Distributed Tracing Basics: A Comprehensive Guide for Modern Observability

In today's fast-paced digital landscape, applications have evolved into intricate ecosystems of microservices, each playing a crucial role in delivering seamless user experiences. But with this evolution comes a new challenge: how do we effectively monitor and troubleshoot these complex, distributed systems? Enter distributed tracing – a powerful approach that's revolutionizing the way we understand and optimize our applications.
Imagine you're a detective, tasked with solving a mystery that spans across an entire city. Each clue leads you to a different location, and you must piece together the entire story from fragments of information scattered throughout the city. This is essentially what distributed tracing does for our applications – it provides a comprehensive map of a request's journey through the labyrinth of microservices, allowing us to uncover performance bottlenecks, identify errors, and optimize our systems with surgical precision.
In this guide, we'll embark on a journey through the fundamentals of distributed tracing. We'll explore its core concepts, uncover its transformative benefits, and equip you with the knowledge to implement this game-changing observability technique in your own systems. Whether you're a seasoned architect or a curious developer, understanding distributed tracing basics is your key to mastering the complexities of modern, cloud-native applications.
The Modern Application Landscape: Navigating Complexity
In today's microservices-based applications, a user request's journey can be profoundly complex. According to a Cloud Native Computing Foundation (CNCF) survey, 92% of organizations use containers in production, with 83% adopting microservices. This shift enables rapid development and scalability but also creates a labyrinthine web of services where a single request can touch up to 82 different services. Navigating this complexity requires a tool that can provide a holistic, end-to-end view of the system behavior, which is where distributed tracing becomes invaluable.
Traditional monitoring tools, like logging and metrics, offer insights but often fail to capture the intricate relationships between services:
- Logs provide detailed information about individual components but lack the context of how these components interact.
- Metrics offer a high-level overview of system health but don't reveal the specific paths taken by each request.
Distributed tracing fills this gap by stitching together the entire journey of a request, from its inception to completion. By assigning each request a unique identifier and propagating it across service boundaries, distributed tracing provides a complete picture of the system's behavior, allowing teams to:
- Identify which services a request passes through.
- Understand how long each service takes to process the request.
- Locate performance bottlenecks and errors.
- Diagnose issues by tracing back the path of problematic requests.
This holistic view is crucial for optimizing performance, troubleshooting, and maintaining seamless user experiences.
Distributed Tracing Standards: OpenTelemetry and the Future of Tracing
While distributed tracing isn't a new concept, its widespread adoption can be largely attributed to the emergence of open standards. Google's seminal Dapper paper in 2010 introduced the idea of using traces to understand complex systems. However, it was projects like OpenTracing and OpenCensus that made distributed tracing truly accessible by providing vendor-neutral APIs and libraries for instrumentation.
In 2019, these projects merged to form OpenTelemetry, a unified standard backed by the Cloud Native Computing Foundation (CNCF). Since then, OpenTelemetry has quickly become the de facto standard for distributed tracing, offering a cohesive set of APIs, libraries, and tools that simplify instrumentation and data collection across diverse environments.
With growing support from major cloud providers and observability platforms, OpenTelemetry is poised to reshape the future of tracing, making it more accessible and interoperable than ever before.
Core Elements of Distributed Tracing
To fully grasp distributed tracing, it’s essential to understand its key components:
Spans
- A span is like a breadcrumb that marks each step in a request’s journey through your system. It captures start and end times along with metadata like service name, operation name, and relevant tags or annotations. Spans are hierarchical in nature, reflecting relationships between operations.
Traces
- A trace is the collection of spans that form an end-to-end path for each request. Each trace is assigned a unique identifier that is propagated across service boundaries. By analyzing traces, teams can gain insights into how requests flow through their system and identify areas for improvement.
Context Propagation
- Context propagation ensures continuity across services by passing crucial information (like trace ID and span ID) from one service to another. This allows the tracing system to stitch together individual spans into one complete trace. Typically achieved through headers in HTTP requests/responses, context propagation ensures continuity across distributed services.
