Prometheus Metric Types (Counters, Gauges, Histograms, Summaries)

Simran Kumari
November 19, 2025
7 min read
Don’t forget to share!
Try OpenObserve Cloud today for more efficient and performant observability.
Your application is running in production. How do you know if it's healthy? Is it fast? Are users experiencing errors? How many requests per second is your API handling right now?
These aren't just hypothetical questions ,they're critical to running reliable systems. The answer lies in metrics: numerical measurements that tell the story of your system's behavior over time.
In this comprehensive guide, we'll explore Prometheus metrics from the ground up, understand the four core metric types, learn how to choose the right type for your use case, and discover how to transform these metrics into actionable dashboards using OpenObserve.
Prometheus metrics are numerical measurements that describe the behavior, performance, and health of your system over time. They’re designed for real-time monitoring, alerting, and debugging, giving you deep visibility into how your application and infrastructure are behaving.
At their core, Prometheus metrics are lightweight, time-series data points tracked over time with timestamps, designed for efficient, high-performance monitoring.
Every Prometheus metric follows this structure:
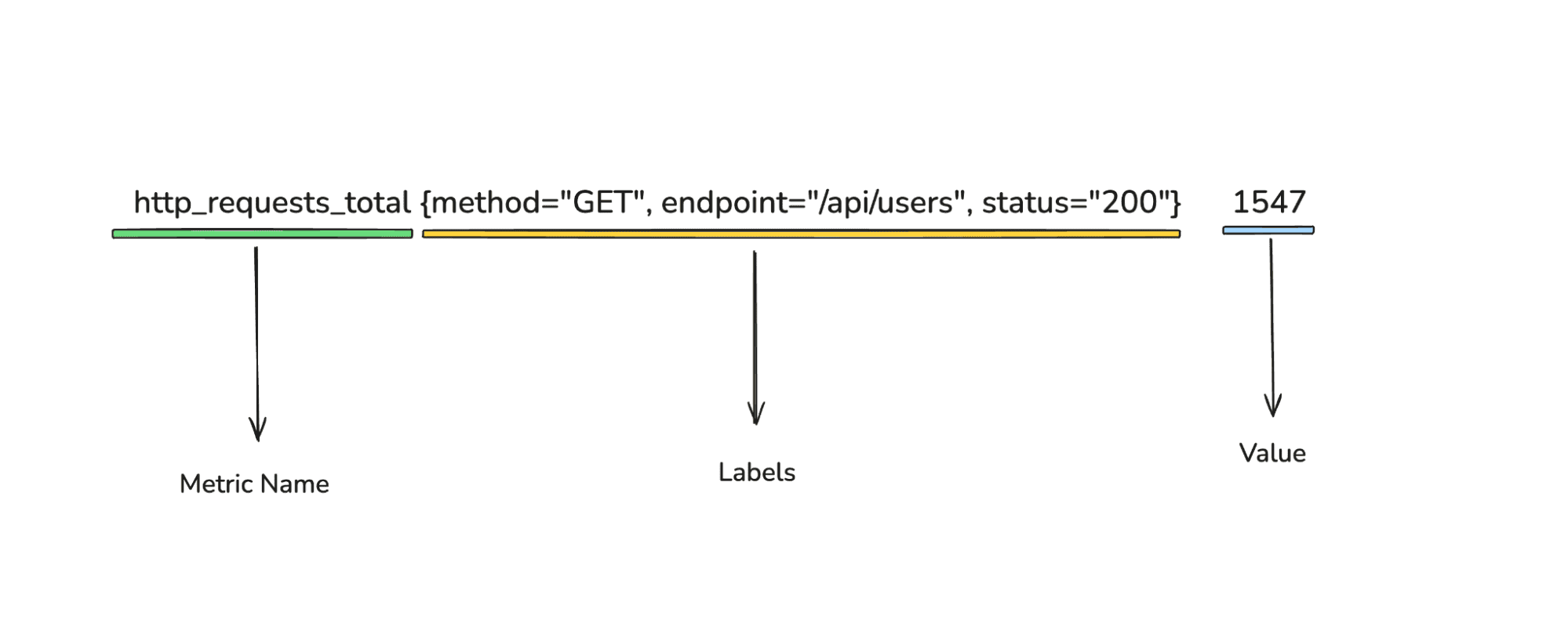
Key components:
http_requests_total)Prometheus provides four fundamental metric types, each designed for specific use cases. Understanding these types is essential for effective instrumentation and monitoring.
A Counter is a metric that only increases over time (or resets to zero on restart). It’s perfect for tracking events that happen repeatedly, requests served, errors occurred, jobs processed, GC cycles, and so on.
A Gauge is a metric type whose value can go up or down. It represents the current value of something in your system memory usage, pod count, queue depth, CPU temperature, etc.
