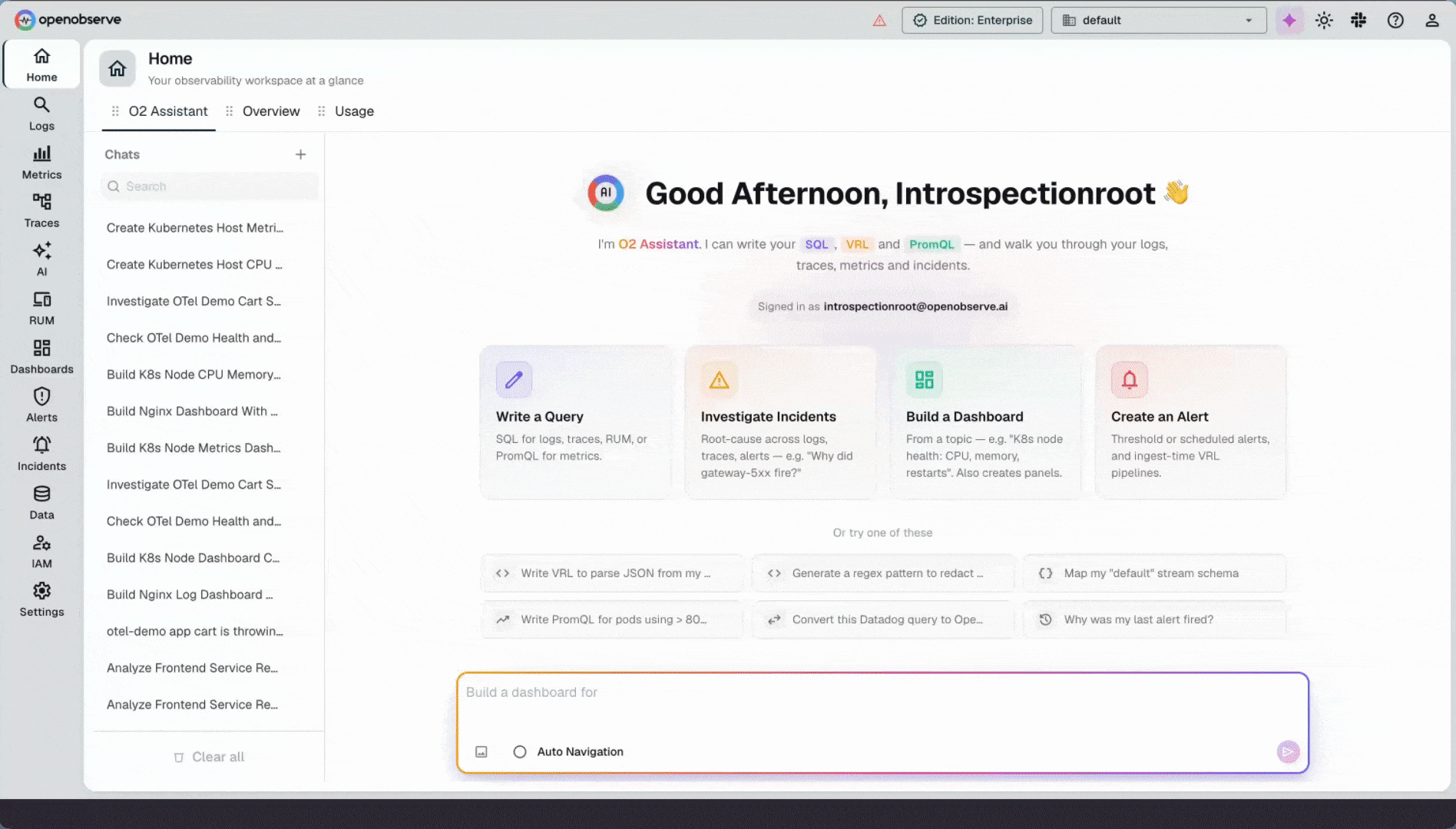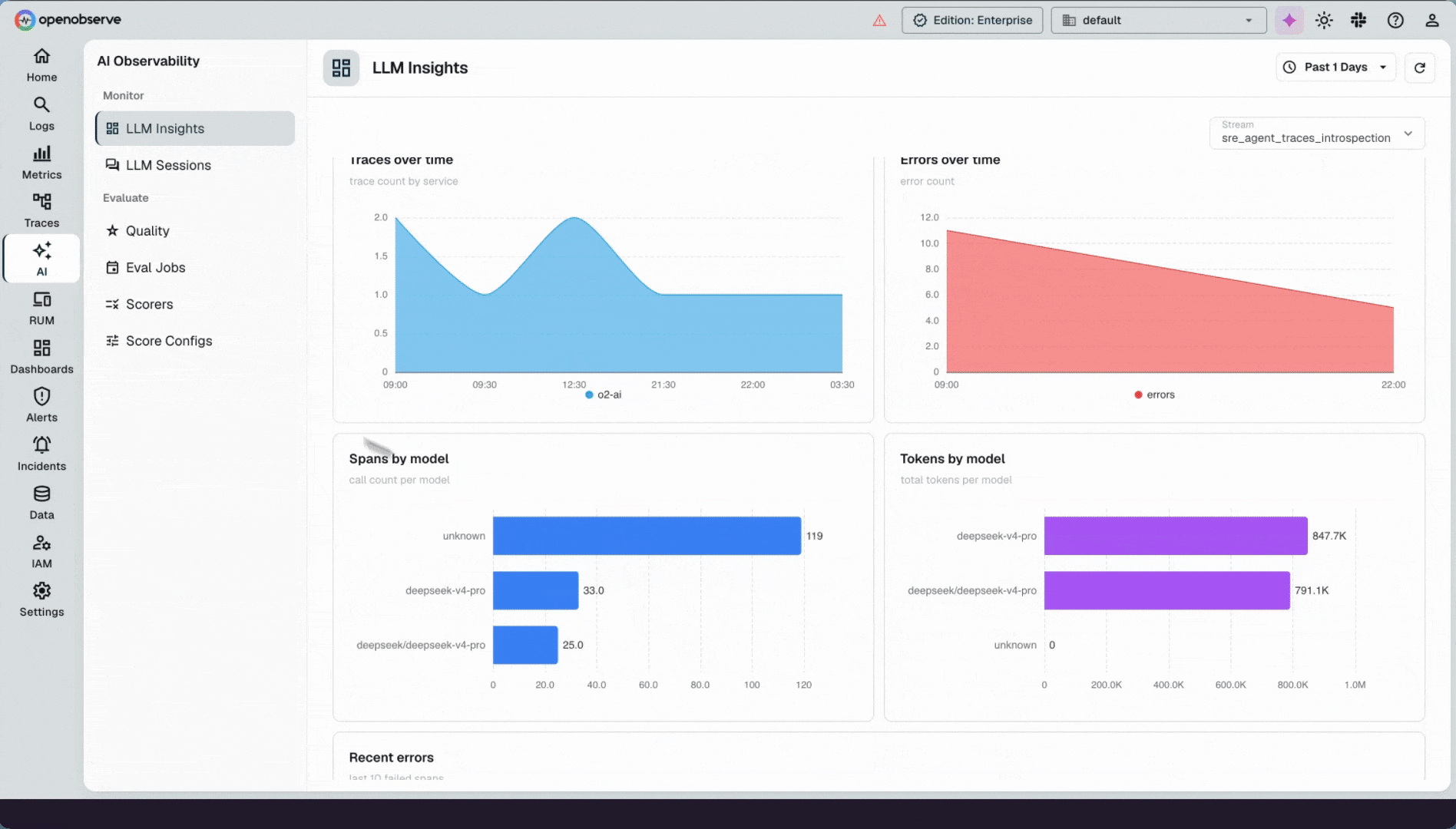