Instrumentation
- Instrumentation involves adding tracing code into your application to capture spans and propagate context. This can be done manually or automatically using libraries like OpenTelemetry, a vendor-neutral open-source project, which simplifies instrumentation across multiple languages and frameworks.
Why Distributed Tracing Matters
Implementing distributed tracing offers numerous advantages:
Enhanced Visibility
Distributed tracing provides an end-to-end view of how requests flow, making it easier to understand service relationships and identify bottlenecks, ensuring proactive performance optimization.
Faster Troubleshooting
When issues arise, distributed tracing enables teams to quickly pinpoint the root cause by following the affected request's path, reducing mean time to resolution (MTTR) and minimizing user impact.
Improved Collaboration
By providing a shared understanding of system behavior, distributed tracing fosters collaboration between development, operations, and other stakeholders, facilitating effective problem-solving, decision-making, and capacity planning.
Increased Efficiency
Leveraging distributed tracing to identify and address performance bottlenecks and inefficiencies can help optimize resource utilization and reduce operational costs. Such improvements can be especially impactful in dynamic, cloud-based environments.
Practical Example: Setting Up Distributed Tracing with OpenObserve
Let's walk through implementing distributed tracing in a real-world scenario, starting from scratch.
Step 0: Prerequisites
- Create project directory:
mkdir tracing-demo
cd tracing-demo
- Create and activate Python virtual environment:
python -m venv venv
source venv/bin/activate # On Windows, use: venv\Scripts\activate
- Install required packages:
pip install fastapi==0.104.1 \
uvicorn==0.24.0 \
opentelemetry-api==1.21.0 \
opentelemetry-sdk==1.21.0 \
opentelemetry-instrumentation-fastapi==0.42b0 \
opentelemetry-exporter-otlp-proto-grpc==1.21.0 \
python-dotenv==1.0.0
Step 1: Set Up OpenObserve
- Start OpenObserve using Docker:
docker run -d \
--name openobserve \
-p 5080:5080 \
-e ZO_ROOT_USER_EMAIL=root@example.com \
-e ZO_ROOT_USER_PASSWORD=Complexpass#123 \
public.ecr.aws/zinclabs/openobserve:latest
- Verify OpenObserve is running:
curl http://localhost:5080/healthz
# Should return {"status":"ok"}
Step 2: Set Up OpenTelemetry Collector
- Remove any existing collector container:
docker stop otel-collector || true
docker rm otel-collector || true
- Create the collector configuration file:
cat > otel-config.yaml << 'EOF'
receivers:
otlp:
protocols:
grpc:
endpoint: "0.0.0.0:4317"
http:
endpoint: "0.0.0.0:4318"
processors:
batch:
timeout: 1s
send_batch_size: 1024
exporters:
otlphttp:
endpoint: "http://host.docker.internal:5080/api/default"
headers:
Authorization: "Basic cm9vdEBleGFtcGxlLmNvbTpDb21wbGV4cGFzcyMxMjM="
organization: "default"
stream-name: "default"
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlphttp]
EOF
- Start the OpenTelemetry Collector:
docker run -d \
--name otel-collector \
-p 4317:4317 \
-p 4318:4318 \
-p 8888:8888 \
-v $(pwd)/otel-config.yaml:/etc/otel-collector-config.yaml \
--add-host host.docker.internal:host-gateway \
otel/opentelemetry-collector:latest \
--config=/etc/otel-collector-config.yaml
- Verify the collector is running:
docker ps | grep otel-collector
docker logs otel-collector
Step 3: Create FastAPI Application
- Create the main application file:
cat > main.py << 'EOF'
from fastapi import FastAPI
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.instrumentation.fastapi import FastAPIInstrumentor
# Initialize FastAPI
app = FastAPI()
# Configure OpenTelemetry
resource = Resource.create({
"service.name": "demo-service",
"service.namespace": "demo"
})
# Initialize TracerProvider
provider = TracerProvider(resource=resource)
trace.set_tracer_provider(provider)
# Configure OTLP exporter
otlp_exporter = OTLPSpanExporter(
endpoint="http://localhost:4317",
insecure=True
)