A Histogram measures the distribution of values by placing each observation into predefined buckets. It tracks:
The most common use case is latency.
How histogram buckets work?
Suppose you define buckets: 0.3s, 0.5s, 0.7s, 1s, 1.2s, +Inf.
A Summary is similar to a histogram but computes quantiles client-side (inside your application). It exposes:
Limitations:
Because of this, Prometheus recommends using histograms over summaries unless you must calculate quantiles in-app and don’t care about aggregation.
Understanding what these metrics are is only the first step. The real value comes when you can query, visualize, and alert on them in a way that helps you answer real questions about your system’s health.
And that’s exactly where OpenObserve (O2) comes in.
Prometheus is great at scraping and storing metrics , but developers and SREs need:
OpenObserve gives you all of that on top of your Prometheus metric data, making it much easier to explore patterns, build dashboards, and set alerts without juggling multiple tools.
For detailed steps on OpenObserve and Prometheus integration check out this guide.
In short: Prometheus collects, OpenObserve powers everything beyond it.
Now that we understand the different Prometheus metric types and why OpenObserve is a great place to work with them, let's look at how to actually query and visualize these metrics inside OpenObserve.
You can query and visualize Prometheus metrics using standard SQL or using native PromQL whichever your team prefers.
When Prometheus metrics are ingested into O2, each sample becomes a row with:
metric → name of the metric (e.g., http_requests_total)value → the metric’s numeric valuetimestamp → time of ingestionlabels → flattened key–value tags (e.g., method, status, service, job)type → counter, gauge, histogram_bucket, etc.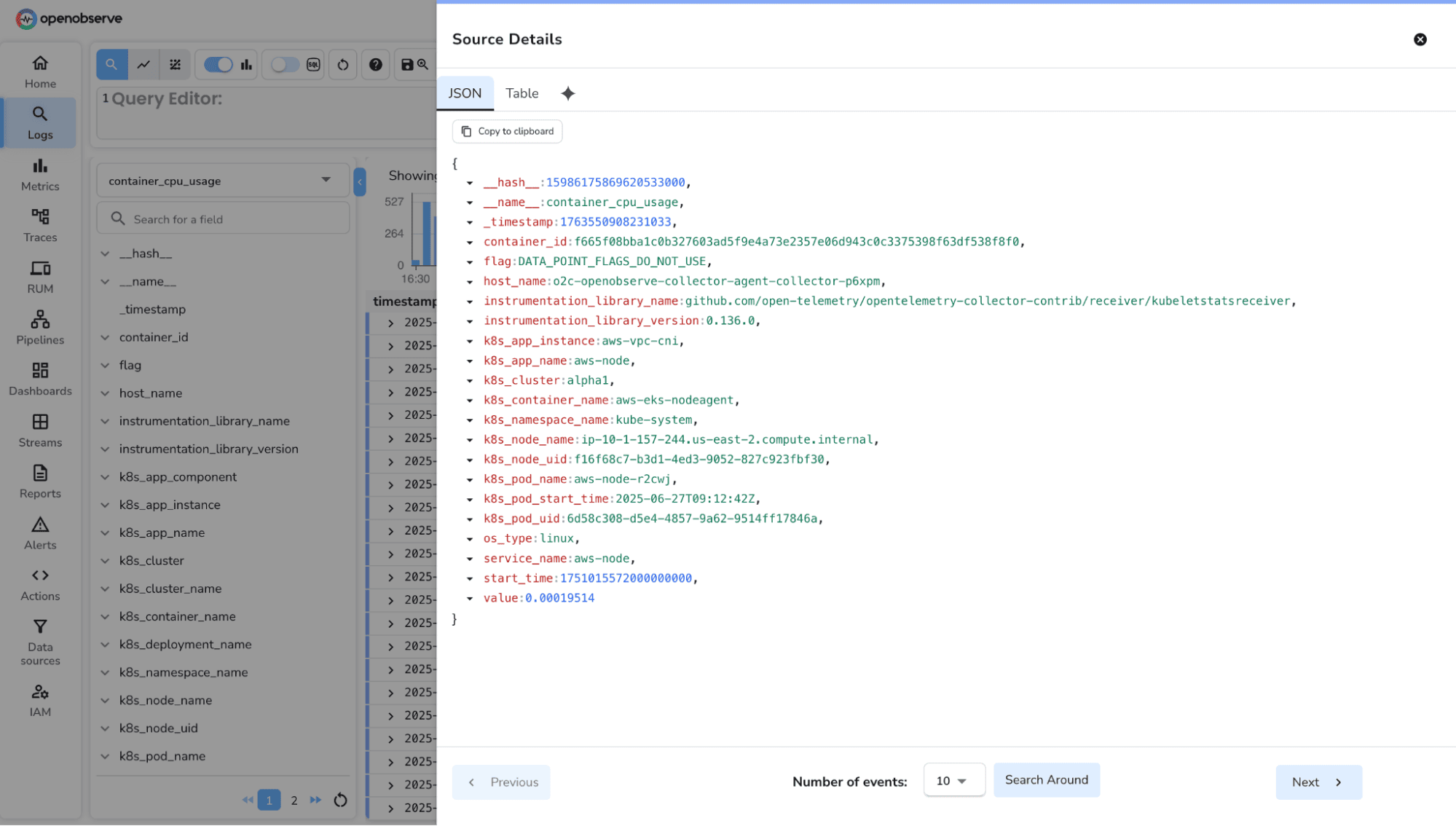
1. Rate (per-second speed of increase)
rate(http_requests_total[1m])
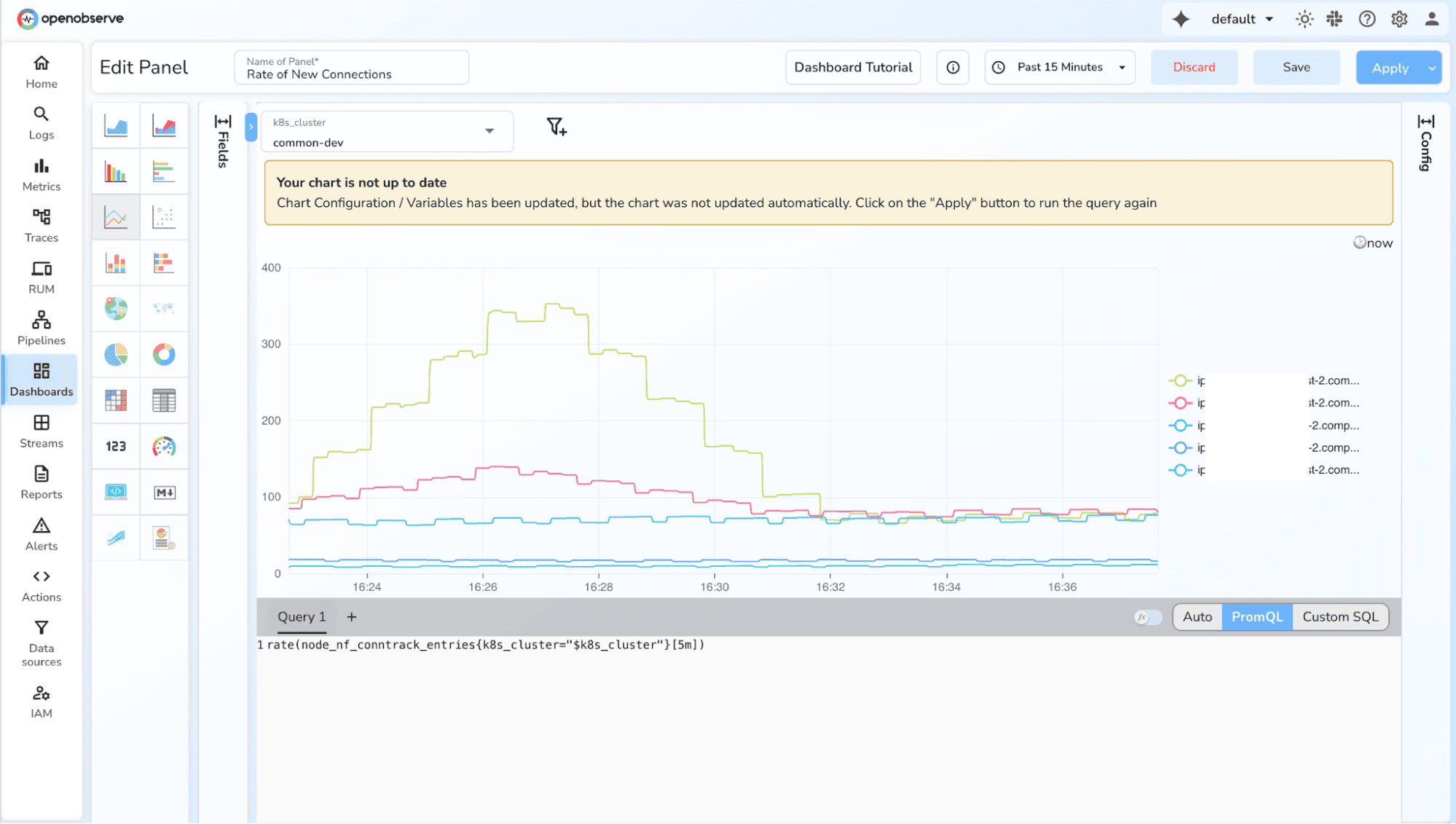
