Getting Started with OpenObserve
Compare the top 10 Datadog competitors and alternatives in 2026: OpenObserve, Grafana, New Relic, Dynatrace, and Splunk. Pricing breakdowns, feature tables, and migration guidance for DevOps and SRE teams.
Observability vs monitoring explained. Learn how they differ, what each costs, and why modern teams layer observability on top of monitoring.
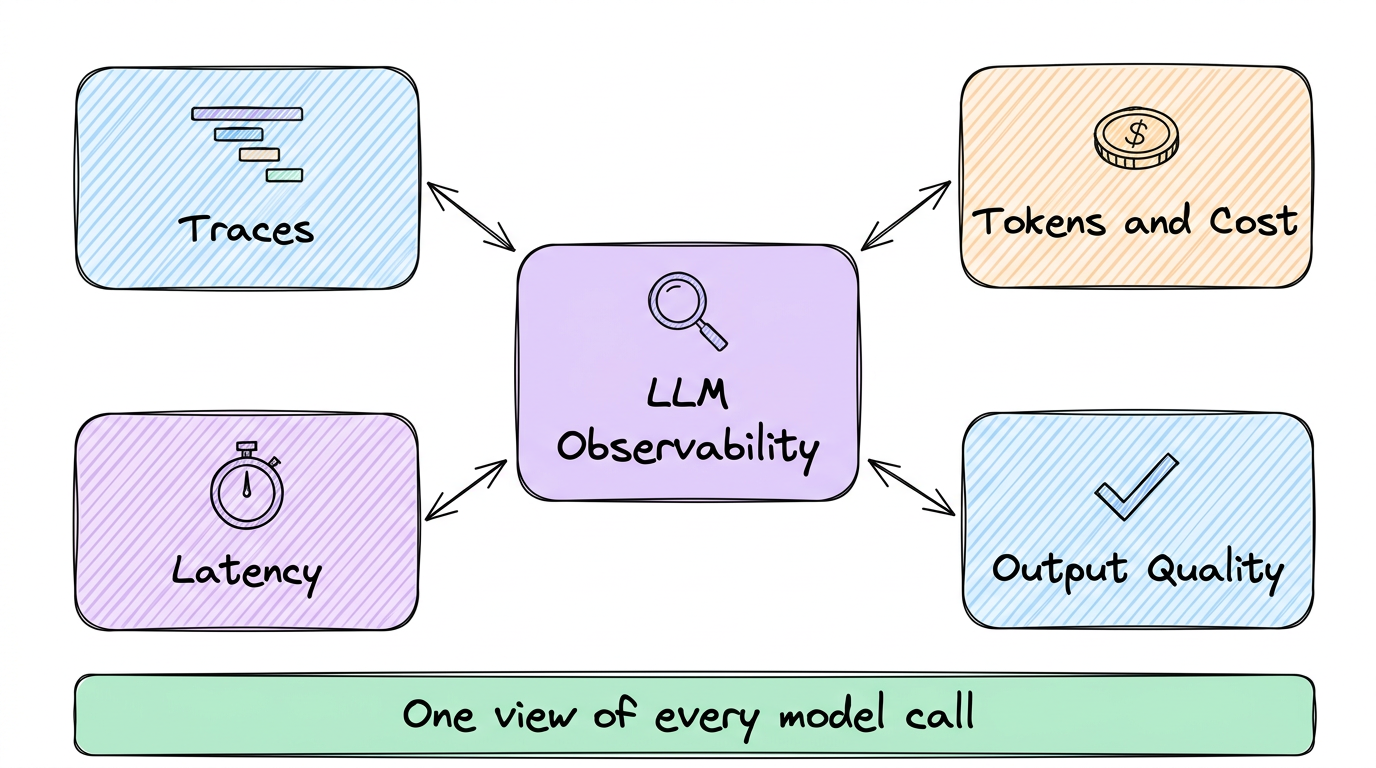
LLM observability explained for engineers: what it is, why traditional APM misses LLM failures, the three layers (computational, semantic, agentic), the core signals to track in production, and how OpenTelemetry GenAI semantic conventions standardize instrumentation.
Struggling with alert fatigue? Learn how to reduce noisy alerts, improve signal quality, and build effective alerting strategies that actually help teams respond faster.