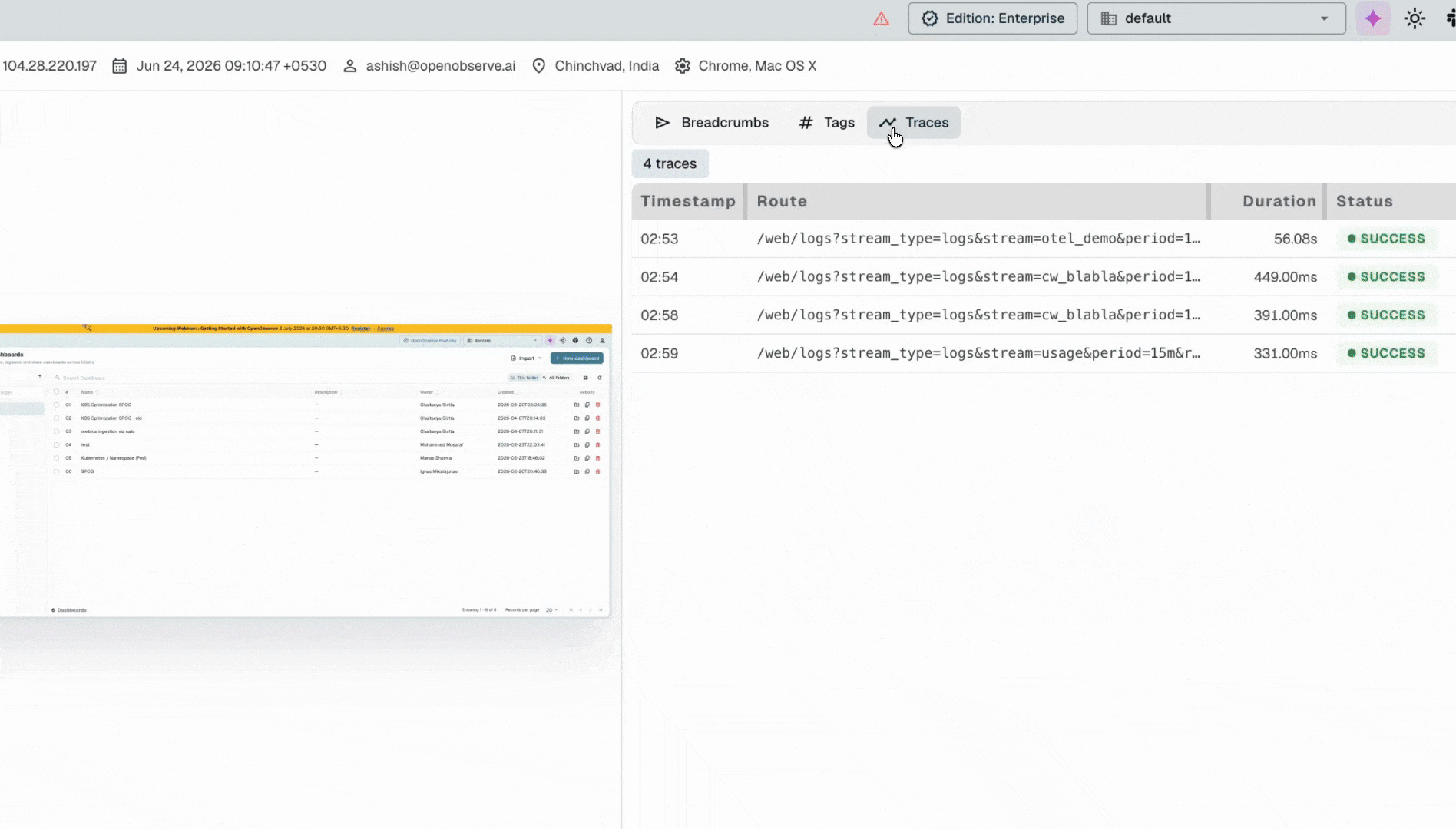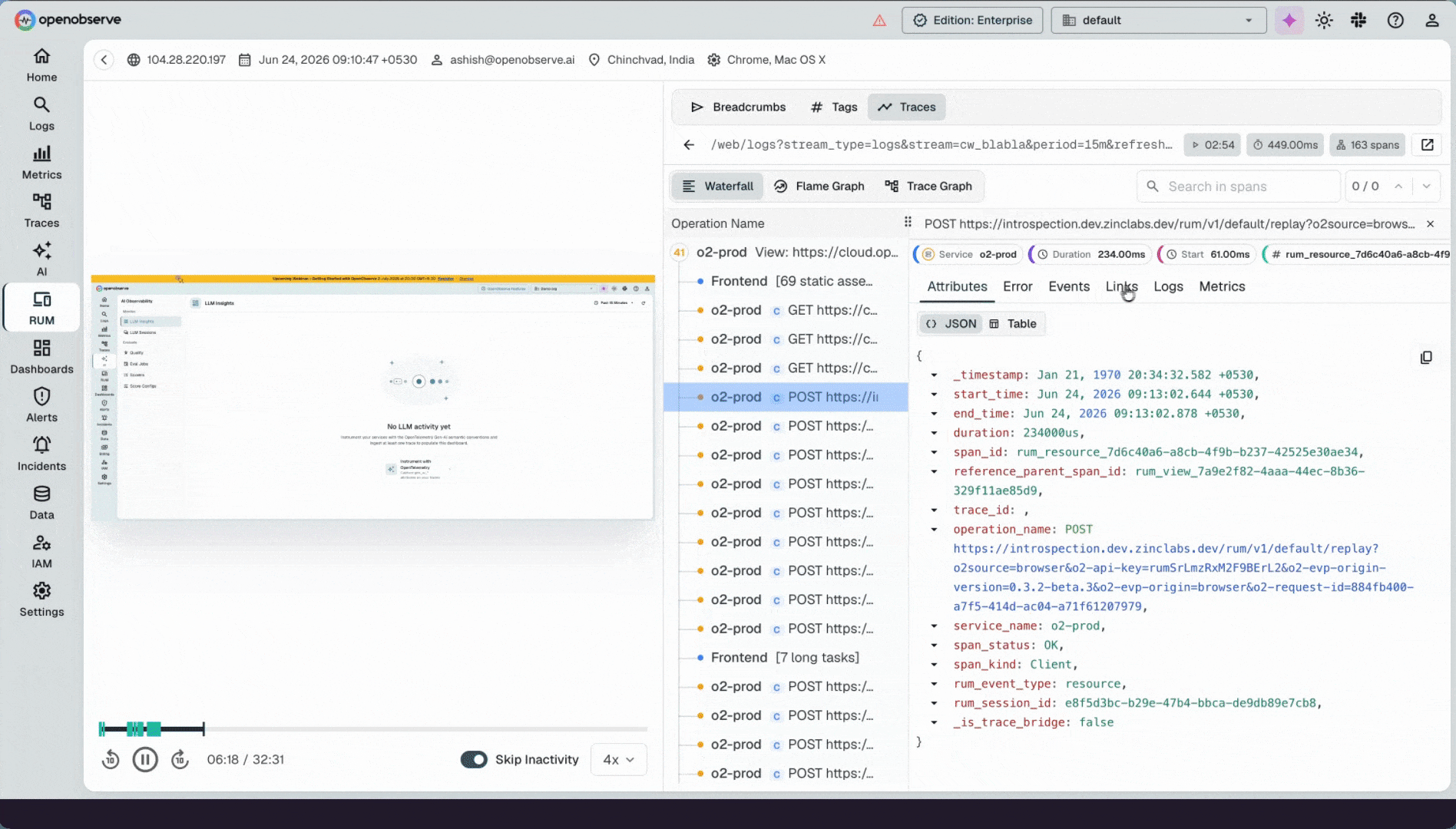