2. Increase over a window
increase(http_requests_total[5m])
3. Total throughput
sum(rate(http_requests_total[1m]))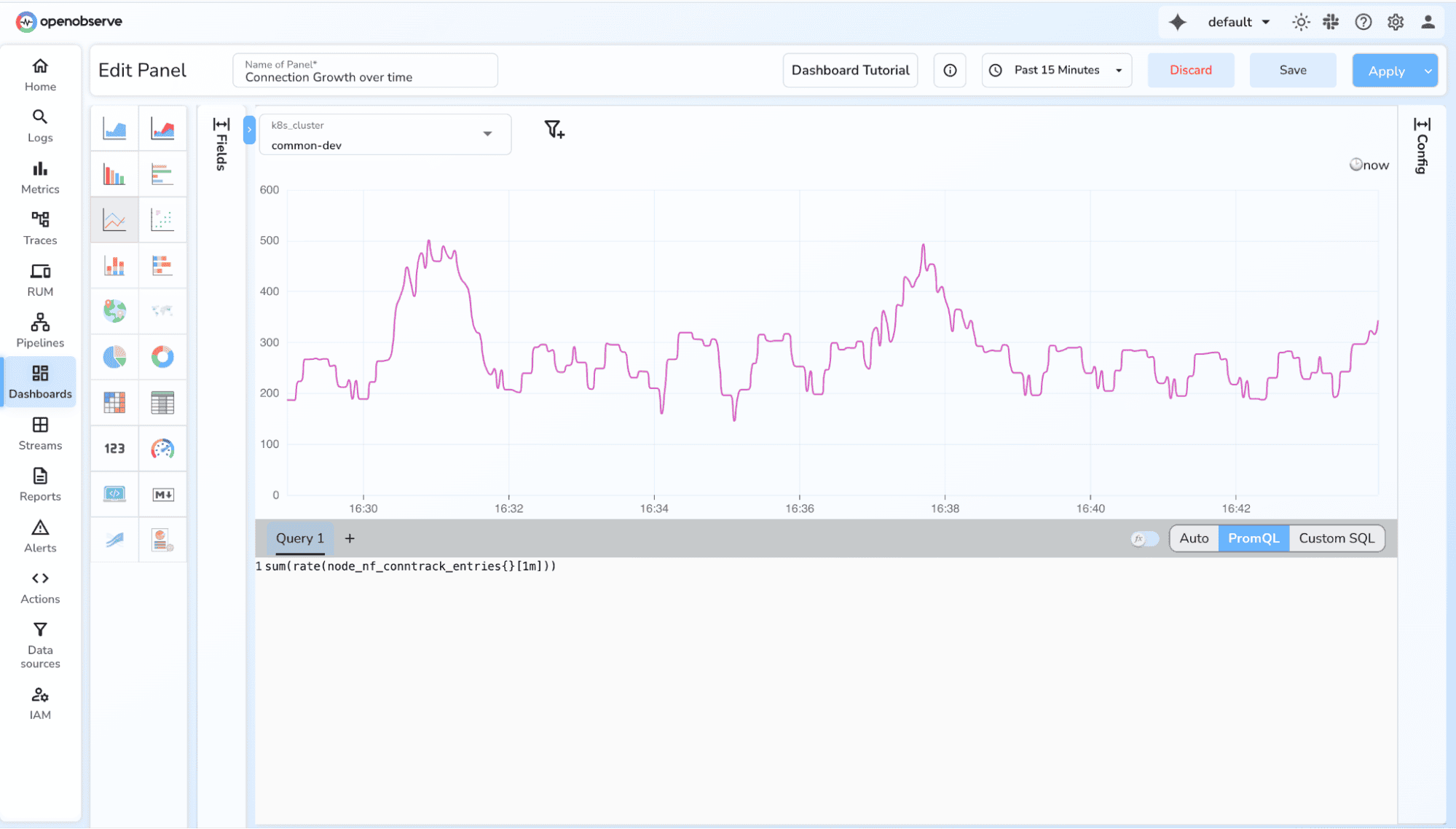
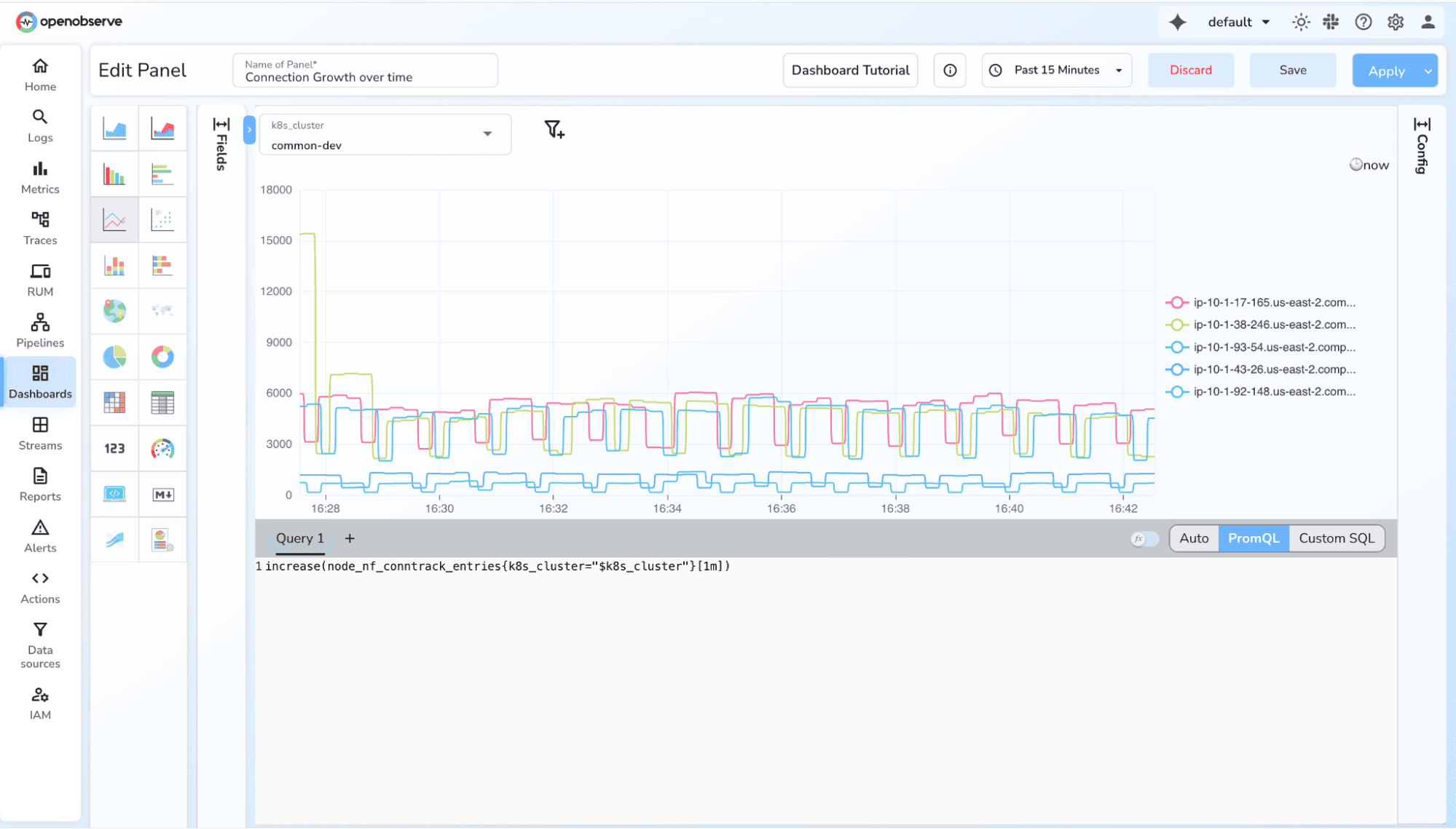
4. Breakdown by label (method, status, service)
sum(rate(http_requests_total[1m])) by (status) 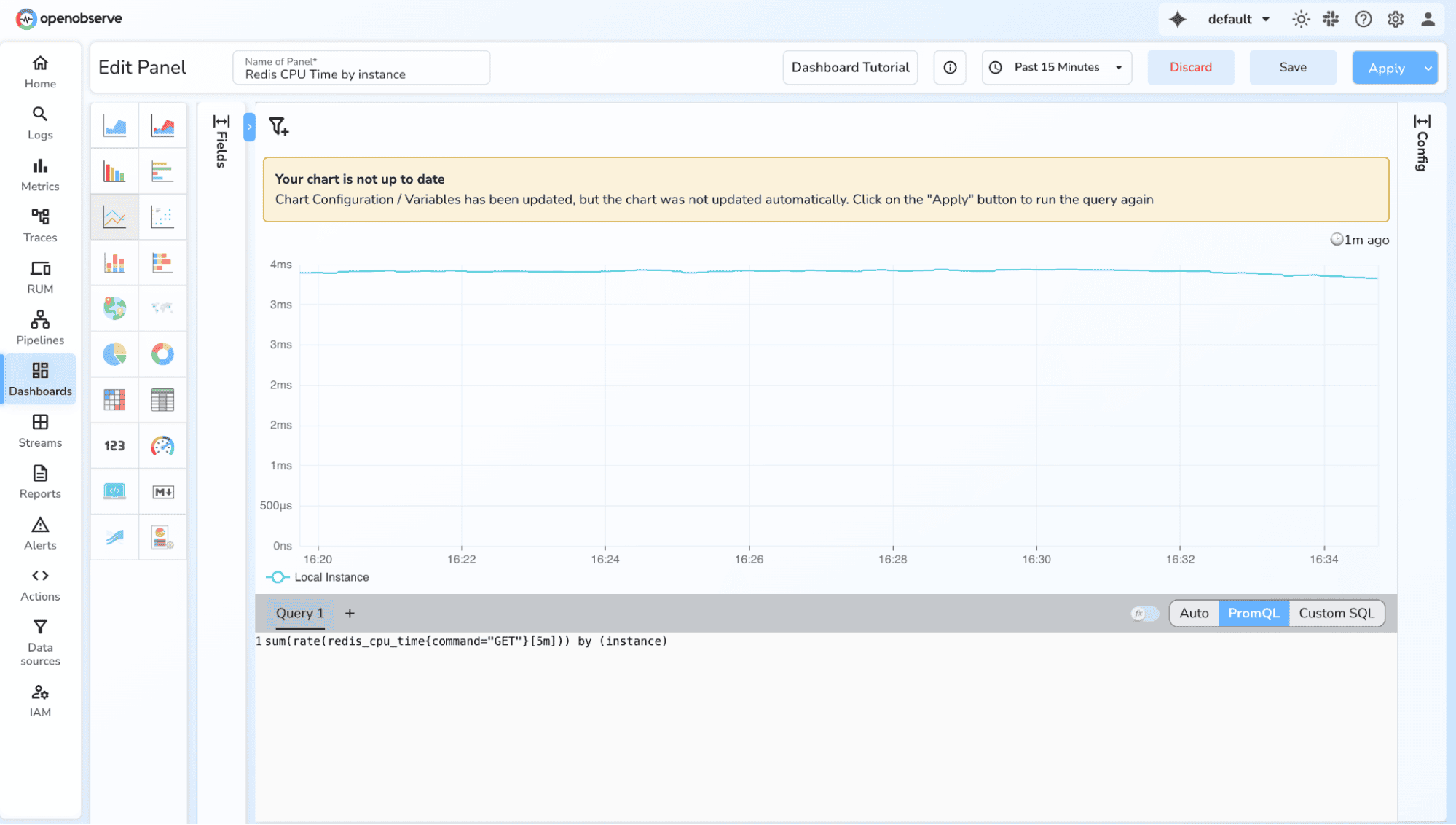
Gauge values can go up or down, so queries focus on current state, min/max, average, trends.
