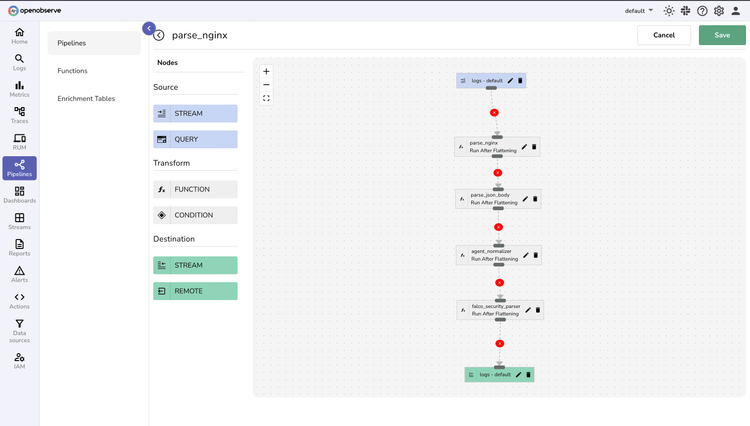
Observability Pipelines
Transform, enrich, redact, reduce, and parse your observability data with real-time and scheduled pipelines.
Protect Sensitive Data
Strengthen your security posture by automatically redacting and transforming sensitive data
Accelerate Data Insights
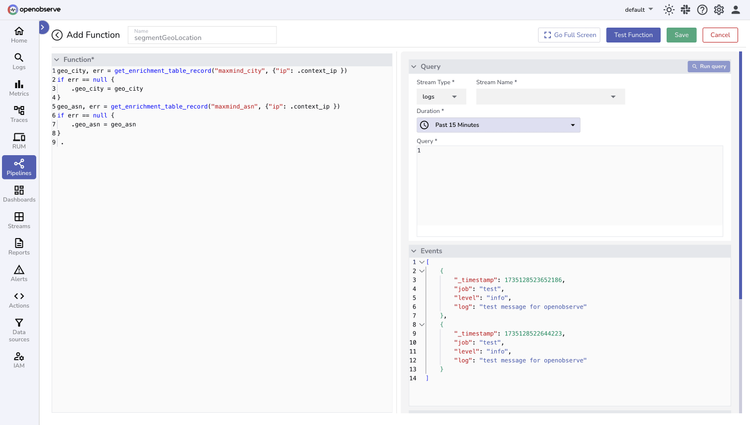
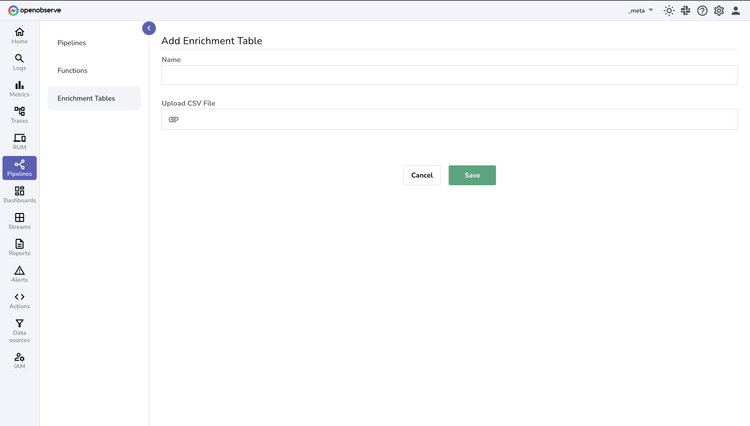
Unlock faster decision-making with real-time data parsing and enrichment using VRL functions and enrichment tables
Improve Data Quality
Make data more valuable and actionable by pre-processing and enriching data
OpenObserve Observability Pipelines
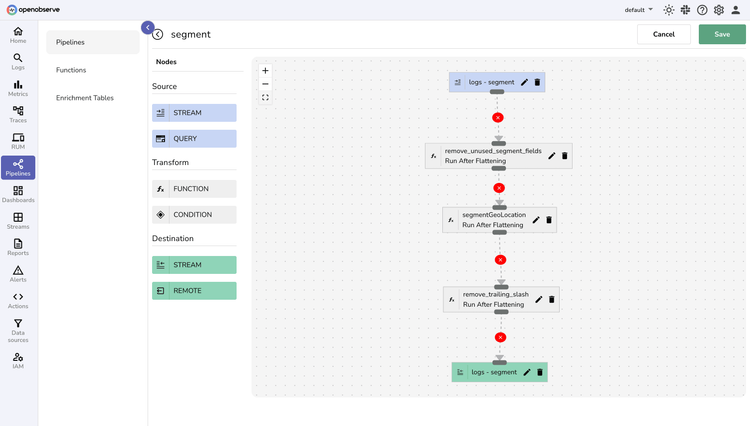
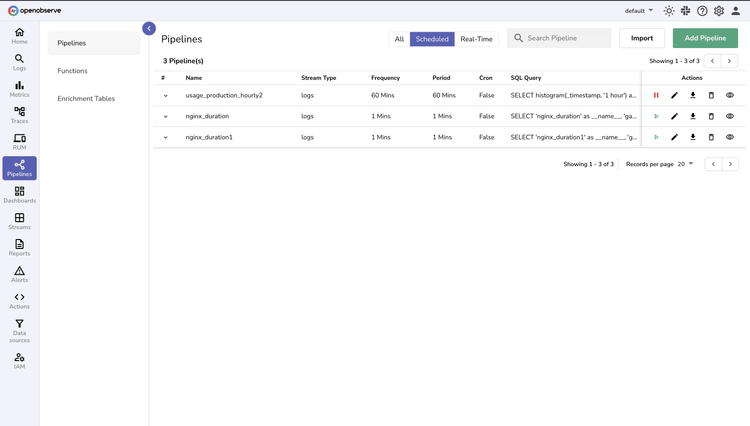
Pipeline Types
Real-time
Transform data the instant it arrives. Parse, filter, and enrich streams on-the-fly—turning raw data into immediate insights.
Scheduled
Orchestrate batch transformations precisely when you need them. Aggregate massive datasets, convert logs to actionable metrics, and process data on your timeline.
Observability Pipelines FAQs
Latest From Our Blogs














Ready to get started?
Try OpenObserve today for more efficient and performant observability.