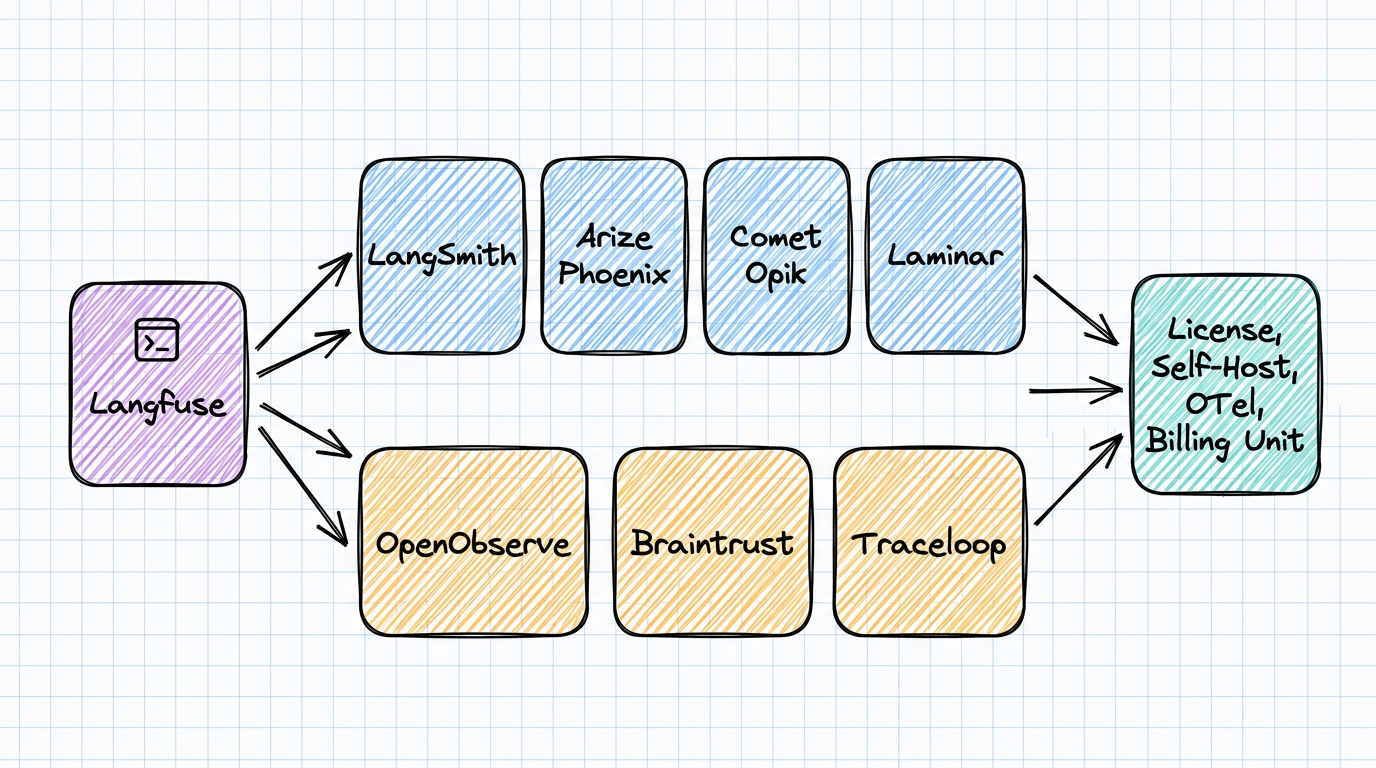
Seven Langfuse alternatives compared for 2026: OpenObserve, LangSmith, Arize Phoenix, Comet Opik, Laminar, Braintrust, and Traceloop. Real licenses, self-hosting limits, OpenTelemetry support, and what the ClickHouse acquisition actually changed.
