Getting Started with Open Source Tracing: Jaeger vs. Zipkin
Don’t forget to share!

In the ever-evolving world of microservices and complex applications, monitoring performance becomes an intricate puzzle. Traditional monitoring tools often struggle to capture the intricate flow of requests across multiple services.
Enter distributed tracing – a revolutionary approach that sheds light on the entire journey of a request as it traverses your microservices landscape. By tracing each request's path, you gain a holistic view of application health and identify bottlenecks with pinpoint accuracy.
But when it comes to implementing distributed tracing, two open-source powerhouses emerge: Jaeger and Zipkin. Choosing the right tool can make a significant difference in your monitoring efficiency. This blog will equip you with the knowledge to navigate the Jaeger vs. Zipkin debate and select the perfect fit for your needs.
Distributed tracing is crucial in microservices architecture because it helps track the flow of requests across multiple services. Without distributed tracing, it can be challenging to pinpoint the root cause of problems, leading to increased debugging time and potential downtime.
Jaeger and Zipkin are two popular open-source tools for distributed tracing:
Watch on Youtube: Distributed Tracing with Jaeger
Watch on Youtube: Introduction to Zipkin Distributed Tracing
Open-source tracing solutions like Jaeger and Zipkin are significant in modern software development because they provide a cost-effective and scalable way to implement distributed tracing.
Here are some key points to remember:
These points highlight the importance of open source tracing in microservices architecture and the significance of open-source tracing solutions like Jaeger and Zipkin.
Here are the fundamentals of distributed tracing, with a focus on Jaeger and Zipkin:
Distributed tracing is a technique used to track the flow of requests across multiple services in a distributed system. It is necessary because modern applications are often composed of many microservices that communicate with each other over a network. Distributed tracing helps by providing a way to track the entire journey of a request, from start to finish, across all the services it touches.
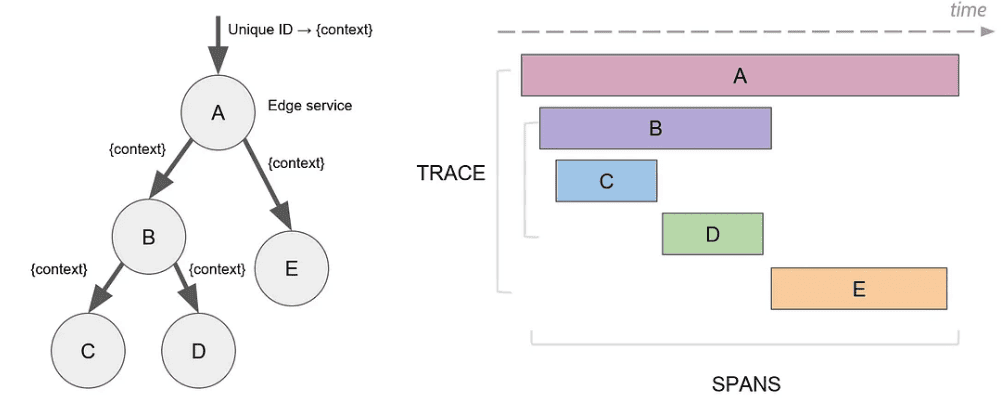
In distributed tracing, a trace represents the end-to-end journey of a request through a distributed system. A trace is composed of one or more spans, where each span represents a single operation within the trace. Spans have several key attributes, including:
Trace context is used to propagate information about a trace across service boundaries. It typically includes a unique identifier for the trace, as well as the identifiers of the current span and parent span.
Watch on YouTube: Distributed Tracing
Watch on YouTube: Everything You Wanted to Know About Distributed Tracing
Jaeger and Zipkin are two popular open-source distributed tracing systems that implement the concepts of spans and trace context.
Both Jaeger and Zipkin support various programming languages and frameworks, making it easy to integrate distributed tracing into your application.
OpenObserve steps in as a powerful backend and front end solution. You do not need to manage and integrate multiple tools for traces if you use OpenObserve.
Book a Free Demo with OpenObserve
By understanding these fundamentals of distributed tracing and how Jaeger and Zipkin implement them, you can gain valuable insights into the behavior of your distributed system and quickly identify and resolve issues that arise.
Instrumentation libraries are software libraries that help you instrument your applications to collect telemetry data. These libraries provide APIs and tools to collect metrics, logs, and traces from the application. They play a crucial role in enabling distributed tracing and monitoring.
Jaeger and Zipkin are two popular open-source distributed tracing systems. Both tools provide instrumentation libraries to collect telemetry data from applications. However, they differ in their approach to instrumentation:
Jaeger: Jaeger uses a client library (called an agent) that runs alongside the application and collects trace data. The agent sends the data to a collector, which stores it in a backend storage system.
