AI Anomaly Detection: Catch Issues Traditional Alerts Miss

Manas Sharma
April 03, 2026
20 min read
Don’t forget to share!
Try OpenObserve Cloud today for more efficient and performant observability.

Your database slows at 2:47 AM. By 3:15 AM, it's a full outage. The postmortem reveals the signal was there—disk I/O started behaving unusually around 1:00 AM—but no alert fired because there's no effective way to threshold "unusual I/O."
This is the gap ai anomaly detection fills. Instead of alerting when a metric crosses a predefined threshold (X > Y), ai anomaly detection alerts when a metric behaves differently than it historically has. Modern ai anomaly detection systems use machine learning to learn normal patterns from your data, then flag statistical deviations that indicate potential issues.
For DevOps and SRE teams managing complex distributed systems, ai anomaly detection has become essential infrastructure. Traditional threshold-based alerts miss gradual degradations, can't adapt to seasonal patterns, and generate alert fatigue through false positives. AI anomaly detection solves these problems by modeling expected behavior and surfacing truly unusual events.
This guide explores how ai anomaly detection works in observability contexts, the algorithms powering it, and how to implement it effectively for metrics, logs, and traces.
AI anomaly detection is a core component of modern AIOps platforms, enabling AI-powered incident management that reduces mean time to resolution by providing early warning signals before threshold breaches occur.
AI anomaly detection is the application of machine learning algorithms to automatically identify unusual patterns in time-series data, logs, and distributed traces. Unlike rule-based alerting that requires engineers to define what "bad" looks like upfront, AI anomaly detection learns what "normal" looks like from historical data and flags deviations.
Traditional monitoring asks: "Is CPU above 80%?" AI anomaly detection asks: "Is CPU behaving differently than it ever has?"
This shift matters because:
Historical Data (7-30 days)
↓
Training Phase (learn normal patterns)
↓
Trained Model (encodes expected behavior)
↓
New Data Point Arrives
↓
Anomaly Score Calculation (how unusual is this?)
↓
Score > Threshold? → Alert
The model continuously learns from new data, adapting to system changes while maintaining the ability to detect true anomalies.
Most alerting systems rely on static thresholds: "Alert when error rate > 100/min" or "Alert when latency > 500ms." This approach fails in three critical ways:
A static threshold doesn't know that:
Finding the "right" threshold is impossible:
Your system evolves:
Static thresholds don't adapt—they require constant manual tuning or become obsolete.
Multiple algorithmic approaches power AI anomaly detection, each with different trade-offs for observability use cases.
Approach: Calculate statistical properties (mean, standard deviation, percentiles) from historical data and flag points that deviate significantly.
Common Techniques:
Z-Score (Standard Score)
z = (x - μ) / σ
Where:
x = current value
μ = historical mean
σ = historical standard deviation
Flag if |z| > 3 (point is 3+ standard deviations from mean)
Pros: Simple, fast, interpretable Cons: Assumes normal distribution, can't handle seasonality, sensitive to outliers
Interquartile Range (IQR)
IQR = Q3 - Q1 (75th percentile - 25th percentile)
Flag if: x < Q1 - 1.5×IQR OR x > Q3 + 1.5×IQR
Pros: Robust to outliers, no distribution assumptions Cons: Still can't handle seasonality or trends
When to use: Quick detection on stable metrics without strong patterns (e.g., cache hit rates, connection pool sizes)
Approach: Build predictive models that forecast expected values with confidence intervals. Flag points that fall outside the predicted range.