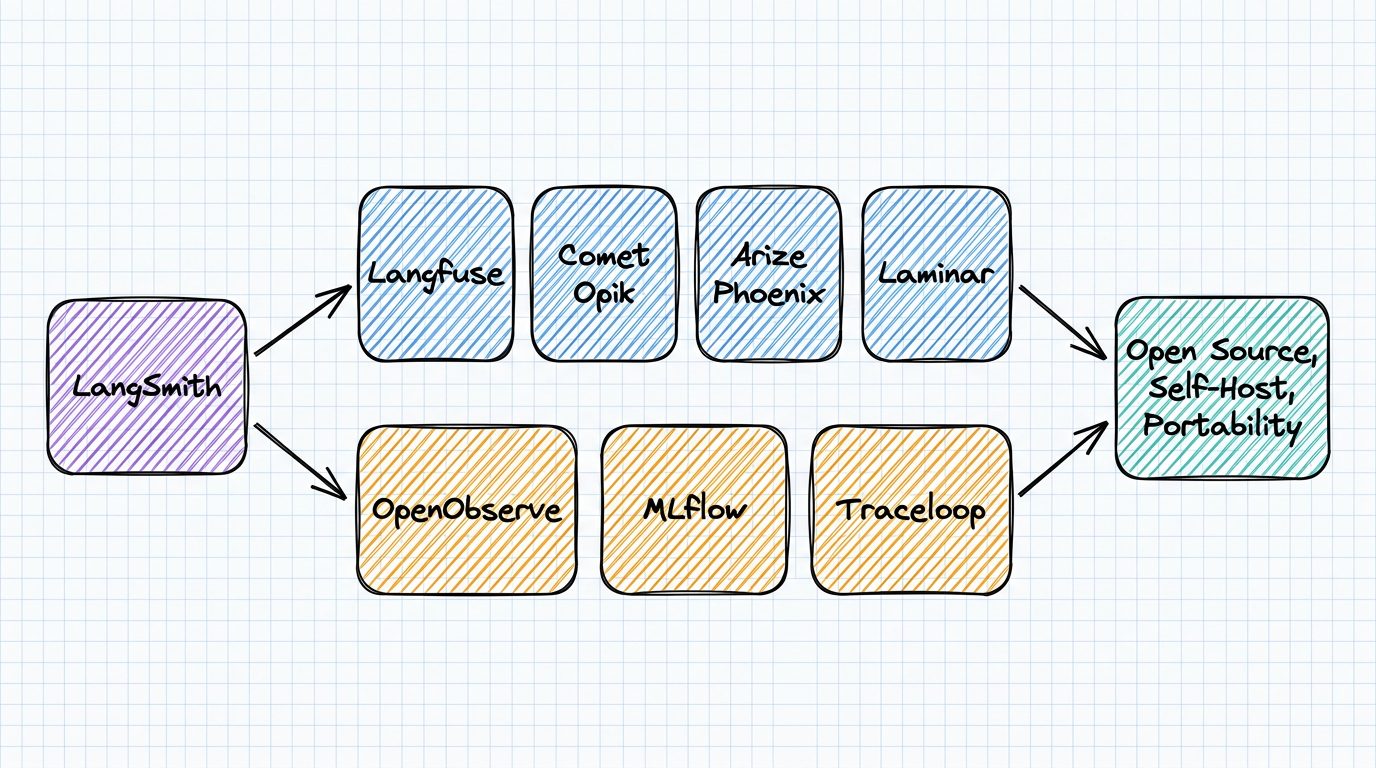
Seven LangSmith alternatives compared for 2026: OpenObserve, Langfuse, Comet Opik, Arize Phoenix, Laminar, MLflow, and Traceloop. Licenses audited from source, real self-hosting limits, and which tools survived a year of acquisitions.
A complete OpenTelemetry overview: architecture, components, OTLP, and the Collector, plus what its 2026 CNCF graduation means.
Learn the difference between head-based and tail-based sampling in observability. Compare pros, cons, and use cases to choose the right strategy for tracing.
Compare the best Prometheus alternatives in 2026 for metrics at scale. See how OpenObserve, VictoriaMetrics, Thanos, Mimir, Cortex, and more handle high cardinality, long-term storage, and cost.
Add real observability to CrewAI: map Crew, Agent, and Task objects to OpenTelemetry spans, tell CrewAI's own anonymous telemetry apart from your own tracing, and send the full multi-agent trace to OpenObserve.
Helicone entered maintenance mode after Mintlify's March 2026 acquisition, with new signups closed and the roadmap frozen. Here's how to move LLM observability off Helicone's proxy and onto OpenObserve: replace the base-URL proxy with OpenTelemetry instrumentation, map Properties, Users, and Sessions to gen_ai attributes, and get infra correlation in the same backend.
You asked, we shipped: make one dashboard the org-wide landing view in OpenObserve. Pin it from the dashboard list or the dashboard header, and everyone on the team sees the same Home tab, server-side and across devices.
Trace the OpenAI Agents SDK with OpenTelemetry: map handoffs, guardrails, and agent spans to OTLP and send the full trace to OpenObserve, not OpenAI's backend.
Twelve config-level tactics for observability cost optimization, sampling, pipeline filtering, retention tiers, and cardinality control, with before/after numbers and real config examples for logs, metrics, and traces.