Zipkin: Zipkin uses a similar approach, but it uses a tracer library that collects trace data and sends it to a collector. The collector stores the data in a backend storage system.
Both Jaeger and Zipkin provide support for various frameworks and libraries to integrate with their instrumentation libraries:
Jaeger: Jaeger supports integration with various frameworks and libraries, including Java, Python, Go, and Node.js. It also provides support for popular frameworks like Spring Boot and Django.
Zipkin: Zipkin supports integration with various frameworks and libraries, including Java, Python, Go, and Node.js. It also provides support for popular frameworks like Spring Boot and Django.
This highlights the role of instrumentation libraries in distributed tracing and monitoring, as well as the differences in approach between Jaeger and Zipkin.
Jaeger and Zipkin have different deployment strategies and preferred environments:
Jaeger: Jaeger is designed to be deployed in a distributed environment, with a focus on scalability and high availability. It supports deployment on Kubernetes, Docker, and other container orchestration platforms.
Zipkin: Zipkin is designed to be deployed in a more traditional environment, with a focus on ease of use and simplicity. It supports deployment on a single machine or in a distributed environment using Docker and Kubernetes.
Both Jaeger and Zipkin support various storage backend options, which have implications for scalability:
Jaeger: Jaeger supports storage backends like Cassandra, Elasticsearch, and MySQL. Cassandra is a popular choice for Jaeger due to its high scalability and fault tolerance.
Zipkin: Zipkin supports storage backends like MySQL, PostgreSQL, and Cassandra. MySQL is a popular choice for Zipkin due to its ease of use and scalability.
Monitoring, maintaining, and scaling the data store are crucial for both Jaeger and Zipkin:
Jaeger: Jaeger provides tools for monitoring and maintaining the data store, including a web-based interface for querying and visualizing data. It also supports scaling the data store using Cassandra's built-in scaling features.
Zipkin: Zipkin provides tools for monitoring and maintaining the data store, including a web-based interface for querying and visualizing data. It also supports scaling the data store using MySQL's built-in scaling features.
These differences in deployment strategies, storage backend options, and monitoring and maintenance tools highlight the unique strengths and weaknesses of each tool.

Jaeger and Zipkin have different UIs, each with its own strengths and weaknesses:
Jaeger: Jaeger's UI is designed for scalability and high availability. It provides a web-based interface for querying and visualizing trace data, with features like filtering, grouping, and aggregation. The UI is highly customizable, allowing users to tailor the layout and appearance to their needs.
Zipkin: Zipkin's UI is designed for ease of use and simplicity. It provides a web-based interface for querying and visualizing trace data, with features like filtering, grouping, and aggregation. The UI is less customizable than Jaeger's, but still provides a clear and intuitive view of the trace data.
Both Jaeger and Zipkin provide a range of functionality and visualization features for trace data analysis:
Jaeger: Jaeger provides advanced visualization features like heatmaps, scatter plots, and bar charts to help users understand the flow of requests across services. It also supports filtering, grouping, and aggregation of trace data.
Zipkin: Zipkin provides basic visualization features like line charts and bar charts to help users understand the flow of requests across services. It also supports filtering and grouping of trace data.
Both Jaeger and Zipkin provide the ability to perform trace data analysis through their UIs:
Jaeger: Jaeger's UI allows users to perform advanced trace data analysis, including filtering, grouping, and aggregation of trace data. It also supports visualization of trace data using heatmaps, scatter plots, and bar charts.
Zipkin: Zipkin's UI allows users to perform basic trace data analysis, including filtering and grouping of trace data. It also supports visualization of trace data using line charts and bar charts.
In summary, Jaeger's UI is designed for scalability and high availability, with advanced visualization features and customization options. Zipkin's UI is designed for ease of use and simplicity, with basic visualization features and less customization options.
Jaeger and Zipkin have different approaches to sampling in distributed tracing:
Jaeger: Jaeger uses adaptive sampling, which dynamically adjusts the sampling rate based on the volume of incoming data. This allows for more efficient data collection and reduces the risk of overwhelming the storage system.
Zipkin: Zipkin uses per-service sampling, which sets a fixed sampling rate for each service. This approach is simpler and easier to implement but may not be as efficient as Jaeger's adaptive sampling.
Jaeger and Zipkin have different data models:
Jaeger: Jaeger uses a more complex data model that includes concepts like spans, traces, and services. This allows for more detailed and nuanced analysis of the distributed tracing data.
Zipkin: Zipkin uses a simpler data model that focuses on tracing and spans. This approach is easier to implement but may not provide the same level of detail as Jaeger's data model.
Sampling is crucial in distributed tracing because it helps to reduce the volume of data collected and stored. This is important because:
Data Volume: Distributed tracing can generate a large volume of data, which can overwhelm storage systems and make analysis difficult.
Data Quality: Sampling helps to ensure that the data collected is representative of the overall system behavior and not just a small subset of the data.