Prophet (Facebook's Algorithm)
Decomposes time series into:
y(t) = trend(t) + seasonality(t) + holidays(t) + error(t)
Pros: Handles multiple seasonalities automatically, interpretable components, robust to missing data Cons: Requires longer training windows (weeks), computationally expensive, batch-oriented
ARIMA (AutoRegressive Integrated Moving Average)
Statistical model using past values and past errors to predict future:
ARIMA(p, d, q)
p = autoregressive terms (use past p values)
d = differencing to remove trends
q = moving average terms (use past q errors)
Pros: Strong theoretical foundation, handles trends and seasonality Cons: Requires stationary data, parameter tuning complex, doesn't scale to high-cardinality
When to use: Metrics with strong daily/weekly patterns (API request rates, user activity), business metrics with known seasonality
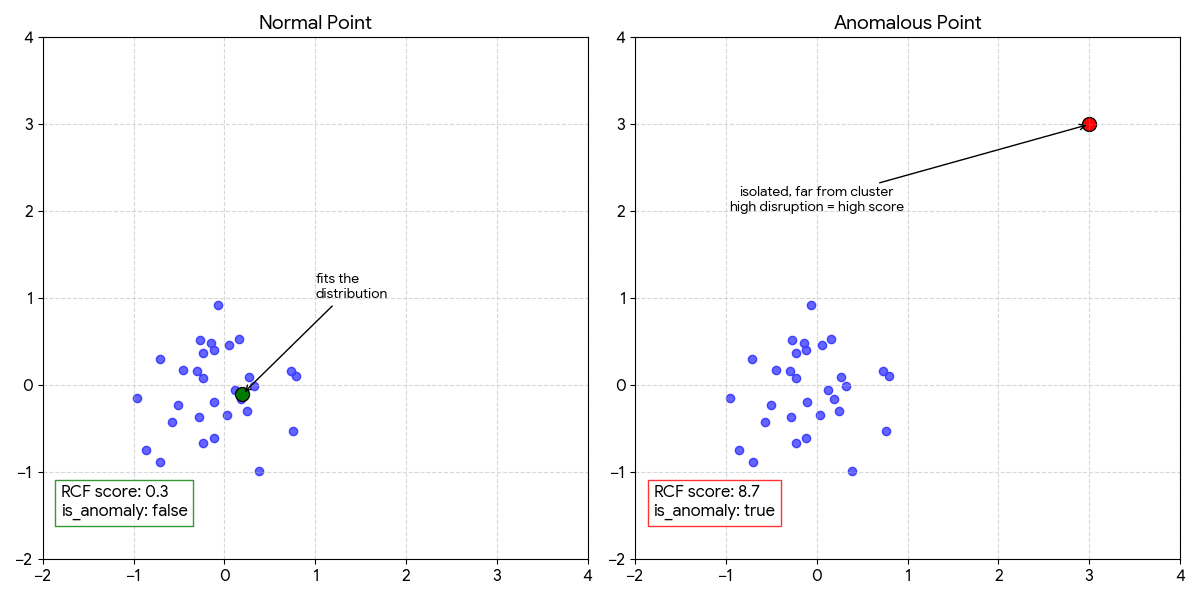
Approach: Build decision trees that isolate anomalies through recursive partitioning. Anomalies are easier to isolate (require fewer splits) than normal points.
Isolation Forest
Creates random binary trees by:
Anomaly Score = 2^(-average_path_length / normalization_factor)
High score = short path = anomaly
Low score = long path = normal
Pros: Unsupervised (no labels needed), handles high dimensions, fast inference Cons: Batch-oriented (not streaming), sensitive to feature scaling
Random Cut Forest (Amazon's RCF)
Streaming version of Isolation Forest optimized for time-series:
Shingle Size = 8 example:
Data: [42, 45, 43, 44, 46, 44, 45, 91]
↑
Score this value in context of 7 preceding values
Sudden jump after flat baseline → high score
Pros: Streaming-native, handles seasonality via shingling, explainable scores, no labeled data Cons: More complex to tune, requires understanding shingle size/threshold trade-offs
When to use: High-velocity streaming data (logs, metrics from Kubernetes), time-series where context matters (gradual drift detection)
LSTM (Long Short-Term Memory) Autoencoders
Neural networks that:
Training: Normal data → minimize reconstruction error
Detection: New data → large reconstruction error = anomaly
Pros: Learns complex patterns, handles multivariate data, no explicit feature engineering Cons: Requires large datasets, black-box (not explainable), expensive training, GPU often needed
When to use: Complex multivariate signals (correlated metrics across services), sufficient training data (months), tolerance for higher operational cost
AI anomaly detection applies differently across metrics, logs, and traces—each requiring distinct approaches.