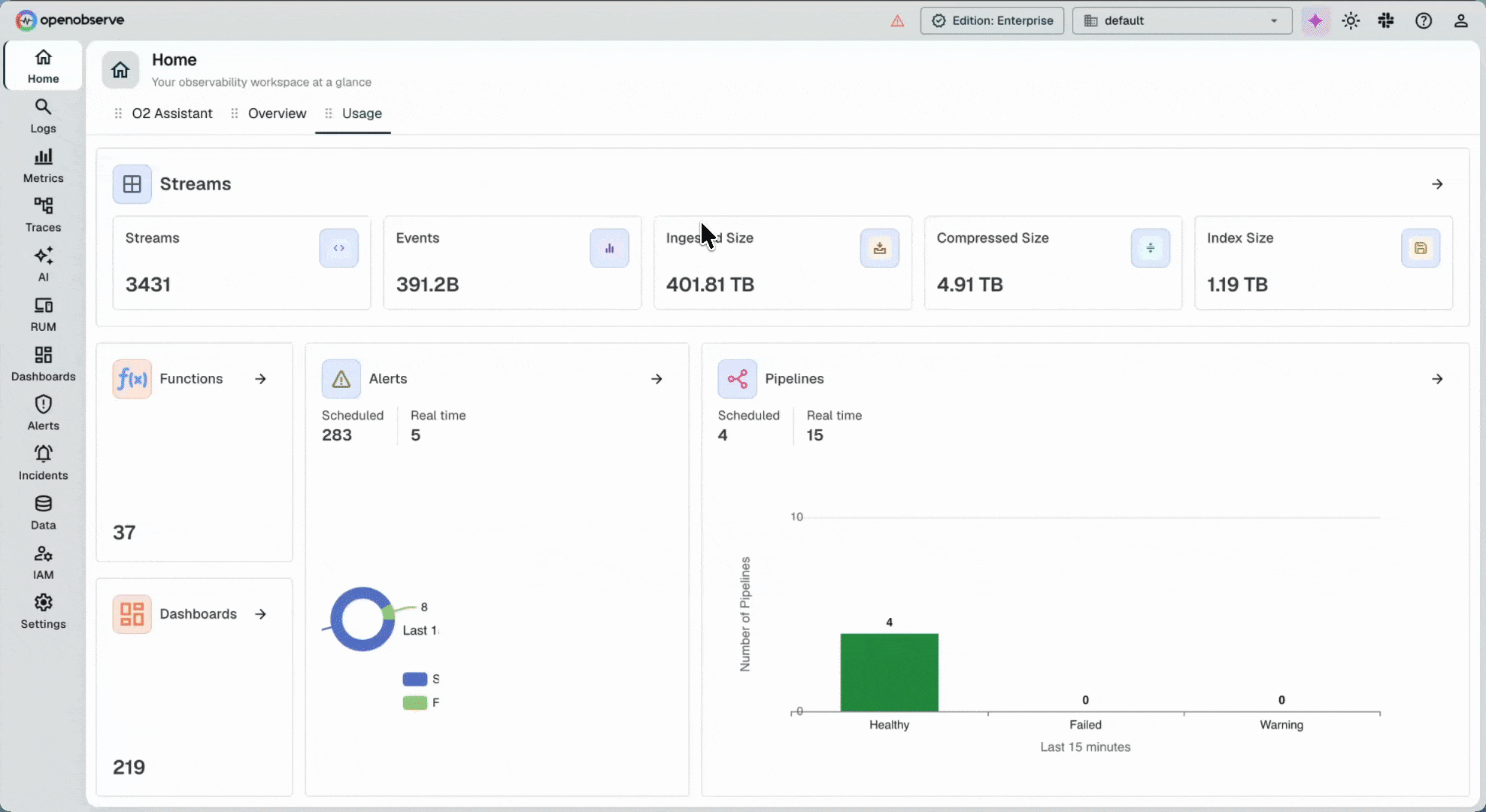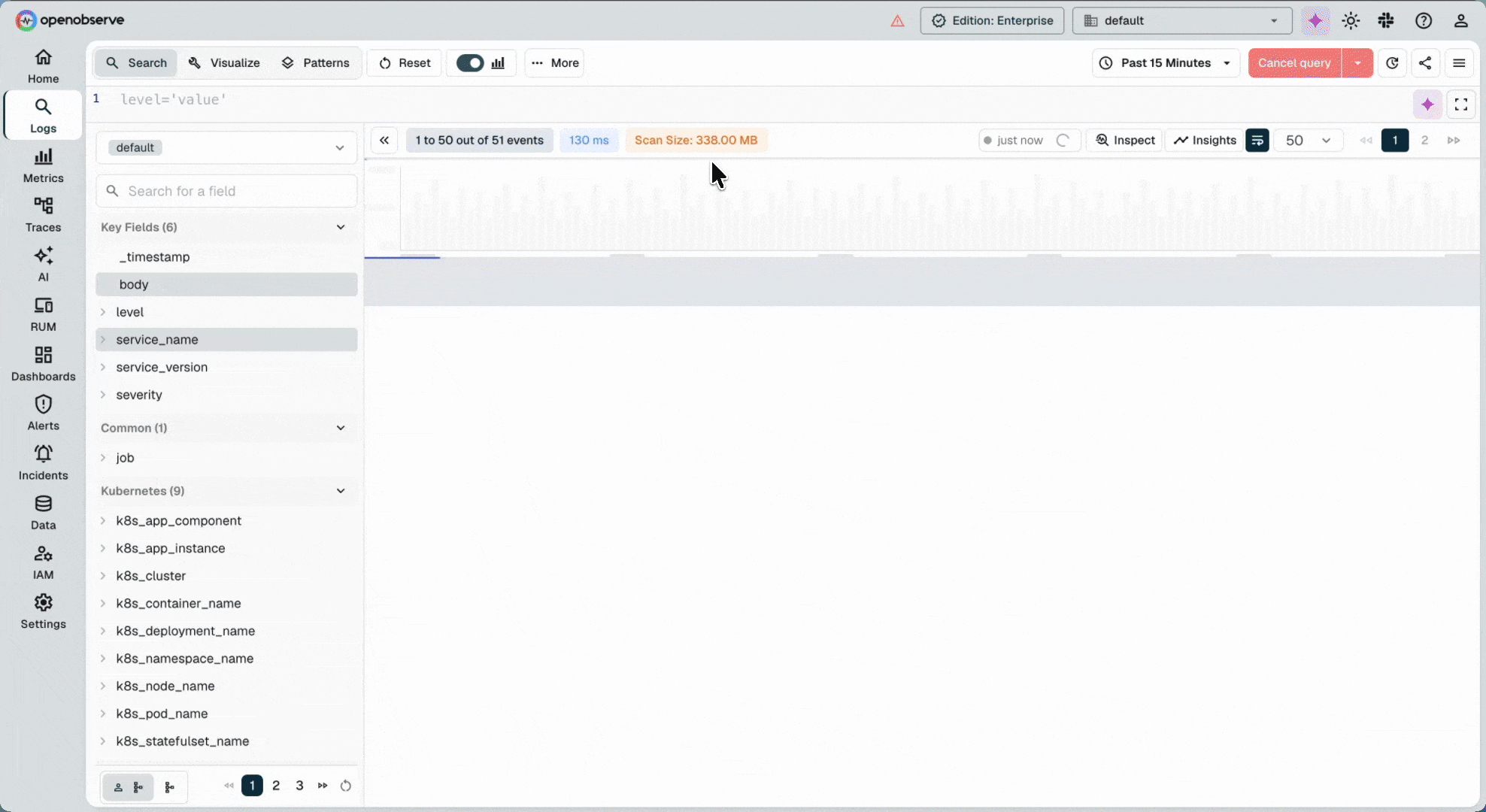