Data Storage: Sampling reduces the amount of data stored, which can help to reduce storage costs and improve data retrieval times.
In summary, Jaeger's adaptive sampling and Zipkin's per-service sampling are two different approaches to sampling in distributed tracing. Jaeger's data model is more complex and nuanced, while Zipkin's data model is simpler and easier to implement. Sampling is important in distributed tracing because it helps to reduce the volume of data collected and stored, ensuring data quality and reducing storage costs.
Here is an analysis comparing the community involvement, support resources, and ecosystem for Jaeger and Zipkin.
Jaeger: Jaeger has a large and engaged community, with many contributors from various organizations. The community is active on GitHub, with frequent pull requests and issues being addressed. Jaeger also has a strong presence at conferences and meetups.
Zipkin: Zipkin also has a dedicated community, with contributors from various organizations. The community is active on GitHub, with regular pull requests and issues being addressed. Zipkin has a strong presence in the microservices community.
Jaeger: Jaeger has detailed documentation covering installation, configuration, and usage. The documentation is available in English and is well-organized and easy to navigate. Jaeger also provides support through a mailing list and Slack channel.
Zipkin: Zipkin also has comprehensive documentation covering installation, configuration, and usage. The documentation is available in English and is well-structured. Zipkin provides support through a mailing list and Gitter channel.
Jaeger: Jaeger integrates with various data sources, including Kubernetes, Prometheus, and Elasticsearch. Jaeger also has extensions for popular frameworks like Spring Boot and Go. There are many third-party tools available for visualizing and analyzing Jaeger data.
Zipkin: Zipkin integrates with various data sources, including Kafka, RabbitMQ, and Cassandra. Zipkin also has extensions for popular frameworks like Spring Boot and Rails. There are fewer third-party tools available for Zipkin compared to Jaeger.
In summary, both Jaeger and Zipkin have strong open-source communities and provide extensive support resources and documentation. However, Jaeger has a larger ecosystem with more integrations, extensions, and third-party tools compared to Zipkin.
When comparing Jaeger and Zipkin, the key evaluation criteria to consider are:
| Criteria | Jaeger | Zipkin |
| Language Support | Supports a wider range of programming languages, including Java, Go, Python, Node.js, and more | Good support for Java, but more limited support for other languages |
| Scalability | Designed for high-scale, distributed environments and can handle large volumes of tracing data | More suitable for smaller-scale deployments and may struggle with very high data volumes |
| Deployment Ease | Better support for containerized and Kubernetes-based deployments | Simpler to deploy, especially in more traditional environments |
| Community Support | Larger and more active community, with more contributors and resources available | Strong community, but relatively smaller compared to Jaeger |
Book a Free Demo with OpenObserve
Recommendation: Jaeger is the better choice in this scenario due to its superior scalability, support for distributed environments, and wider language support.
Recommendation: Zipkin may be the more suitable option here, as it is simpler to deploy and manage, and its feature set may be sufficient for the needs of a smaller-scale application.
Recommendation: Jaeger is the better choice in this scenario, as it provides broader language support and can handle the complexity of a heterogeneous environment more effectively.
When choosing between Jaeger and Zipkin, it's important to consider your overall requirements, including:
Evaluate the resources and expertise available within your organization to handle the deployment and ongoing maintenance of the chosen tracing solution.
Assess how well the tracing solution integrates with your existing monitoring, logging, and observability tools.
Ensure that the tracing solution can seamlessly fit into your overall observability strategy.
Consider the long-term growth and evolution of your application landscape, and choose a tracing solution that can scale and adapt accordingly.
By carefully evaluating these criteria and your specific use case requirements, you can make an informed decision on whether Jaeger or Zipkin is the better fit for your organization.
Watch on YouTube: Distributed Tracing With Jaeger & Zipkin
Book a Free Demo with OpenObserve
The intricate world of distributed tracing can be daunting, but with the right tools, you can gain unparalleled visibility into your application's performance. This exploration of Jaeger and Zipkin, two leading open-source heavyweights, has equipped you to make an informed decision.
Remember, the ideal choice hinges on your specific needs:
Regardless of your choice between Jaeger and Zipkin, OpenObserve steps in as a powerful backend solution. We seamlessly integrate with both tools, providing advanced data storage, visualization, and analysis capabilities. With OpenObserve, you can unlock the full potential of your chosen tracing solution, gaining a deeper understanding of your application's performance and empowering data-driven decision-making.
Book a Free Demo with OpenObserve
So, take the first step towards a more unified and efficient observability strategy – embrace OpenTelemetry Protocol and its powerful potential.
About Us | Open Source Observability Platform
The future of observability is bright, and OpenObserve is here to guide you. Embrace open-source tracing and unlock a world of insights into your application's health.


