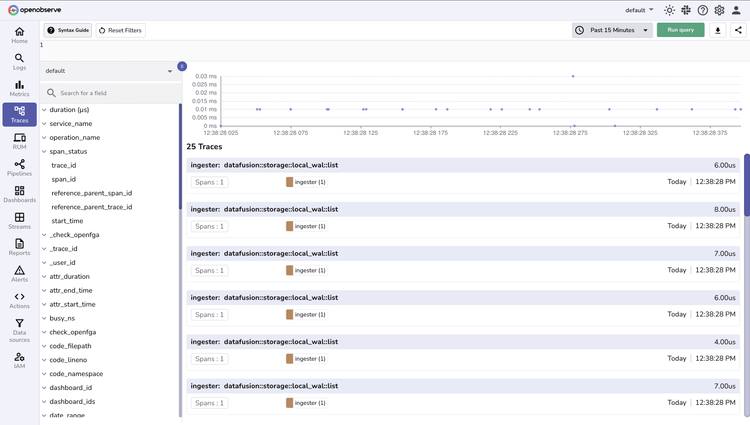
Traces
Gain end-to-end visibility into your distributed systems, powered by OpenTelemetry.
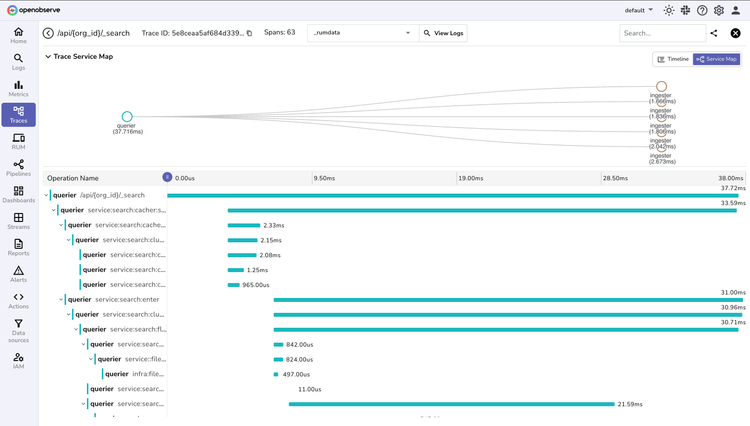
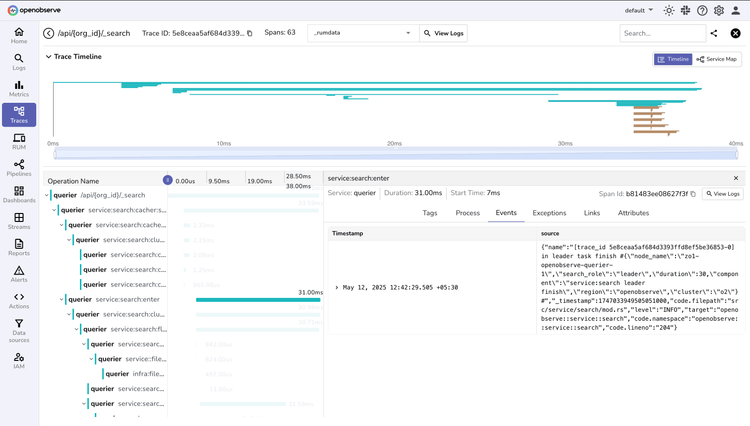
Correlated Telemetry
Visualize and troubleshoot metrics, logs, and traces in a single pane of glass
Significantly Efficient
70% lower storage requirements for traces compared to Elasticsearch
OTel-Native Traces
Standardized collection with zero vendor lock-in
OpenObserve Traces
Trace Collection
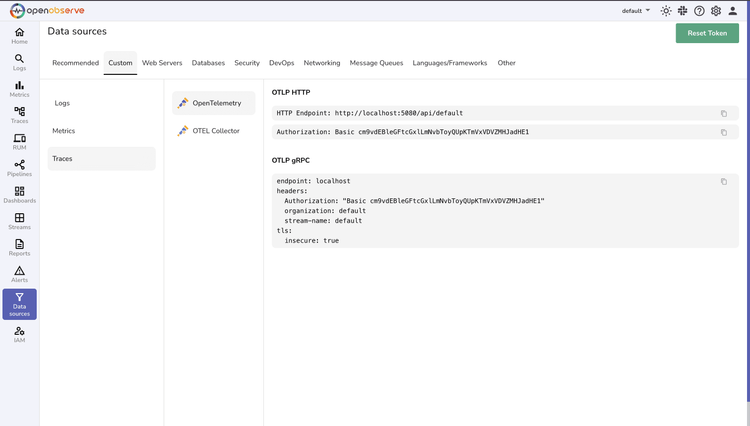
OpenTelemetry Integration
Collect traces through native OTLP (OpenTelemetry Protocol). Instrument applications once and export traces directly to OpenObserve—no vendor lock-in.
Auto-instrumentation
Capture distributed traces using zero-code auto-instrumentation configured by the OpenObserve collector.
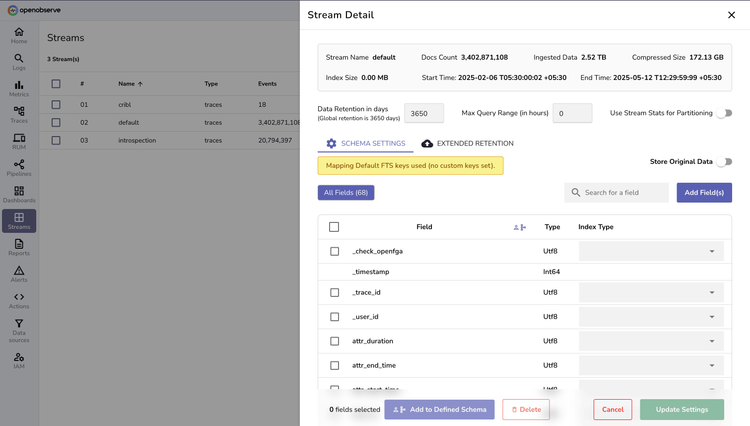
Traces FAQs
Latest From Our Blogs


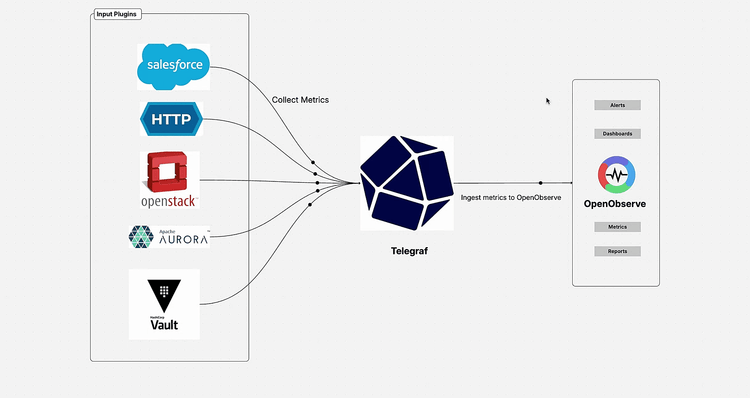



Ready to get started?
Try OpenObserve today for more efficient and performant observability.