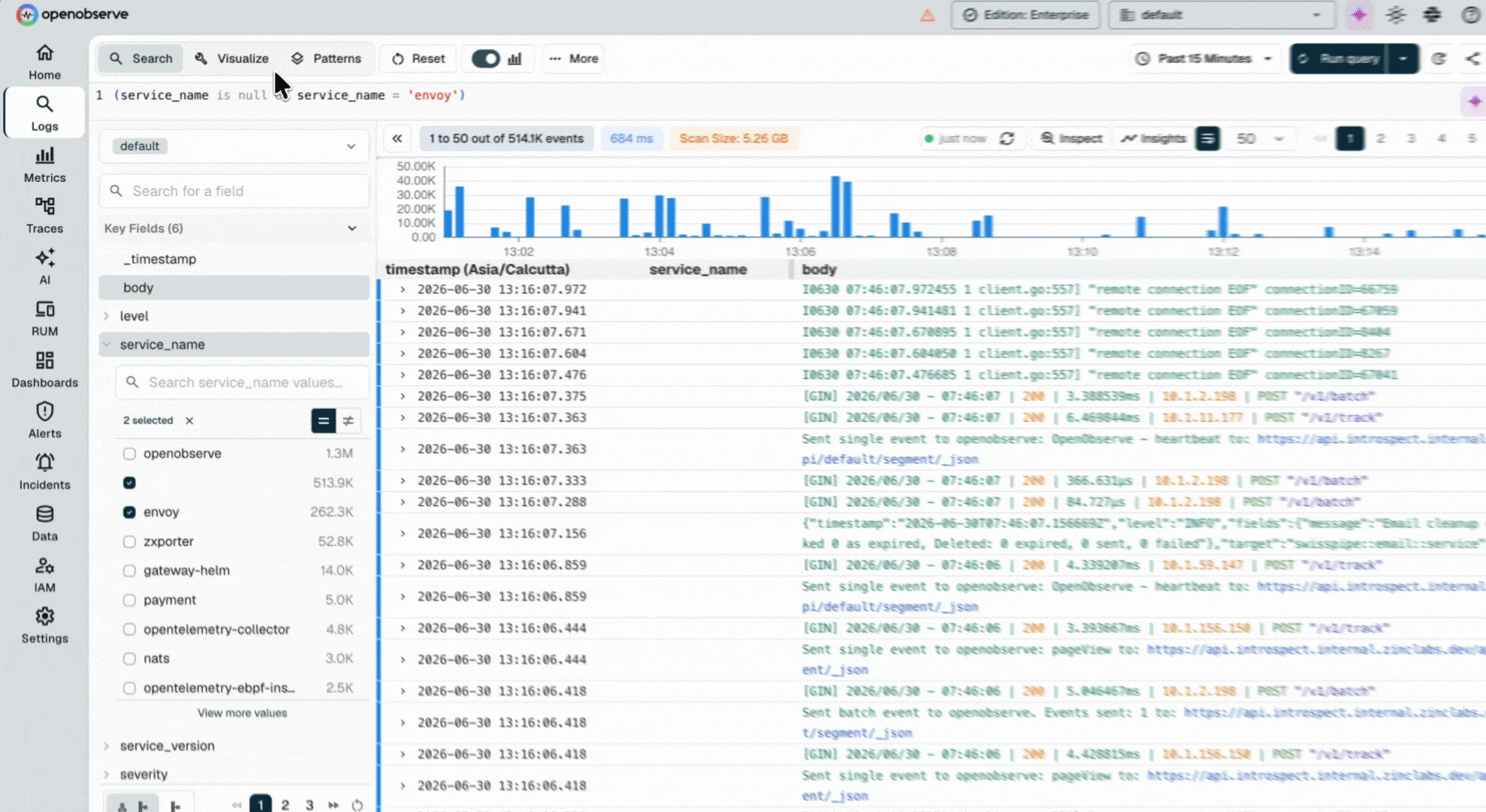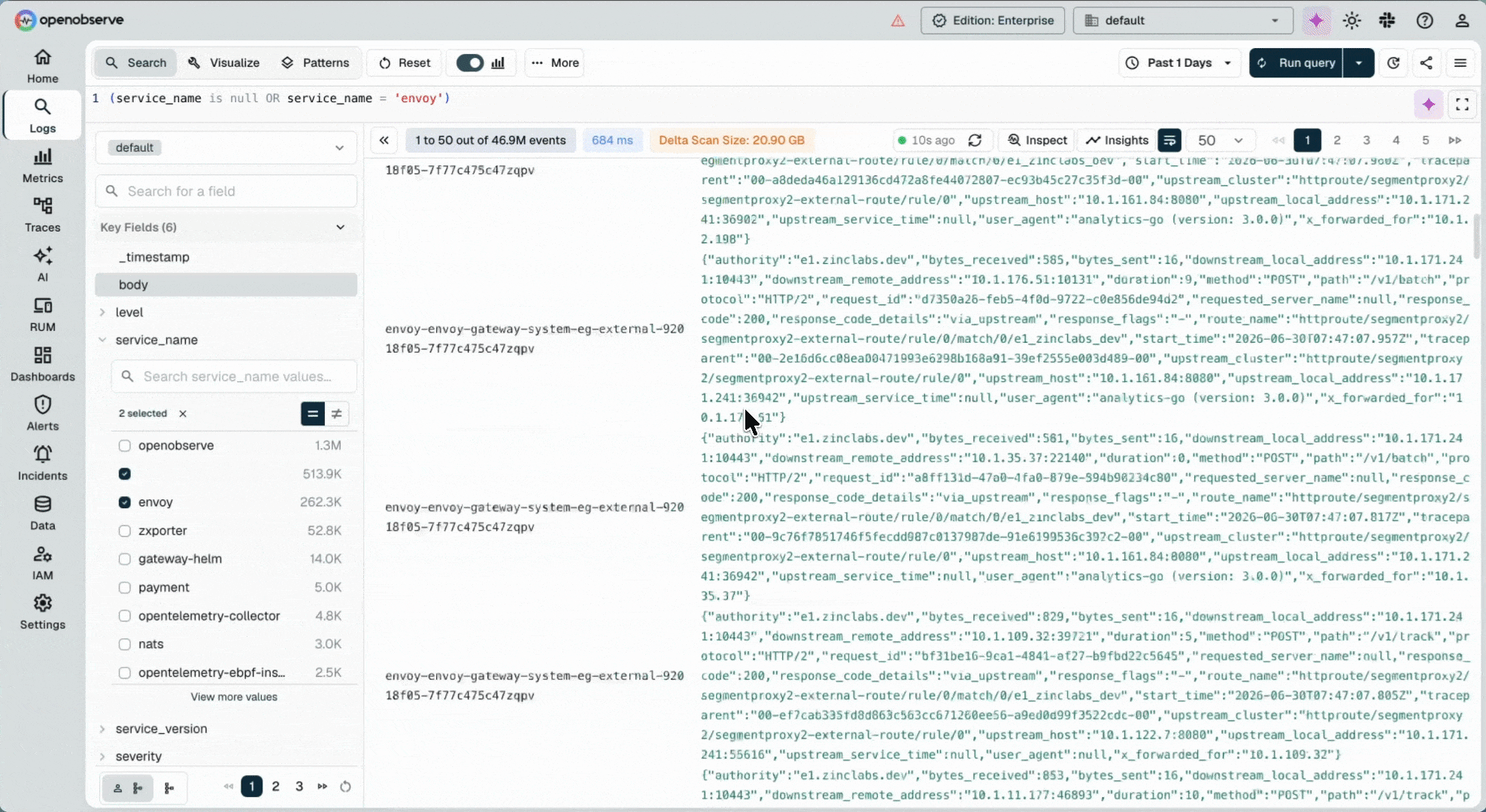
Open source, petabyte-scale observability
High-performance, unified observability for the AI era.
Why OpenObserve?
Explore the OpenObserve Platform
A modern, scalable architecture designed for high performance and low cost
It's in Our DNA: Open