# Add BatchSpanProcessor
provider.add_span_processor(BatchSpanProcessor(otlp_exporter))
# Instrument FastAPI
FastAPIInstrumentor.instrument_app(app)
# Get a tracer
tracer = trace.get_tracer(__name__)
@app.get("/orders/{order_id}")
async def get_order(order_id: str):
with tracer.start_as_current_span("get_order") as span:
span.set_attributes({
"order.id": order_id,
"service.operation": "get_order"
})
# Simulate database lookup
order = {
"id": order_id,
"status": "processing",
"items": ["item1", "item2"]
}
return order
@app.get("/health")
async def health_check():
return {"status": "healthy"}
EOF
Step 4: Run and Test
- Start the FastAPI application:
python -m uvicorn main:app --reload --host 0.0.0.0 --port 8000
- In a new terminal, test the endpoints:
# Open new terminal and navigate to project directory
cd tracing-demo
source venv/bin/activate
# Test health endpoint
curl http://localhost:8000/health
# Test orders endpoint
curl http://localhost:8000/orders/123
# Generate multiple traces
for i in {1..5}; do
curl http://localhost:8000/orders/$i
sleep 1
done
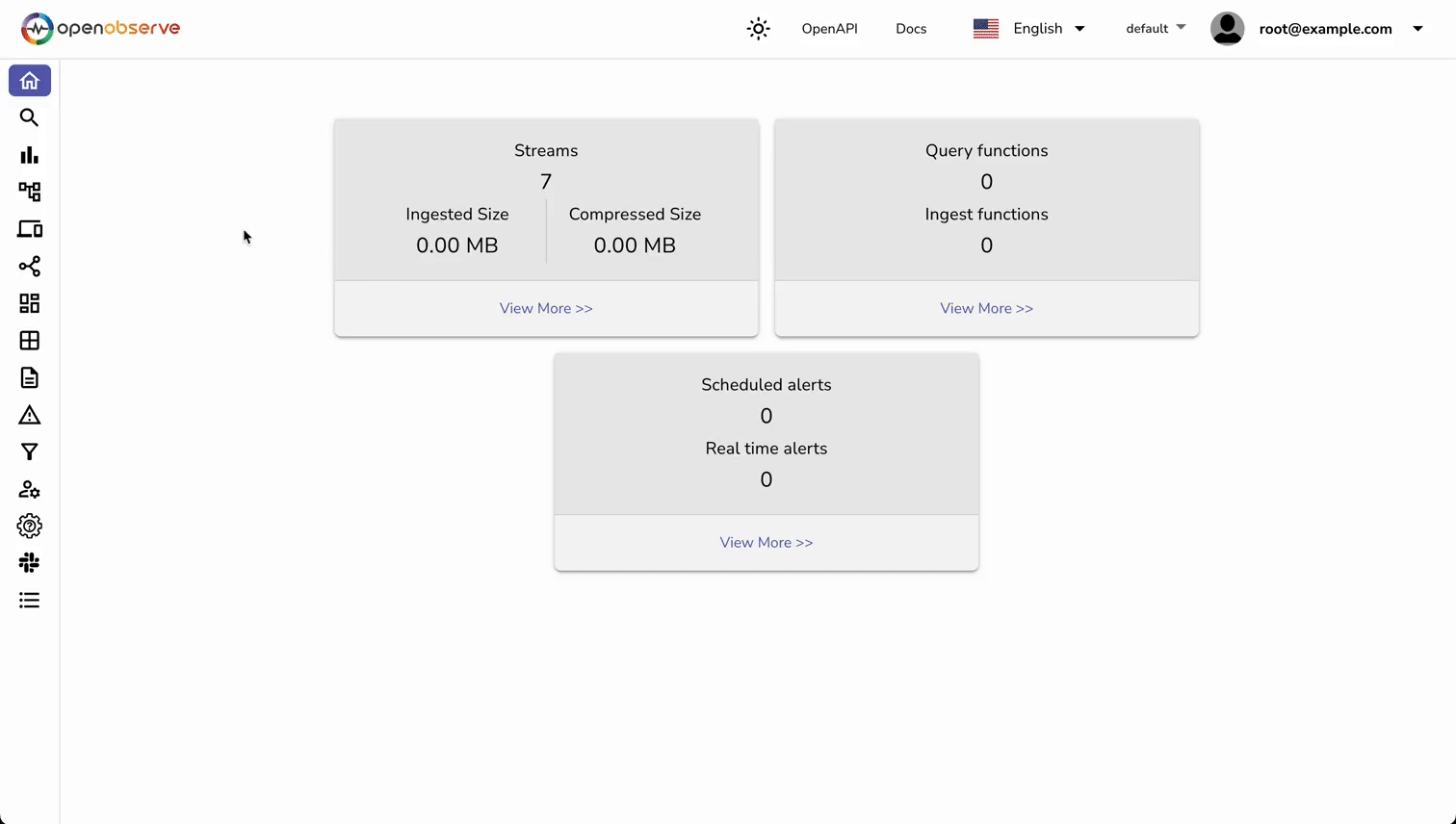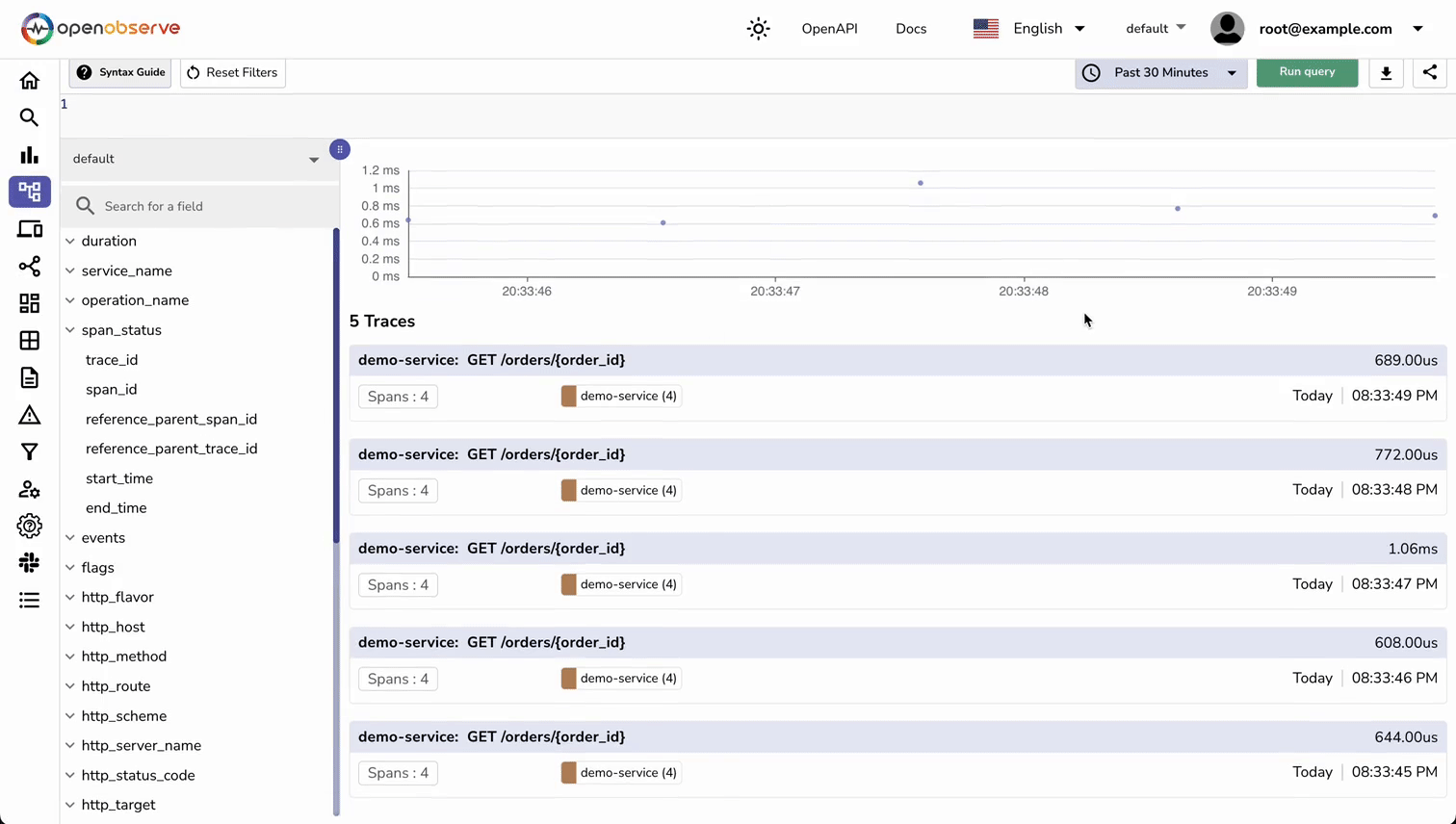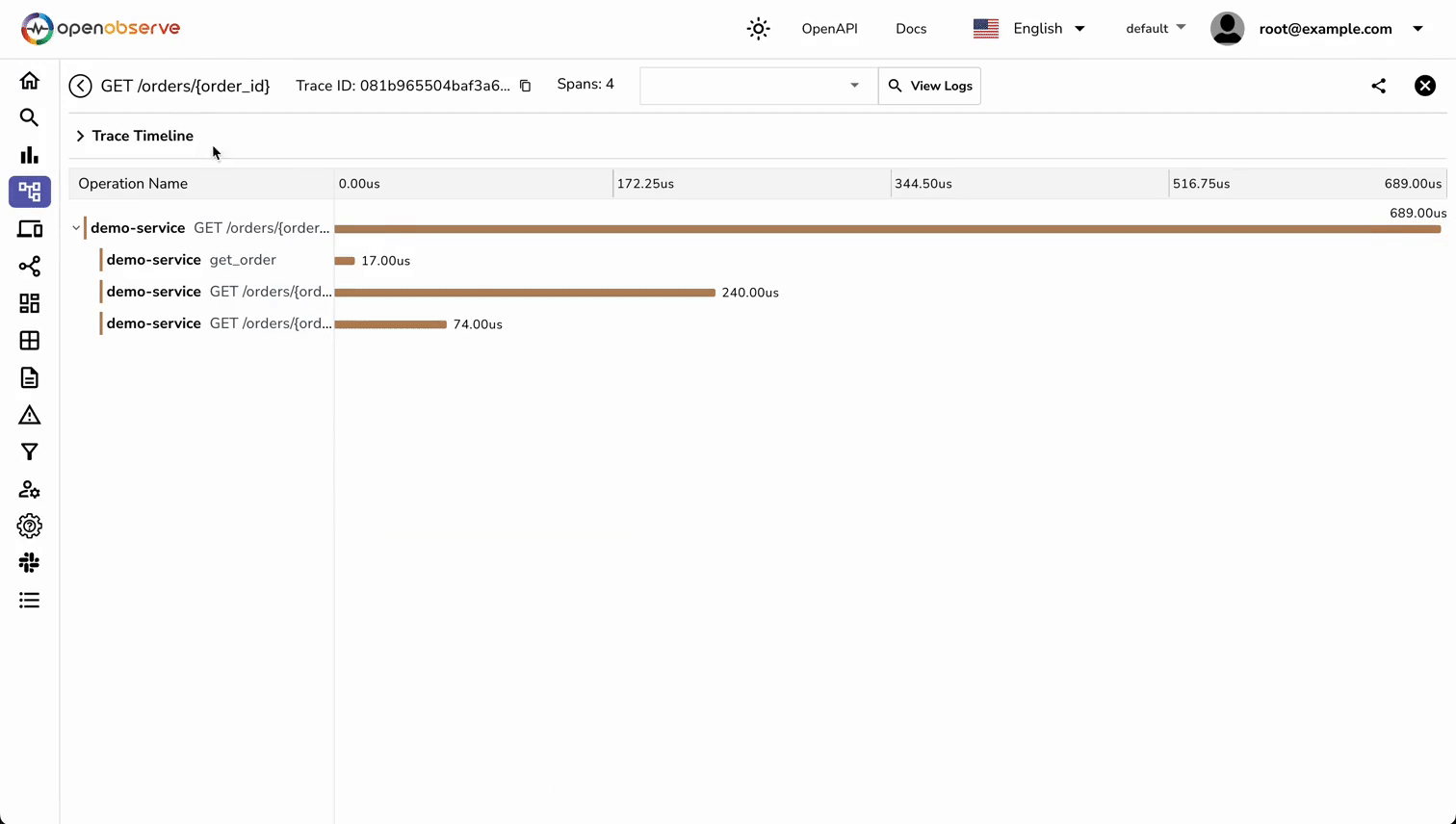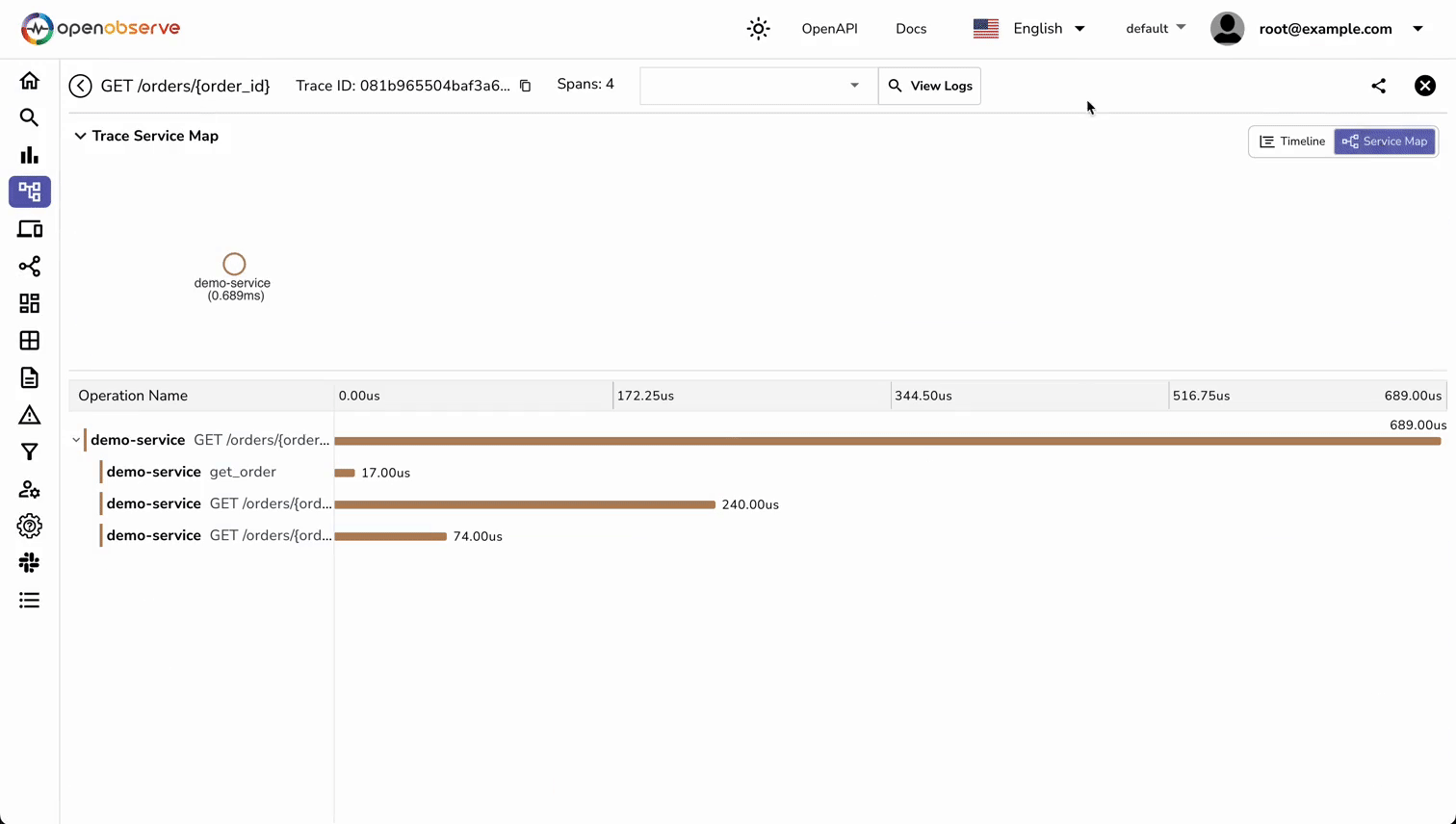
- View traces in OpenObserve:
- Open http://localhost:5080 in your browser
- Login with:
- Email: root@example.com
- Password: Complexpass#123
