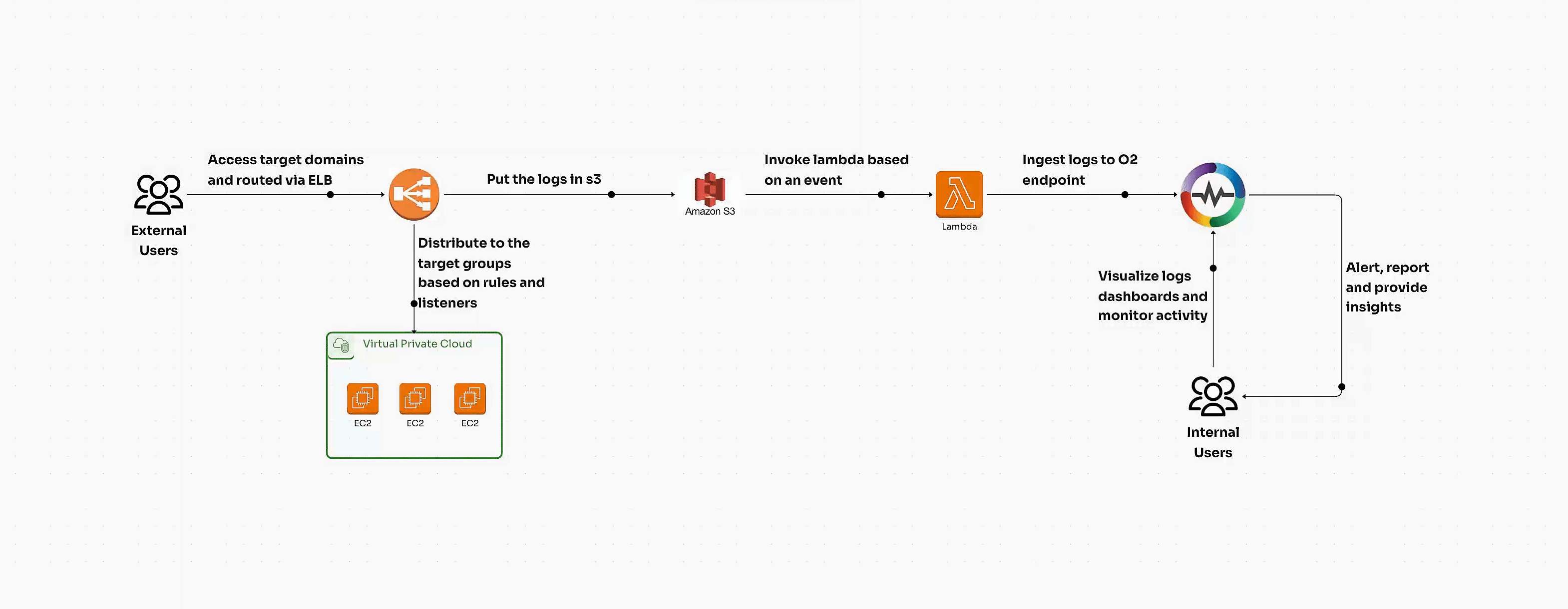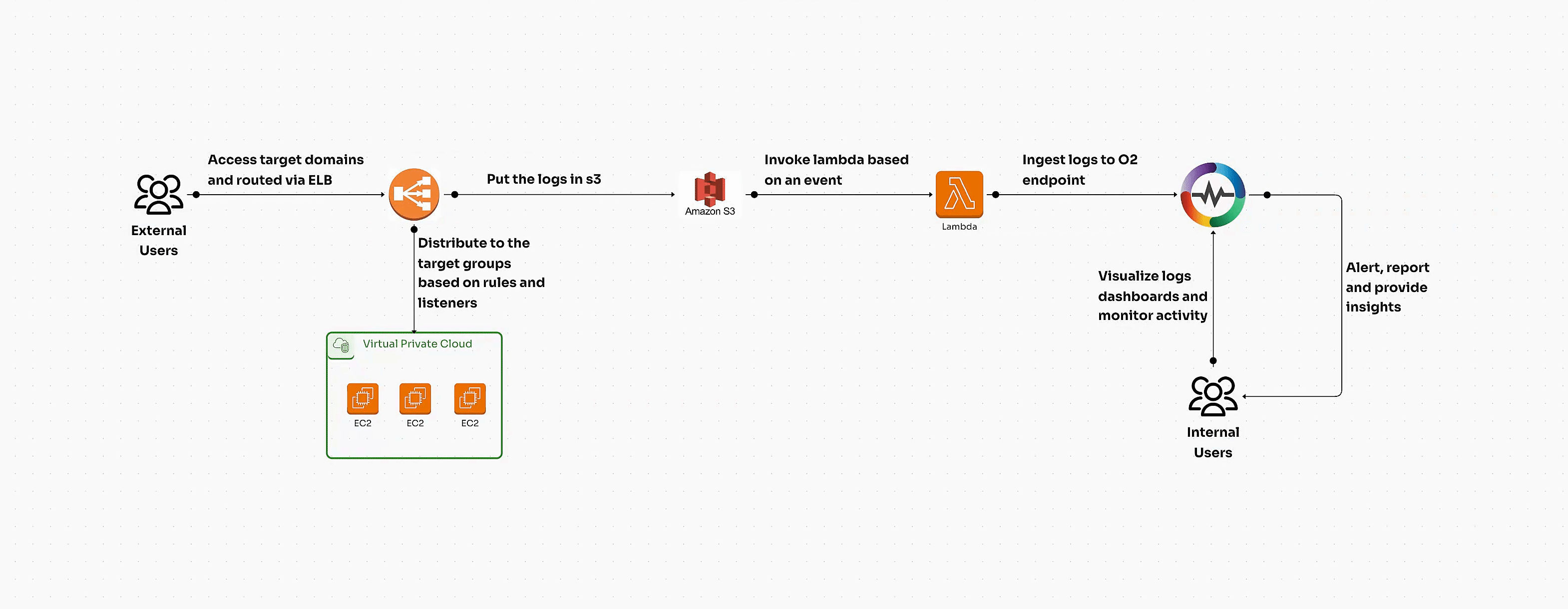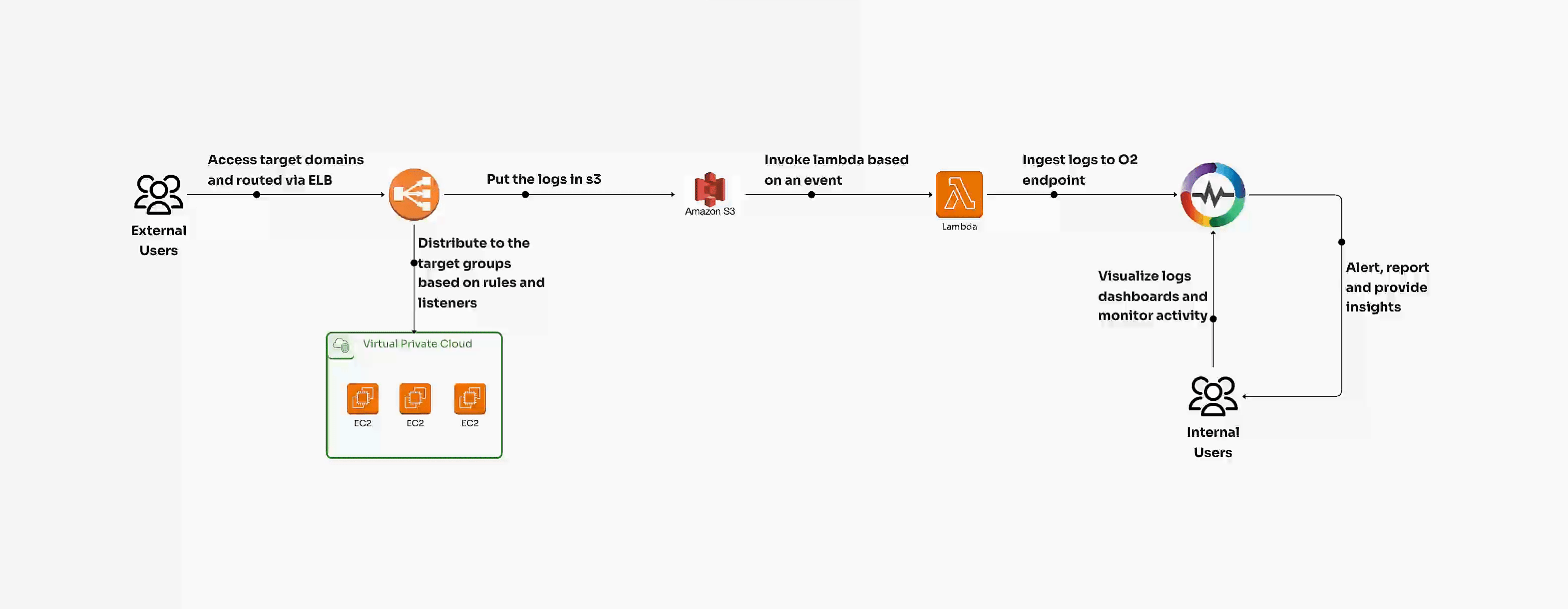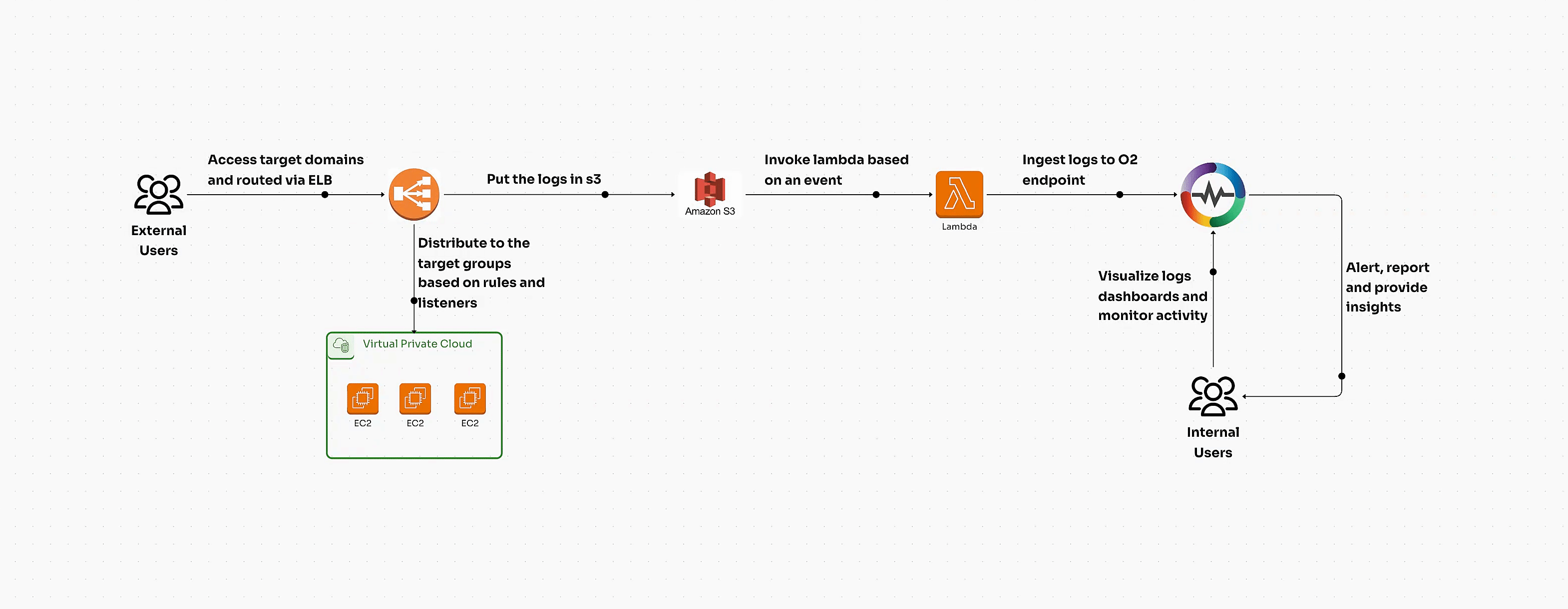
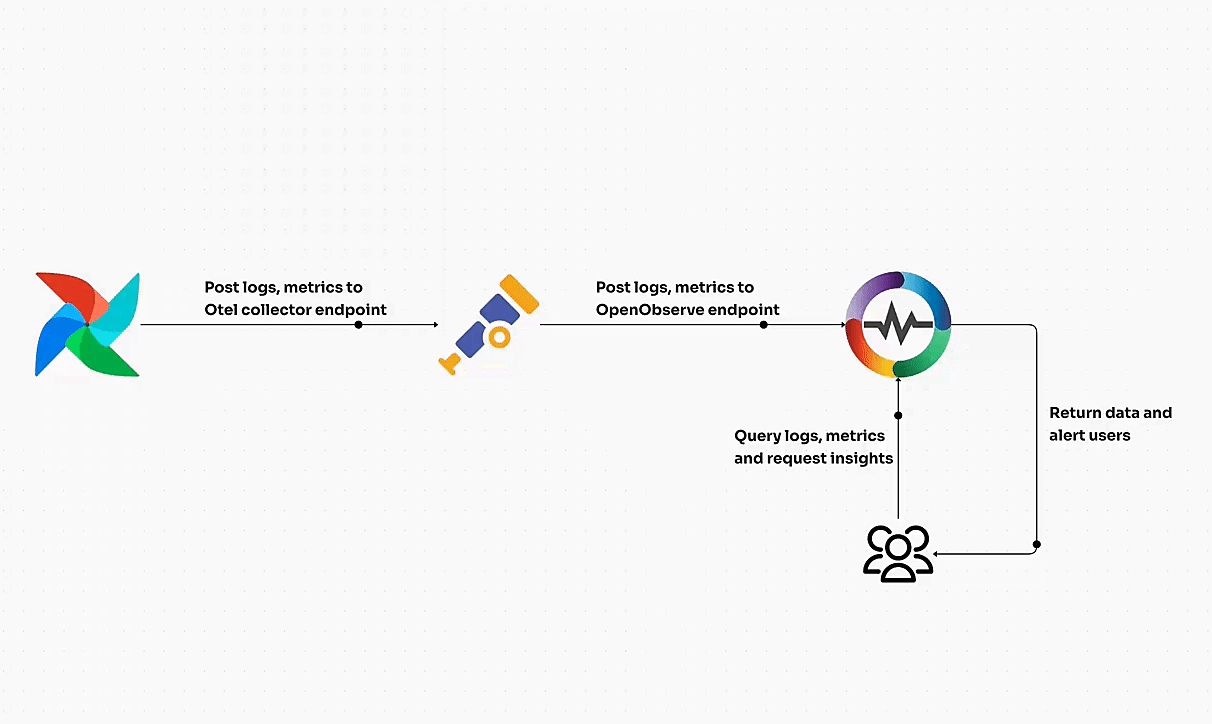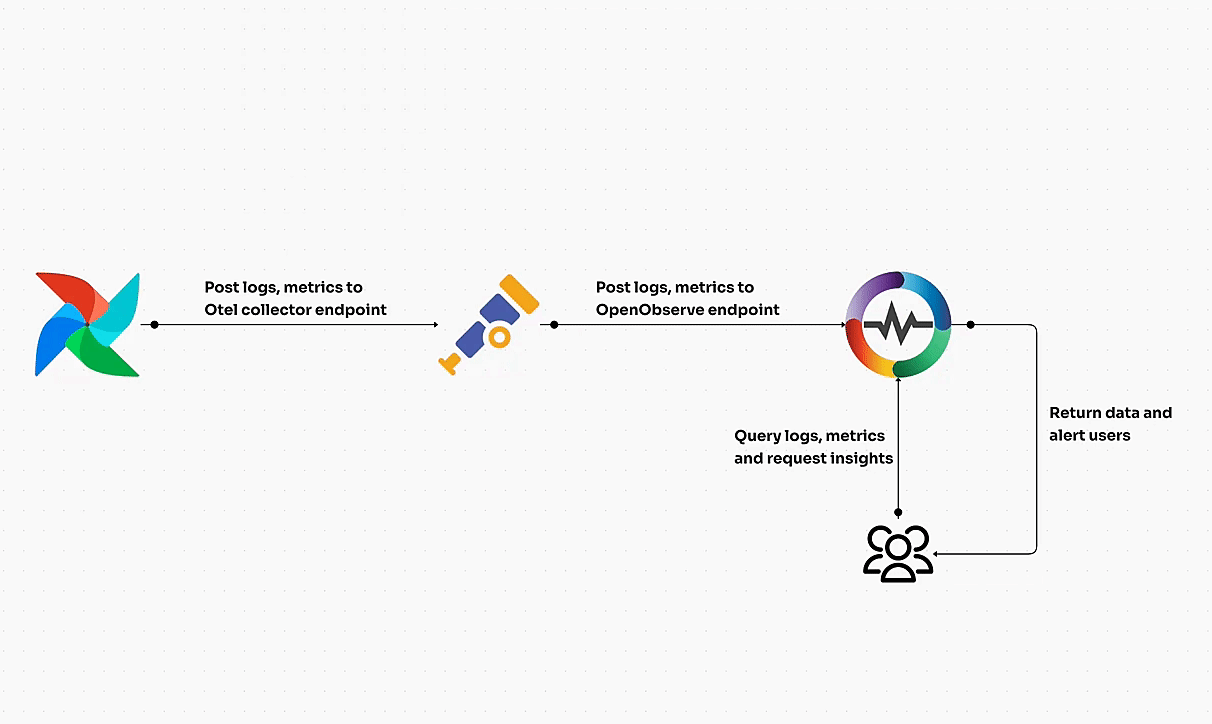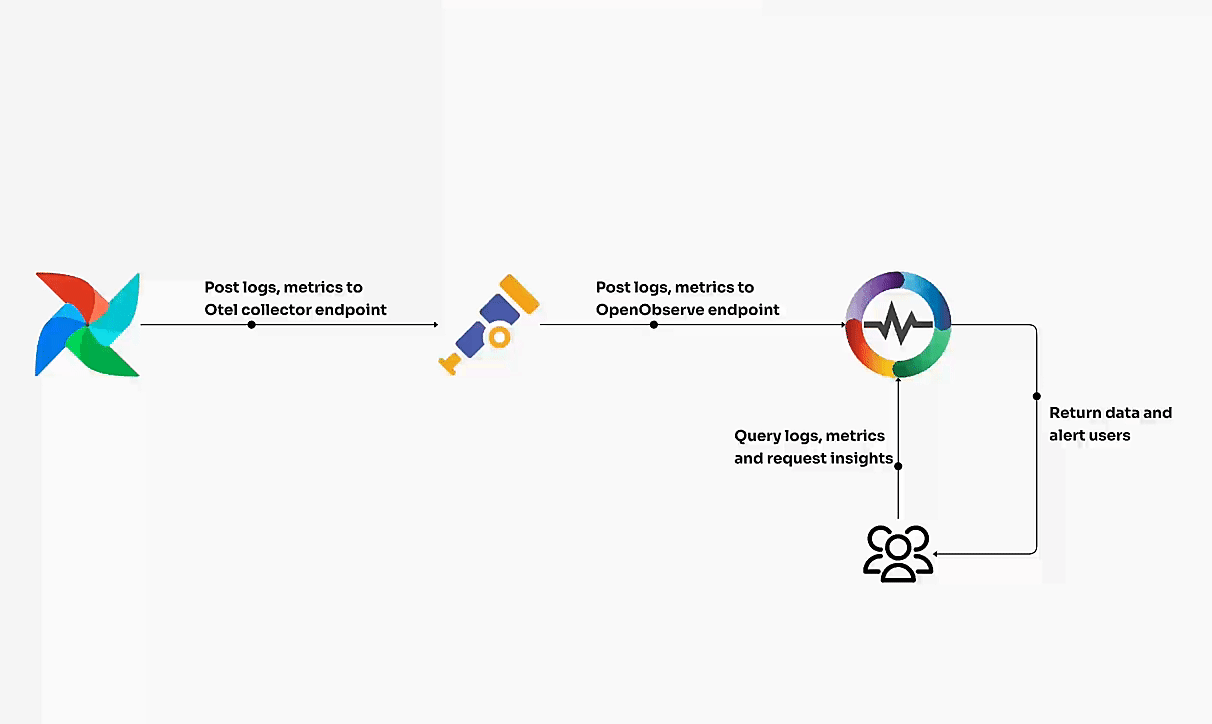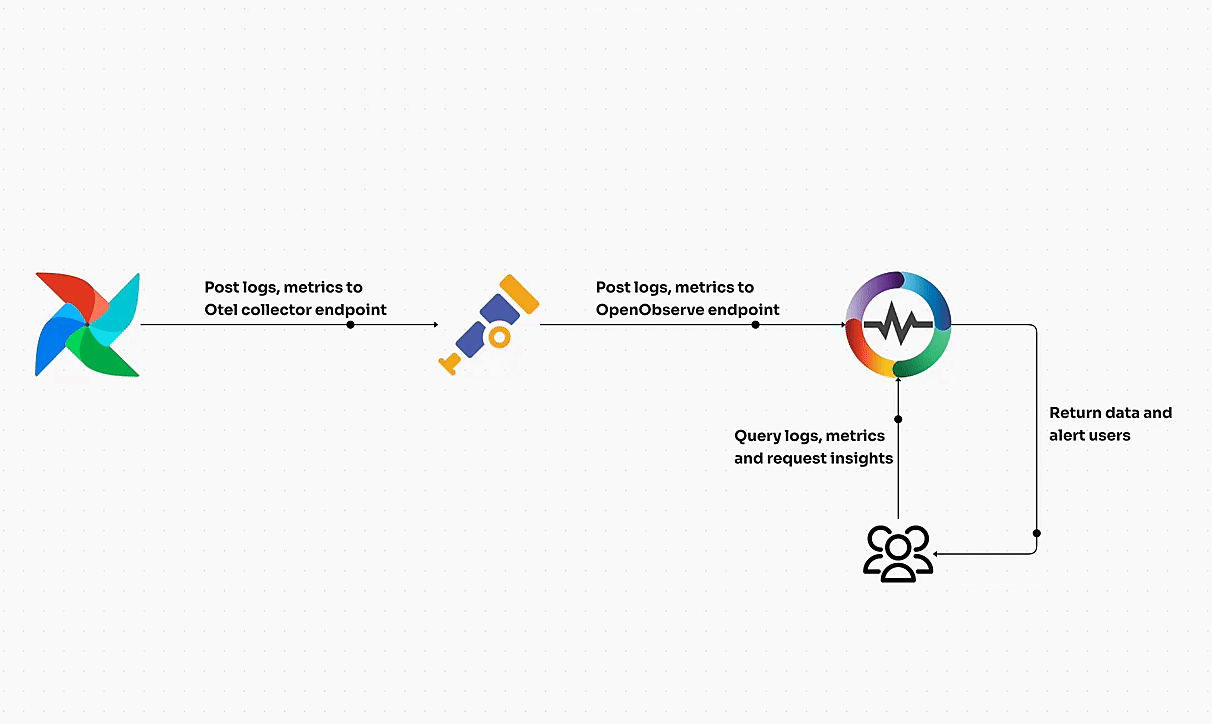