Open Source
Our code is fully open source, allowing for community contributions, security audits, and complete control over your observability data.

AGPL-3.0 License
Active community of 20.5k+ GitHub stars

Transparent development, every commit public

Open Standards
Built on open standards and interoperable technologies so you're never locked into proprietary formats or vendor ecosystems.

OpenTelemetry Native

SQL and PromQL Support

Vendor-neutral approach, your data, your format
Built for efficiency, performance, and scale


140x lower storage cost when benchmarked against Elasticsearch.

OpenObserve provides high compression (~40x), columnar storage with Apache Parquet.

OpenObserve supports efficient long-term storage including local disk, S3, MinIO, GCS, and Azure Blob Storage.
"OpenObserve has proven to be a reliable and cost-effective solution built to address real-world challenges."




OpenObserve is written in Rust.

OpenObserve utilizes the DataFusion query engine to directly query Parquet files.

Internal query benchmarking of 1 petabyte of data returned in 2 seconds.
"[OpenObserve is] super fast, definitely very lightweight, and you can get started with an initial POC in two to three minutes to be honest."




Providing self-hosted logging for Fortune 100 Enterprises.

OpenObserve's stateless node architecture allows horizontal scaling without data complexity.

OpenObserve uses result and disk caching to keep the platform performant, even at scale.
"Today, I think we run our entire production logs through OpenObserve... it's been a phenomenal journey so far."


Frequently Asked Questions
Ready to get started?
Try OpenObserve today for more efficient and performant observability.