What: Numerical measurements collected at regular intervals (CPU, memory, request rates, latency percentiles)
Detection Approach: Time-series forecasting or streaming tree models
Common Anomaly Patterns:
1. Point Anomalies (Spikes/Dips)
2. Contextual Anomalies
3. Trend Anomalies (Drift)
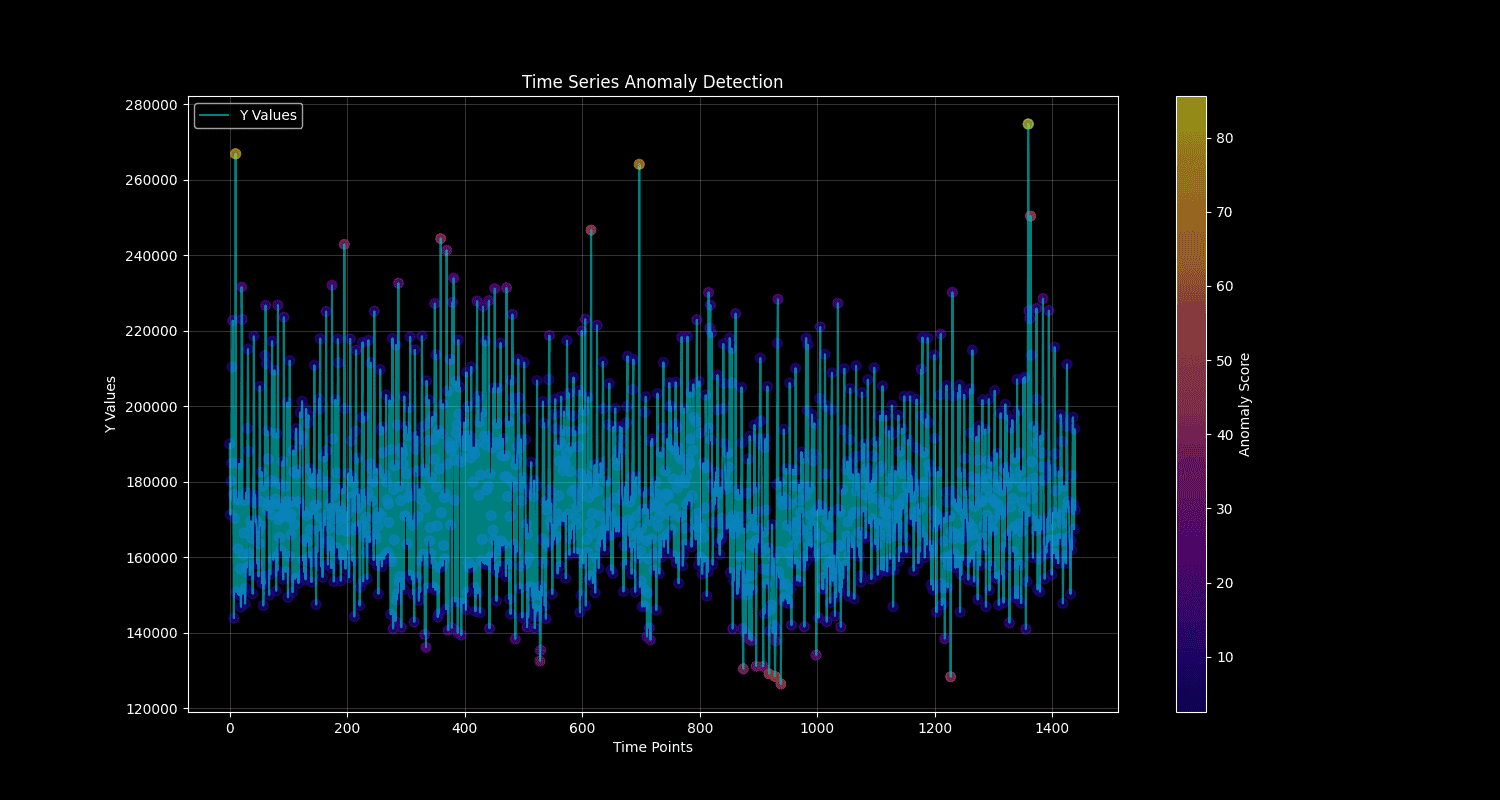
Example: API Latency Spike Detection
Metric: api_latency_p99_ms
Historical baseline: 45ms ± 8ms (weekday afternoons)
New observation: 180ms
Z-score: (180 - 45) / 8 = 16.8 → Strong anomaly
RCF score: 12.4 (threshold: 97th percentile ≈ score 3.0) → Alert
What: Unstructured or semi-structured text events (application logs, system logs, audit logs)
Detection Approach: Text clustering + frequency analysis
Common Techniques:
1. Log Template Extraction
"User 12345 logged in from 192.168.1.100" → "User <ID> logged in from <IP>"2. Clustering-Based Anomaly Detection
3. Frequency-Based Detection
Example: New Error Pattern
Historical: 0 occurrences of "OutOfMemoryError: GC overhead limit exceeded"
New: 47 occurrences in last 5 minutes
Simple frequency: 47 vs baseline 0 → anomaly
ML clustering: Message doesn't match any known cluster → anomaly