Kubernetes clusters can be volatile if not managed in real time. Immediate visibility into metrics, logs, and traces ensures you’re alerted to any instability within your cluster. Tools like OpenObserve provide this real-time insight, offering a unified platform for collecting, analyzing, and visualizing data across your Kubernetes environments. With OpenObserve, teams can effectively track performance metrics, detect anomalies, and ensure cluster stability by analyzing data in real time.
Visit the OpenObserve website to explore how this powerful observability platform can optimize your Kubernetes monitoring and analysis.
In the next section, we'll explore the essential metrics you should monitor to ensure your Kubernetes clusters remain healthy and optimized.
Read more about Fluentd and Kubernetes: How they work together
Essential Kubernetes Metrics to Monitor
Kubernetes thrives on its ability to scale and manage workloads efficiently, but to keep everything running smoothly, tracking key metrics is critical.
Here's a breakdown of the essential Kubernetes metrics that ensure optimal performance and resource utilization across your clusters.
- Cluster Monitoring: Nodes, Pods, Resource Utilization
Monitoring the overall health of your cluster involves keeping track of nodes and pods, which are fundamental components of Kubernetes architecture. You'll want to monitor:
- Node Metrics: This measures the CPU, memory, and disk usage of each node, ensuring that none are overworked or underutilized.
- Pod Metrics: How well each pod uses the resources allocated to it, including the status of each container within a pod.