- Navigate to Traces section (http://localhost:5080/web/traces?org_identifier=default)
You should now see traces appearing in OpenObserve showing:
- The HTTP request span
- The custom get_order span with order details
- Service name and namespace
- All span attributes
- Request timing information
Troubleshooting
If you encounter any issues:
- Verify services are running:
# Check OpenObserve
docker ps | grep openobserve
curl http://localhost:5080/healthz
# Check OpenTelemetry Collector
docker ps | grep otel-collector
docker logs otel-collector
- Verify network connectivity:
# Test collector endpoint
curl -v localhost:4317
# Test OpenObserve endpoint
curl -v -H "Authorization: Basic cm9vdEBleGFtcGxlLmNvbTpDb21wbGV4cGFzcyMxMjM=" \
http://localhost:5080/api/default
# If needed, restart services:
docker restart openobserve
docker restart otel-collector
This setup provides a complete distributed tracing pipeline using OpenTelemetry and OpenObserve, allowing you to monitor and analyze request flows through your application.
Distributed Tracing Best Practices
To leverage the full power of distributed tracing, consider these best practices:
Focus on Critical Paths
Prioritize instrumenting services critical to your application's performance. These are typically high-traffic services or those responsible for essential business logic (e.g., user authentication or payment processing). By focusing on these areas first, you can quickly gain valuable insights into performance bottlenecks.
Adopt Consistent Naming Conventions
Establish clear naming conventions for services, operations, and tags so traces are easy to interpret. For example:
- Use [service-name].[operation-type].[resource] (e.g., user-service.get.profile) for span names.
- Create standardized tags for attributes such as environment or customer ID.
This consistency simplifies querying and analyzing trace data across your entire system.
Ensure Effective Context Propagation
Implement robust context propagation mechanisms using industry-standard formats like W3C Trace Context or B3 headers. Pay special attention to asynchronous operations (e.g., message queues) where context might be lost without proper handling.
Optimize Sampling Rates
Sampling every request can be expensive at scale. Instead:
- Use head-based sampling for general coverage.
- Apply tail-based sampling for capturing outliers such as errors or slow requests.
- Adjust sampling dynamically based on system load.
Regularly review your sampling strategy as your system evolves.
Integrate with Other Telemetry
Combine traces with logs and metrics for deeper insights into system behavior:
- Correlate logs with trace IDs.