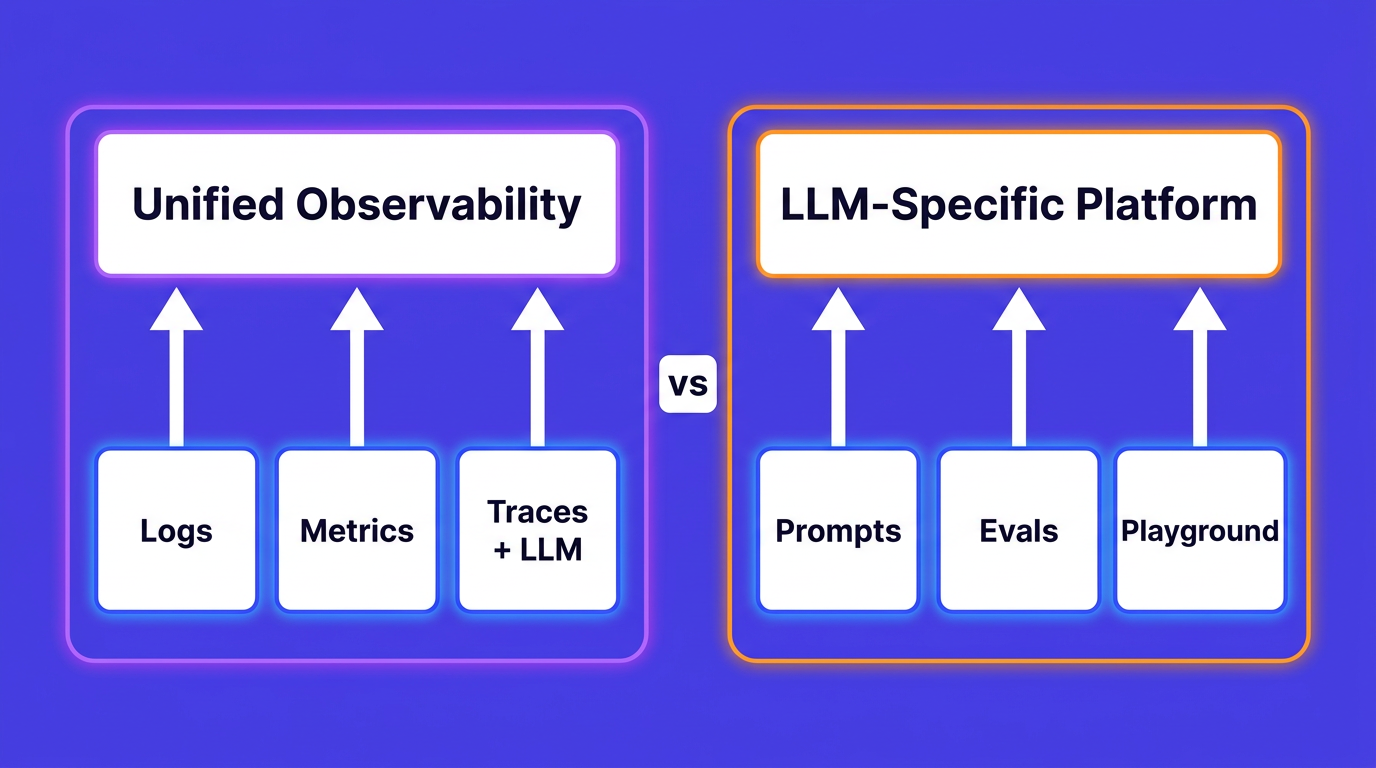
OpenObserve vs Langfuse in 2026: unified infra+LLM observability vs a dedicated LLM platform. Feature matrix, pricing, and when to use each (or both).
Compare the best log visualization tools in 2026: OpenObserve, Kibana, Grafana Loki, Datadog, and Splunk. Covers AI-assisted analysis, dashboard quality, and cost.
A practical guide to the best distributed tracing tools in 2026: OpenObserve, Jaeger, Grafana Tempo, Zipkin, and Honeycomb. Covers OTel compatibility, high-cardinality support, and deployment trade-offs.
Discover the best Elasticsearch alternatives in 2026. Compare OpenObserve, OpenSearch, ClickHouse, Grafana Loki, and Solr on cost, search performance, and deployment options.
A comprehensive comparison of open source LLM observability tools in 2026: OpenObserve, Langfuse, Helicone, and Arize Phoenix. Covers prompt tracing, cost tracking, evaluation frameworks, and unified infrastructure monitoring.
A practical comparison of the top log management tools in 2026: OpenObserve, Splunk, Datadog, Grafana Loki, and Elastic. Covers collection, indexing, retention, and cost for modern DevOps and SRE teams.
A practical guide to the top 10 microservices monitoring tools in 2026: OpenObserve, Grafana LGTM, Datadog, Dynatrace, and Prometheus. Covers unified telemetry, cardinality handling, and cost trade-offs.