- Resource Utilization: Understand how effectively the cluster is using its allocated resources, and adjust accordingly to prevent wastage and bottlenecks.
- Pod Monitoring: Container Metrics, Application Metrics
Within a pod, monitoring container performance is key. This includes tracking the health of the applications running inside containers and how well they utilize resources. Some important metrics are:
- Container Metrics include CPU and memory usage per container. These help identify containers that may be consuming too many resources and affecting other workloads.
- Application Metrics: Specific to the application running inside the container. This includes request latencies, error rates, and throughput — ensuring the application performs efficiently even as workloads scale.
- Control Plane Metrics: Kube-apiserver, Etcd, Kube-scheduler
The Kubernetes control plane is the brain of your cluster. To ensure it functions well, you'll need to keep an eye on:
- Kube-apiserver: Responsible for communication between components in Kubernetes. Monitoring its latency, request volume, and error rates can indicate potential performance issues.
- Etcd: A key-value store that holds all cluster data. Monitoring disk I/O and latency helps maintain cluster consistency and prevent data bottlenecks.
- Kube-scheduler: This tool efficiently assigns pods to nodes. It tracks scheduling latency and pod binding failures to ensure smooth workload distribution.
By monitoring these metrics closely, you'll gain real-time insights into how well your Kubernetes cluster is performing and be able to make data-driven decisions to optimize its performance.
In the next section, we’ll explore different methods to collect these essential metrics effectively.
Methods for Collecting Kubernetes Metrics
When managing Kubernetes clusters, collecting metrics is essential for monitoring performance, optimizing resource allocation, and identifying issues early. Here are the key methods for gathering Kubernetes metrics effectively:
- Using DaemonSets for Consistent Monitoring Across Nodes
DaemonSets ensure that a copy of a specific pod runs on all or a subset of nodes in your cluster. This is particularly useful for system-level monitoring tools like Prometheus Node Exporter, which collects metrics from every node.
DaemonSets provide a consistent and scalable way to gather node metrics, ensuring comprehensive visibility across the entire cluster without manual intervention.
- Heapster: Functionality and Integration
Heapster was one of the earlier solutions for Kubernetes monitoring, integrated directly into the cluster to collect metrics from nodes and pods.
Although Heapster has been deprecated, it helped establish a model for current tools by offering real-time resource usage data, which is now typically handled by Prometheus or custom-built solutions.
- OpenTelemetry for Comprehensive Telemetry Data
OpenTelemetry is rapidly becoming the go-to standard for collecting, processing, and exporting telemetry data, including traces, logs, and metrics. It provides a unified approach to telemetry across various services and platforms, making it easier to monitor Kubernetes clusters holistically.
When you use OpenTelemetry, platforms like OpenObserve can act as the perfect long-term storage solution, offering advanced analytics and real-time visualization. This integration allows you to harness the full power of telemetry data for comprehensive analysis of system performance and health, keeping your Kubernetes environments running smoothly.
In the next section, we’ll dive into the tools that facilitate effective Kubernetes monitoring and how they complement the methods discussed here.
Read more about Deploying Grafana with Helm Charts in Kubernetes
Key Tools for Kubernetes Monitoring
Monitoring Kubernetes clusters effectively requires the use of specialized tools to track metrics, logs, and traces. Below are some key tools for Kubernetes monitoring:
1. OpenObserve
OpenObserve is an open-source platform that excels in monitoring and observability for Kubernetes clusters. It allows teams to collect, analyze, and visualize metrics, logs, and traces in real time, providing a single pane of glass for monitoring. OpenObserve supports long-term data storage, and its robust querying and dashboard capabilities ensure that teams have a complete understanding of their system’s performance.
OpenObserve integrates seamlessly with organizations using OpenTelemetry, making it a powerful choice for enhancing visibility into Kubernetes clusters.
Sign up for OpenObserve today and simplify your Kubernetes monitoring with a scalable, all-in-one observability platform.
2. Prometheus
Prometheus is widely regarded as one of the best tools for monitoring Kubernetes clusters. It scrapes metrics from Kubernetes nodes, pods, and services, offering real-time insights into cluster health and performance.
Prometheus integrates seamlessly with OpenObserve, allowing users to store their long-term metrics while providing a robust backend for data analysis.