- Use traces as context when analyzing metrics.
This holistic approach gives you greater visibility into both high-level trends and specific issues within your system.
Leverage AI and Machine Learning
Use AI and ML to automatically detect anomalies, identify patterns, and surface insights from the growing volume of tracing data. Implement machine learning models that can learn normal behavior patterns and flag deviations. Use clustering algorithms to group similar traces, making it easier to identify recurring issues. Also, explore causal inference techniques to automatically determine the root cause of performance problems.
As your tracing data grows, also consider implementing advanced analytics pipelines that can process and derive insights from traces in near real-time.
Emerging Trends in Distributed Tracing
As distributed systems continue to evolve, new trends are reshaping how we approach tracing. Here are four key developments that are transforming the future of observability:
Automatic Instrumentation
The next generation of tracing tools will dramatically simplify implementation through:
- Bytecode instrumentation and eBPF enabling code-free tracing setup
- Smart auto-instrumentation that adapts to different architectures
- Dynamic adjustment of tracing details based on system state
- Seamless integration with legacy applications
Real-Time Streaming Analytics
As data volumes grow exponentially, real-time capabilities become crucial:
- Stream processing engines analyzing trace data in-flight
- Instant anomaly detection and visualization
- Automated responses to emerging issues
- Advanced compression and indexing for efficient data handling
- Real-time system behavior monitoring
AI-Powered Operations (AIOps)
Artificial intelligence is revolutionizing how we handle trace data:
- Predictive analytics identifying potential issues hours in advance
- Automated parameter adjustment and traffic routing
- Self-healing systems that fix common problems automatically
- Machine learning models trained on vast tracing datasets
- Intelligent pattern recognition and anomaly detection
Observability-Driven Development
Tracing is becoming fundamental to the development process:
- Built-in tracing capabilities in development environments
- Real-time performance impact analysis of code changes
- Automated rejection of changes that degrade trace metrics
- Version-controlled observability configurations
- Performance service level objectives (SLOs) as code
These trends highlight how distributed tracing is evolving from a debugging tool into an essential part of modern software development and operations. By staying ahead of these developments, teams can better prepare for the future of observability.
Embrace the Future of Observability
In the realm of modern, cloud-native applications, distributed tracing has emerged as a vital tool for navigating complexity and ensuring optimal performance. By providing an end-to-end view of request flows, distributed tracing empowers teams to quickly identify issues, optimize resources, and deliver exceptional user experiences.
As the adoption of microservices and containerization continues to surge, the importance of distributed tracing will only continue to grow. By embracing this powerful technique and staying ahead of emerging trends, organizations can unlock the full potential of their distributed systems and thrive in the era of cloud-native observability.

OpenObserve: Your Partner in Distributed Tracing
At OpenObserve, we understand the critical role of distributed tracing in modern observability. That's why we've built a powerful platform that seamlessly integrates with OpenTelemetry, providing you with the tools and insights you need to master your application's performance.
With OpenObserve, you can leverage:
- Simple integration with OpenTelemetry: Effortlessly integrate with your existing OpenTelemetry setup, enabling seamless tracing data collection and analysis .
- Comprehensive visualization capabilities: Visualize your tracing data with intuitive, customizable dashboards that provide deep insights into your application's behavior .
- Highly customizable alerts: Set up intelligent alerts to proactively detect and respond to performance issues before they impact your users .
- Advanced processing and analytics: Leverage advanced data processing and analytics capabilities to derive actionable insights from your tracing data at scale .
Ready to take your observability game to the next level? Explore OpenObserve today and discover how our cutting-edge platform can help you harness the full power of distributed tracing. Join the observability revolution and unlock the true potential of your distributed systems with OpenObserve.
Author:

Nitya is a Developer Advocate at OpenObserve, with a diverse background in software development, technical consulting, and organizational leadership. Nitya is passionate about open-source technology, accessibility, and sustainable innovation.