What: End-to-end request flows through distributed services (spans with timing, dependencies, errors)
Detection Approach: Span duration analysis + dependency graph anomalies
Common Patterns:
1. Slow Spans
2. New Error Paths
payment-service → bank-api span starts returning 503s3. Topology Anomalies
checkout-service suddenly calling legacy-billing-api not seen in 6 monthsExample: Database Degradation via Traces
Span: inventory-service → postgres (SELECT query)
Historical p95 duration: 35ms
Recent 10 minutes p95: 250ms
RCF anomaly score: 8.7 → Flag as anomaly
Alert: "Database query latency anomaly detected 20 minutes before error rate spike"
| Dimension | Static Thresholds | AI Anomaly Detection |
|---|---|---|
| Setup effort | 5 minutes (set threshold) | 3-7 days training + tuning |
| Adaptation | Manual updates required | Automatic with retraining |
| False positive rate | Higher in dynamic environments | Lower with proper tuning |
| Seasonal handling | Requires multiple thresholds | Learned automatically |
| Gradual drift detection | Misses completely | Catches via shingle/context |
| Unknown failure modes | Can't detect | Can flag unusual patterns |
| Explainability | Perfect ("CPU > 80%") | Moderate (score + deviation %) |
| Computational cost | Negligible | Model training + inference |
Use static thresholds when:
Use AI anomaly detection when:
Use both together:
Scenario: Detecting unusual pod restart rates before they cascade into outages
Implementation:
Metric: pod_restarts_per_5min (by namespace, deployment)
Algorithm: Random Cut Forest
Training window: 14 days
Threshold: 97th percentile
Normal baseline: 0-2 restarts per 5 min
Anomaly trigger: 8 restarts in 5 min at 3 AM
Outcome: Alert fires 15 minutes before memory leak causes cascading pod failures across deployment
Scenario: Gradual database slowdown that never crosses absolute threshold
Implementation:
Metric: api_latency_p99_ms
Algorithm: Prophet (handles daily patterns)
Training window: 30 days
Confidence interval: 95%
Normal: 45ms ± 12ms (2 PM weekday)
Detection: Latency drifting 2ms/hour over 6 hours
At hour 6: 57ms (still under 100ms threshold, but 3σ from forecast)
Outcome: DBA investigates, finds query plan regression from index change 6 hours prior—reverts before customer impact
Scenario: New error pattern appearing after deployment
Implementation:
Data: Application error logs
Algorithm: Log clustering + frequency anomaly