With its powerful alerting features, Prometheus ensures teams are notified of any critical issues before they impact production, and the integration with OpenObserve enables deeper data storage and advanced visualization.
Read more about Send Kubernetes Metrics Using Prometheus to OpenObserve
3. Kubernetes Dashboard
The Kubernetes Dashboard is a web-based UI for managing and monitoring Kubernetes clusters. It provides an easy-to-use interface for real-time insights into the status of the cluster, resource allocation, and workload performance. You can view logs, scale deployments, and manage Kubernetes resources all in one place.
While it’s great for cluster-level management, it works best when combined with more advanced monitoring tools for deeper insights.
4. ELK Stack
The ELK (Elasticsearch, Logstash, Kibana) Stack is a popular choice for log aggregation and visualization. It enables teams to centralize logs from various sources in a Kubernetes environment, making it easier to troubleshoot issues and analyze performance trends.
With Kibana's customizable dashboards, users can visualize and explore their log data in a meaningful way. This is particularly valuable in identifying performance bottlenecks and gaining visibility into application behavior.
Read more on Elasticsearch Match Query Usage and Examples
5. Datadog
Datadog offers a cloud monitoring solution with extensive integrations and machine learning-driven analysis. For Kubernetes environments, Datadog provides detailed visibility into both application and infrastructure performance.
Datadog is a robust solution for large, dynamic environments that require constant oversight and optimization with real-time monitoring, anomaly detection, and root cause analysis.
Read more about Introduction to Application Performance Monitoring with Datadog
With a solid understanding of the essential tools for Kubernetes monitoring, the next step is to ensure you're following best practices to maximize performance and efficiency.
Best Practices for Kubernetes Monitoring
- Use a Unified Interface for Monitoring Metrics
When monitoring Kubernetes clusters, it’s crucial to have a unified platform where you can track metrics, logs, and traces in one place. A unified interface eliminates the need for multiple tools and allows for a more efficient troubleshooting process.
For example, OpenObserve offers a consolidated dashboard where you can visualize and analyze your Kubernetes data, simplifying the entire monitoring process.
- Ensure Scalability and Sufficient Data Retention
As your Kubernetes clusters scale, so does the volume of metrics, logs, and traces that need to be collected and stored. Ensure your monitoring solution can handle this growth without performance degradation.
OpenObserve provides a scalable platform with advanced data retention capabilities, ensuring you can monitor your environment at scale without worrying about losing historical data.
- Generate Alerts and Notify Appropriate Staff
One of the essential practices for Kubernetes monitoring is setting up automated alerts. By configuring alert thresholds, you can proactively identify and resolve potential issues before they escalate.
Always ensure that the right teams are notified in real time to address any issues as they arise.
- Integrate Monitoring with CI/CD Pipelines
To maintain a seamless flow from development to deployment, integrate your monitoring tools with your CI/CD pipelines. This integration ensures you’re aware of performance issues early on and can address them before they affect production.
- Employ Namespaces and Labels for Organization
Organizing your monitoring setup is key to ensuring clarity, especially in complex Kubernetes environments. Use namespaces and labels to categorize your resources effectively, enabling more granular monitoring and easier identification of issues within specific areas of your clusters.
By implementing these best practices, you'll build a robust and scalable Kubernetes monitoring system that not only ensures optimal performance but also prepares you for future growth.
Conclusion
Monitoring Kubernetes is essential to ensuring cluster health, optimising resource utilisation, and preventing performance issues. By following best practices and leveraging the right tools, like OpenObserve, teams can streamline monitoring efforts, gain real-time insights, and scale their operations efficiently. OpenObserve's integration with Prometheus, OpenTelemetry, and other tools makes it a robust solution for unified, scalable monitoring across your Kubernetes clusters.
To get started with OpenObserve, visit the website, check out the documentation, or sign up to explore how this powerful platform can simplify your monitoring needs.
Make your Kubernetes monitoring more efficient and scalable today!
Author:

The OpenObserve Team comprises dedicated professionals committed to revolutionizing system observability through their innovative platform, OpenObserve. Dedicated to streamlining data observation and system monitoring, offering high performance and cost-effective solutions for diverse use cases.