Training: 7 days of log templates
New pattern: "NullPointerException in PaymentProcessor.validateCard()"
Historical frequency: 0 occurrences
New frequency: 127 in 10 minutes
Outcome: Rollback initiated automatically, deployment rolled back before affecting 5% of users
Scenario: Detecting runaway LLM API costs from prompt injection or inefficient calls
Implementation:
Metric: llm_tokens_used_per_hour (by service, model)
Algorithm: IQR (handles cost spikes)
Training window: 21 days
Normal: 50K-80K tokens/hour (GPT-4)
Anomaly: 450K tokens/hour at 2 AM
Outcome: Alert fires, investigation reveals infinite retry loop in summarization service, circuit breaker engaged
Scenario: Detecting compromised account via unusual access patterns
Implementation:
Metric: api_calls_per_user_per_hour
Algorithm: Isolation Forest (multivariate)
Features: [call_count, unique_endpoints, failed_auth_attempts, geographic_distance]
Normal user: 20-40 calls/hour, 3-5 endpoints, 0 failed auth, same region
Anomalous: 800 calls/hour, 45 endpoints, 12 failed auth, new country
Outcome: Account flagged, MFA challenge triggered, investigation reveals credential stuffing attack
OpenObserve ships with a production-ready anomaly detection engine powered by Random Cut Forest (RCF)—the same algorithm Amazon uses in Kinesis Data Analytics.
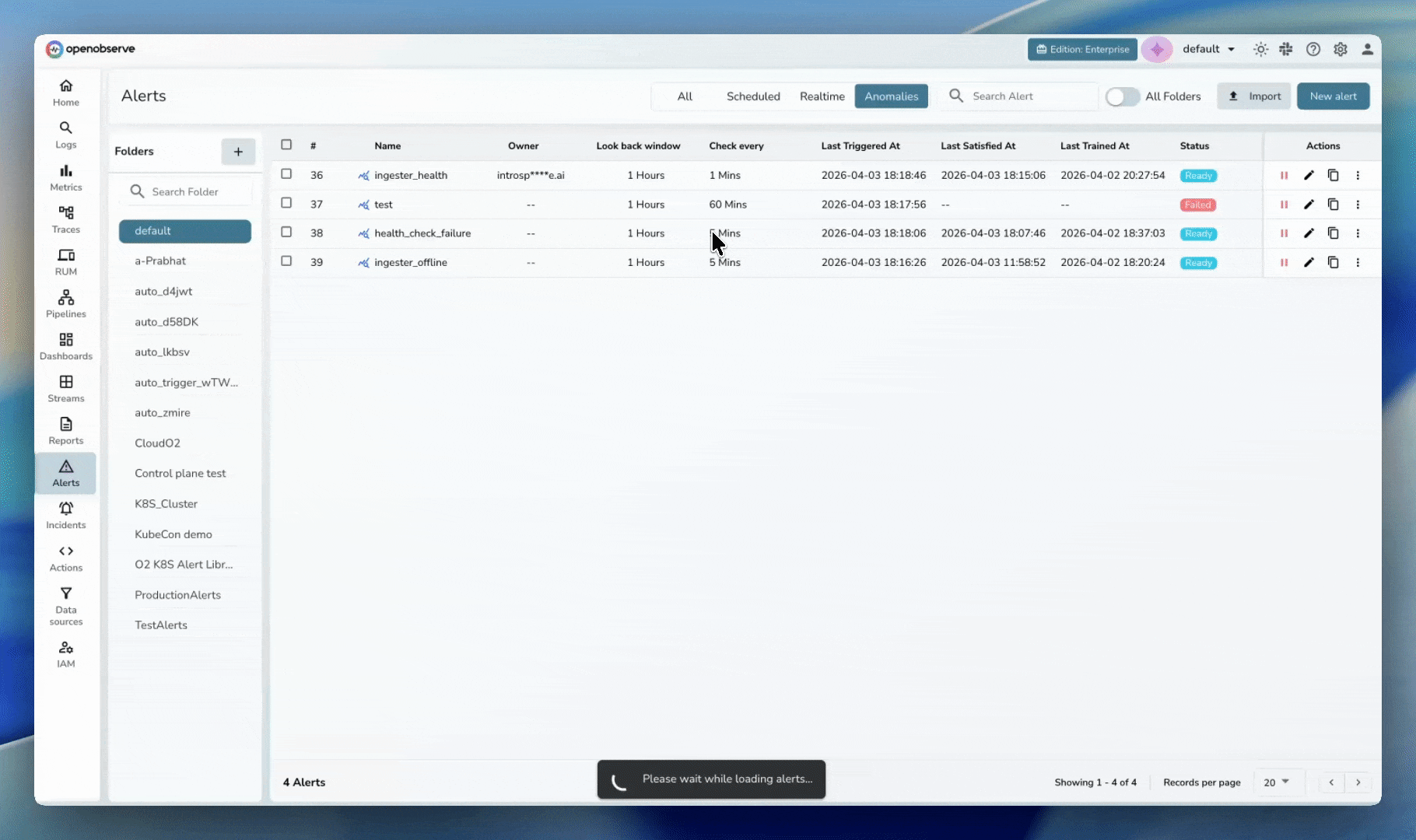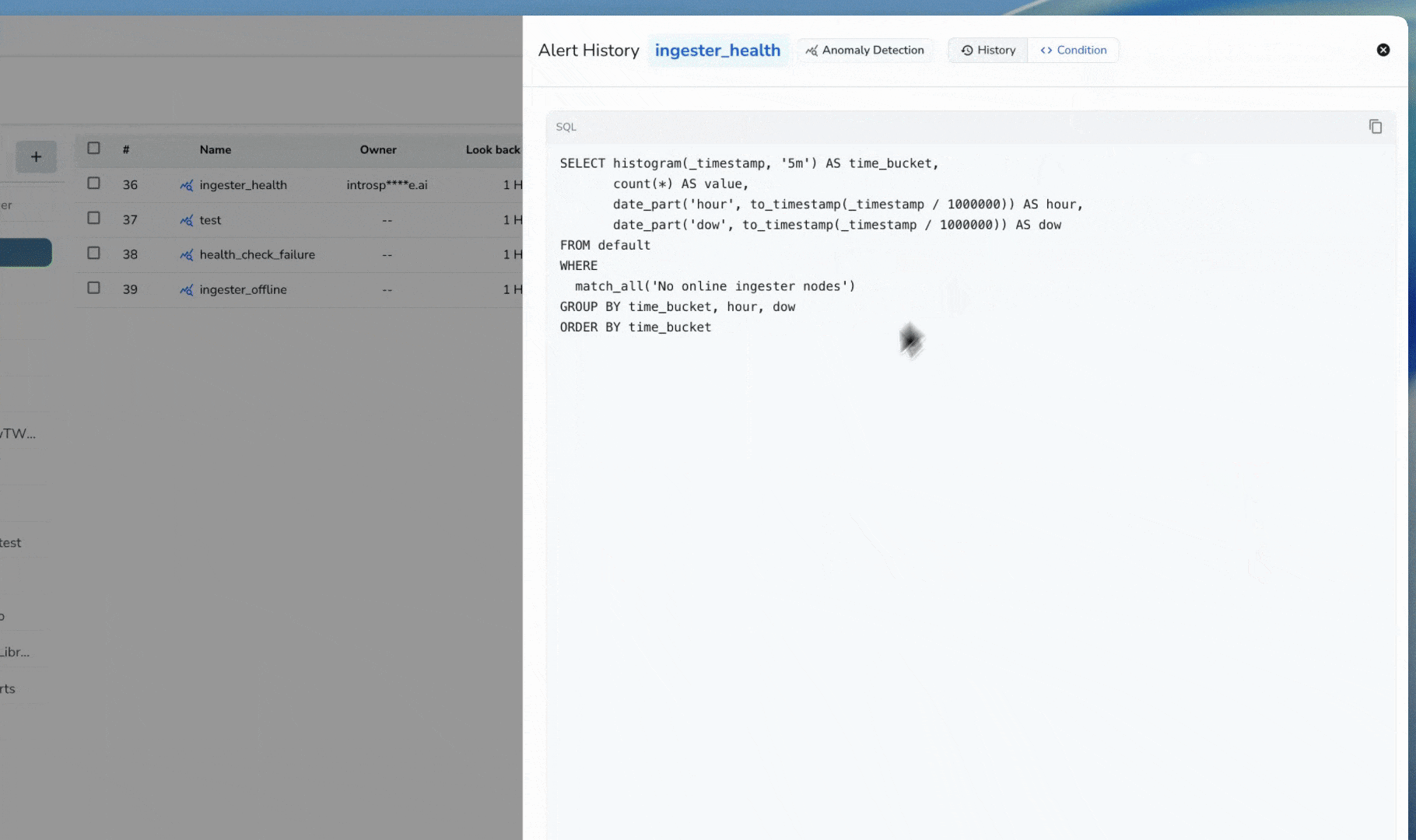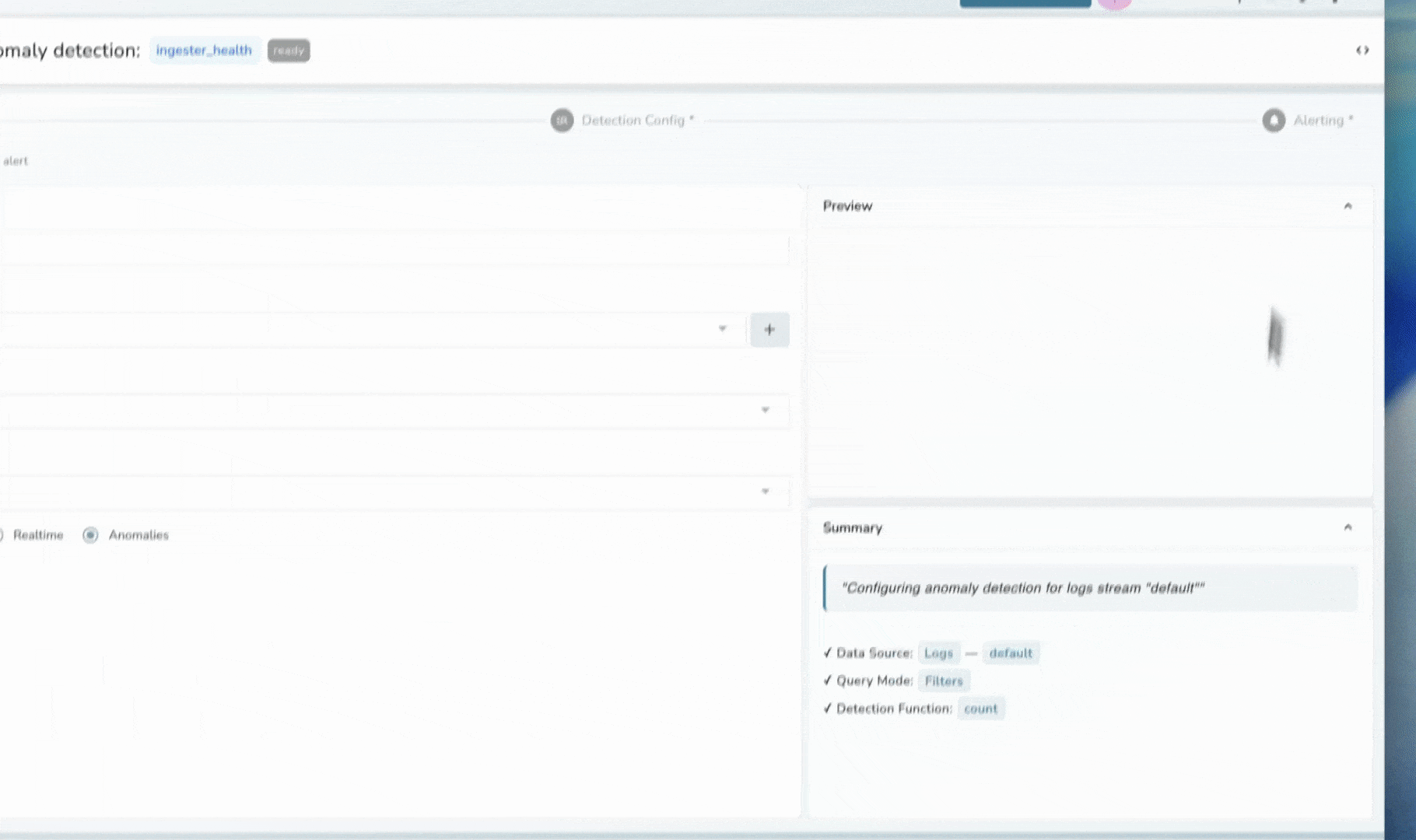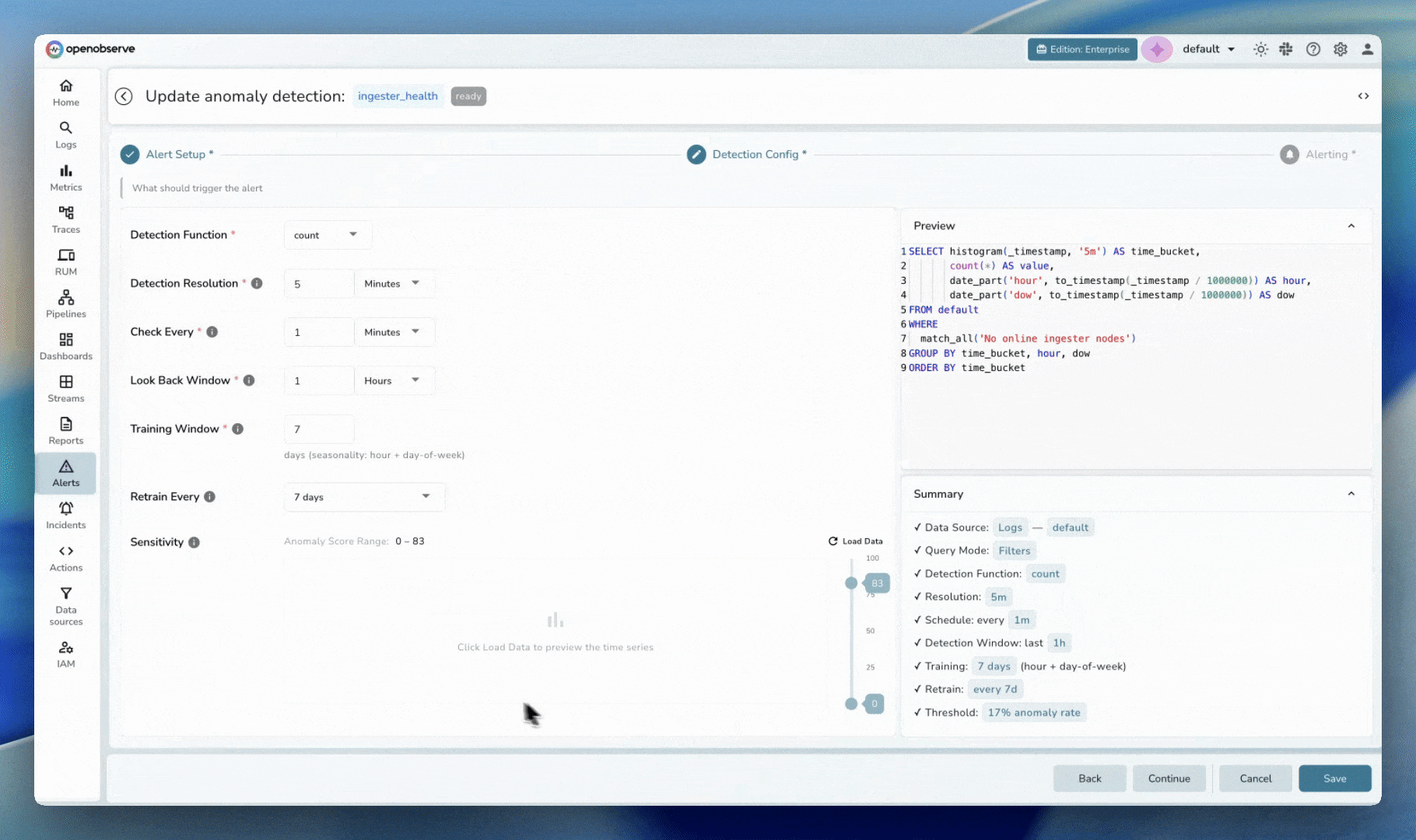
| Requirement | RCF Solution |
|---|---|
| Streaming data | Processes points sequentially as they arrive |
| No labeled data | Fully unsupervised learning |
| Handles seasonality | Shingle size + training window capture patterns |
| Fast inference | 5-second detection runs on 100+ concurrent jobs |
| Explainable | Anomaly scores with deviation percentages |
When 50 detection jobs fire every 30 minutes—each loading a model from S3 and scoring hundreds of points—runtime performance matters:
Performance (in our testing on 16-core servers):
The model learns that Monday 9 AM has 2× the latency of Saturday 4 AM. A 200ms spike on Monday morning is noise; the same spike at 4 AM Saturday fires immediately—without defining any of that logic.
By combining intelligent anomaly detection with automated alert correlation, teams can reduce mean time to resolution significantly—catching issues before they escalate to customer-facing incidents.
Want the full technical deep-dive? See our complete implementation guide: Real-Time Anomaly Detection with OpenObserve and Random Cut Forest
1. Automatic Seasonality Detection
Training window → Seasonality learned
1-6 days → Daily (24-hour cycles)
7+ days → Weekly (daily + weekday/weekend patterns)
2. Model Retraining
3. Full Auditability
-- Query all anomalies from last 24 hours
SELECT anomaly_name, actual_value, deviation_percent,
score, _timestamp
FROM "_anomalies"
WHERE is_anomaly = true
AND _timestamp > now() - interval '24 hours'
ORDER BY score DESC
4. Tuning Controls
Multiple platforms offer AI-powered anomaly detection with different strengths and trade-offs. Here's how leading solutions compare:
| Platform | Algorithm Approach | Streaming Support | Custom Queries | Best For |
|---|---|---|---|---|
| OpenObserve | Random Cut Forest (RCF) | Native streaming | Full SQL flexibility | Cost-sensitive teams, custom aggregations, full control |
| Datadog | Proprietary ensemble | Yes | Limited to predefined metrics | Teams already on Datadog APM/infra |
| AWS CloudWatch | Random Cut Forest | Yes | CloudWatch Metrics only | AWS-native infrastructure |
| New Relic | ML ensemble | Yes | NRQL queries | Full-stack observability users |
| Grafana ML | Prophet + seasonal decomp | Batch-oriented | PromQL/Flux queries | Budget-conscious, existing Grafana users |
| Dynatrace | Davis AI (proprietary) | Yes | Limited | Enterprise, auto-instrumentation |
Datadog offers anomaly detection as part of its monitoring platform. Here's how the technical approach compares:
| Feature | OpenObserve (RCF) | Datadog |
|---|---|---|
| Algorithm | Random Cut Forest (Amazon RCF) | Proprietary (likely ensemble of methods) |
| Streaming | Yes (native) | Yes |
| Seasonality | Auto-detected (daily/weekly) | Auto-detected (configurable) |
| Training data | 7-90 days | 1-4 weeks (recommended) |
| Retraining | Auto every 7 days (configurable) | Continuous sliding window |
| Custom SQL | Yes (any aggregation) | No (predefined metrics only) |
| Explainability | Score + deviation % + model version | Bounds visualization |
Datadog:
OpenObserve:
Cost Advantage: OpenObserve's architecture enables significantly lower costs at scale for teams running many anomaly detection configs, particularly with high-cardinality data.
Datadog Advantages:
OpenObserve Advantages:
_anomalies stream directly for analysisReal-world lessons from DevOps and SRE practitioners implementing AI anomaly detection:
Problem: "We trained our model on 30 days of data that included a major outage. Now it thinks 50% error rates are normal." — Reddit r/devops
Why it happens: Models learn from all training data—if that includes anomalies, they become part of the baseline.
Solution:
Problem: "Every deployment triggers 20+ false positive alerts for 2 hours until things stabilize." — HackerNews discussion
Why it happens: Deployments often change performance characteristics (new caching, query optimizations, feature flags). Models trained on pre-deployment data flag the new normal as anomalous.
Solution:
retrain_interval_days to match your deployment frequencyProblem: "Our model is tuned perfectly on last month's data but misses new failure modes completely." — Reddit r/sre
Why it happens: Overfitting to past patterns reduces sensitivity to novel anomalies.
Solution:
Problem: "We trained on 7 days of data. Every Monday morning triggers false alerts because the model never saw Monday load."
Why it happens: Weekly seasonality requires at least 2-3 full weeks to learn weekday vs. weekend patterns.
Solution:
Training window guidelines:
- Daily patterns only: 7-14 days minimum
- Weekly patterns (weekday/weekend): 21-30 days minimum
- Monthly patterns: 60-90 days minimum
Rule: Training window ≥ 3× your strongest seasonal cycle
Problem: "We get 50 anomaly alerts per day. Team started ignoring them after week 1." — DevOps practitioner
Why it happens: Not all anomalies require immediate action. Low-severity anomalies mixed with critical ones create noise.
Solution:
Problem: "Our 6-month-old model stopped catching real incidents. We didn't notice for weeks."
Why it happens: Model drift—as systems evolve, old models become less relevant.
Solution:
AI anomaly detection transforms how DevOps and SRE teams handle incident response—catching issues traditional thresholds miss, reducing alert fatigue, and adapting automatically as systems evolve.
As a core component of modern AIOps platforms, AI anomaly detection enables proactive incident management that reduces MTTR by providing early warning signals 20-40 minutes before customer-facing impact.
For teams managing Kubernetes, microservices, or any system with seasonal traffic patterns, AI anomaly detection isn't optional anymore—it's how you stay ahead of incidents instead of reacting to them.
Ready to implement AI anomaly detection?
Questions? Join our community: OpenObserve Slack • GitHub
Manas is a passionate Dev and Cloud Advocate with a strong focus on cloud-native technologies, including observability, cloud, kubernetes, and opensource. building bridges between tech and community.