memory_usage_bytes
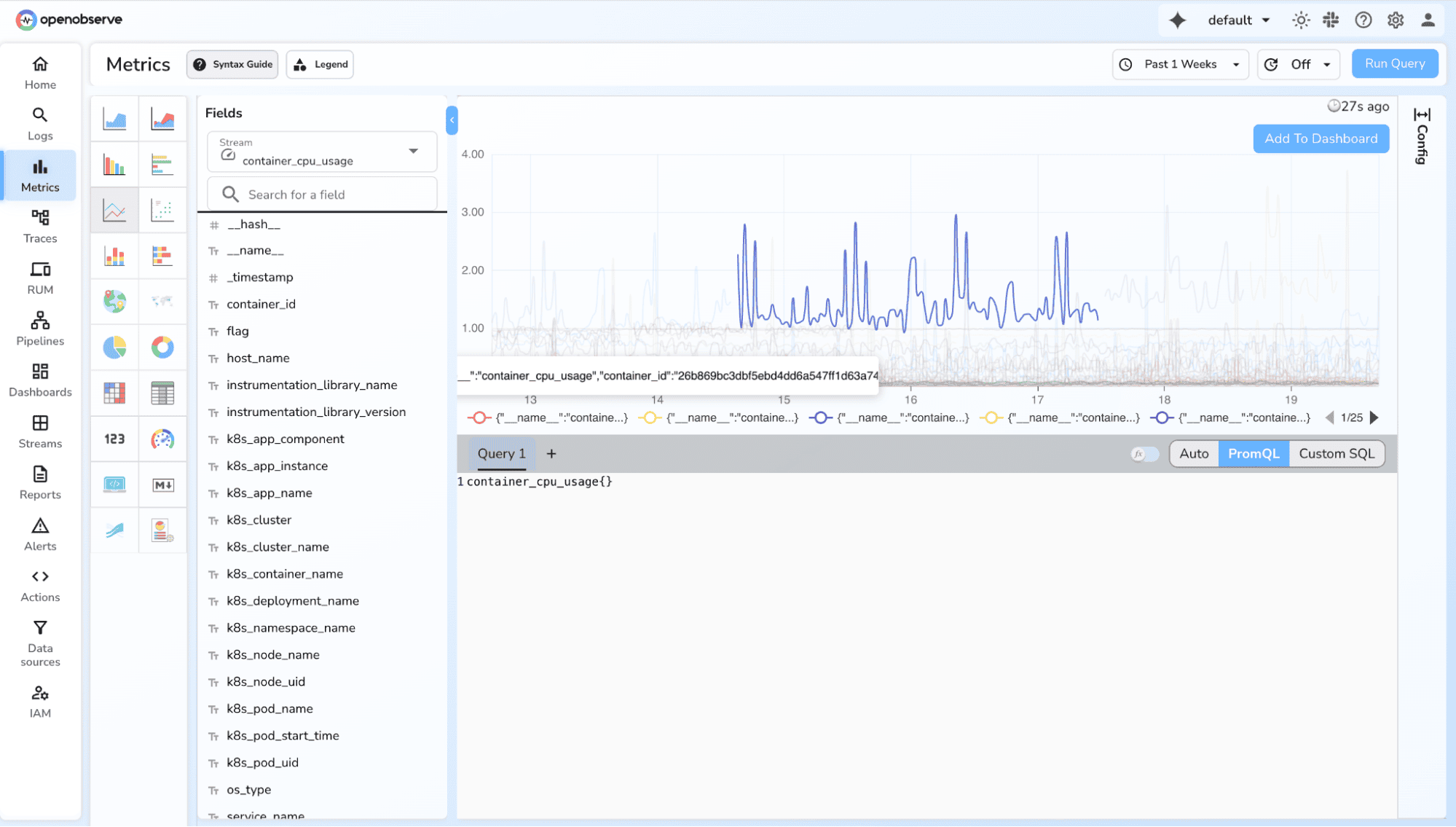
2. Average over time
avg_over_time(memory_usage_bytes[5m])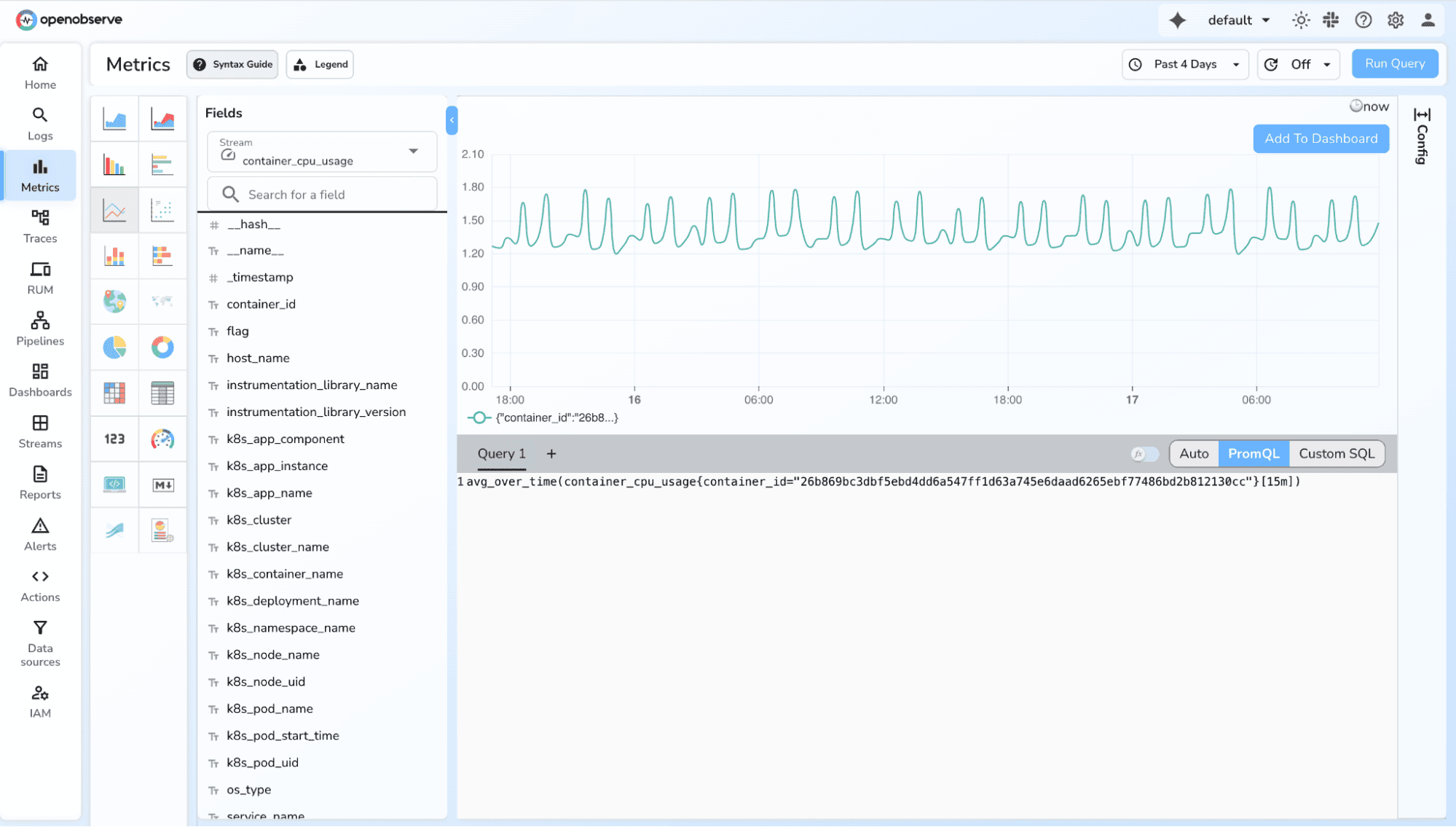
3. Minimum/maximum over a period
max_over_time(queue_depth[10m])min_over_time(queue_depth[10m])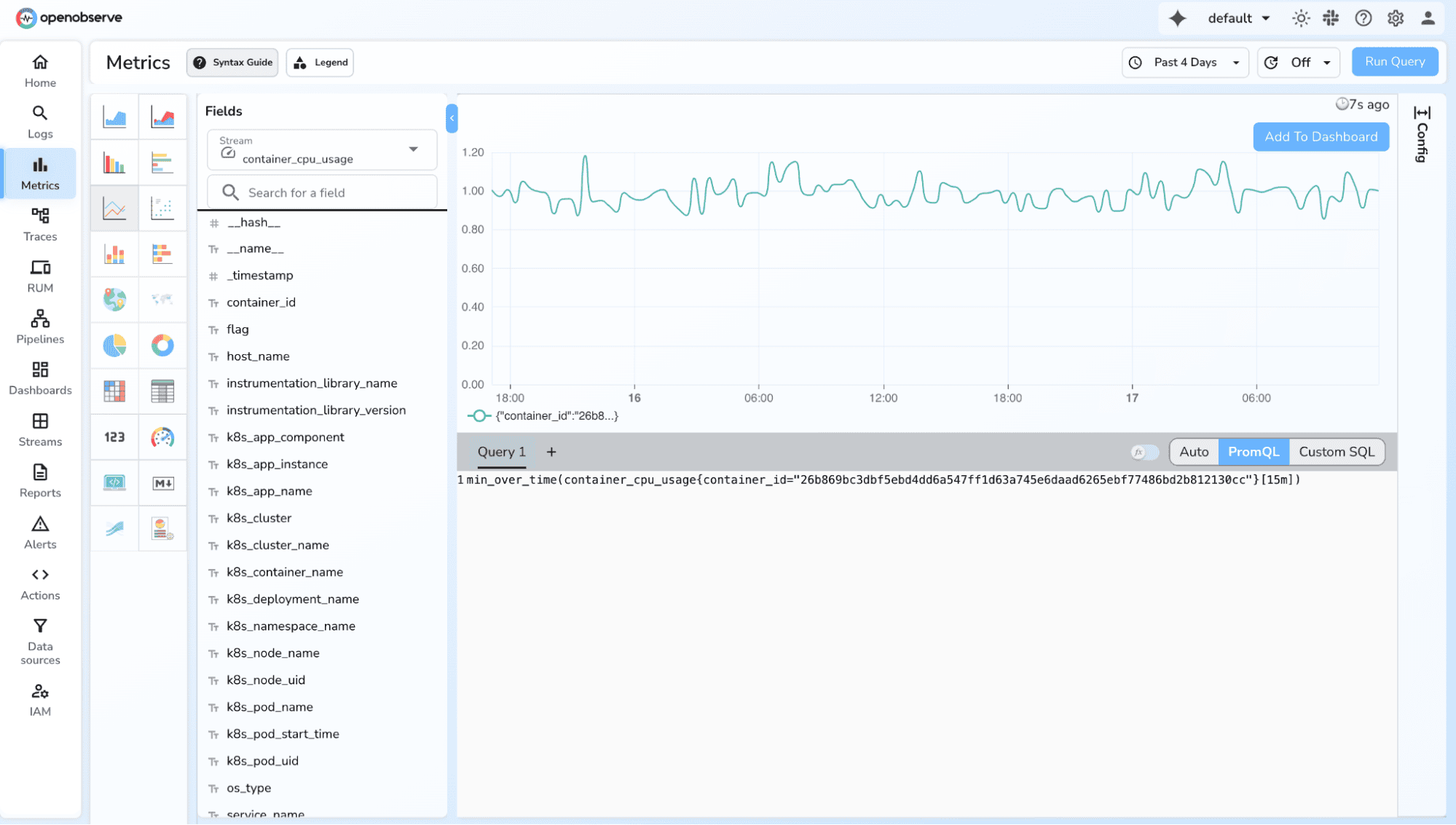
4. Derivative (rate of change)
deriv(memory_usage_bytes[5m])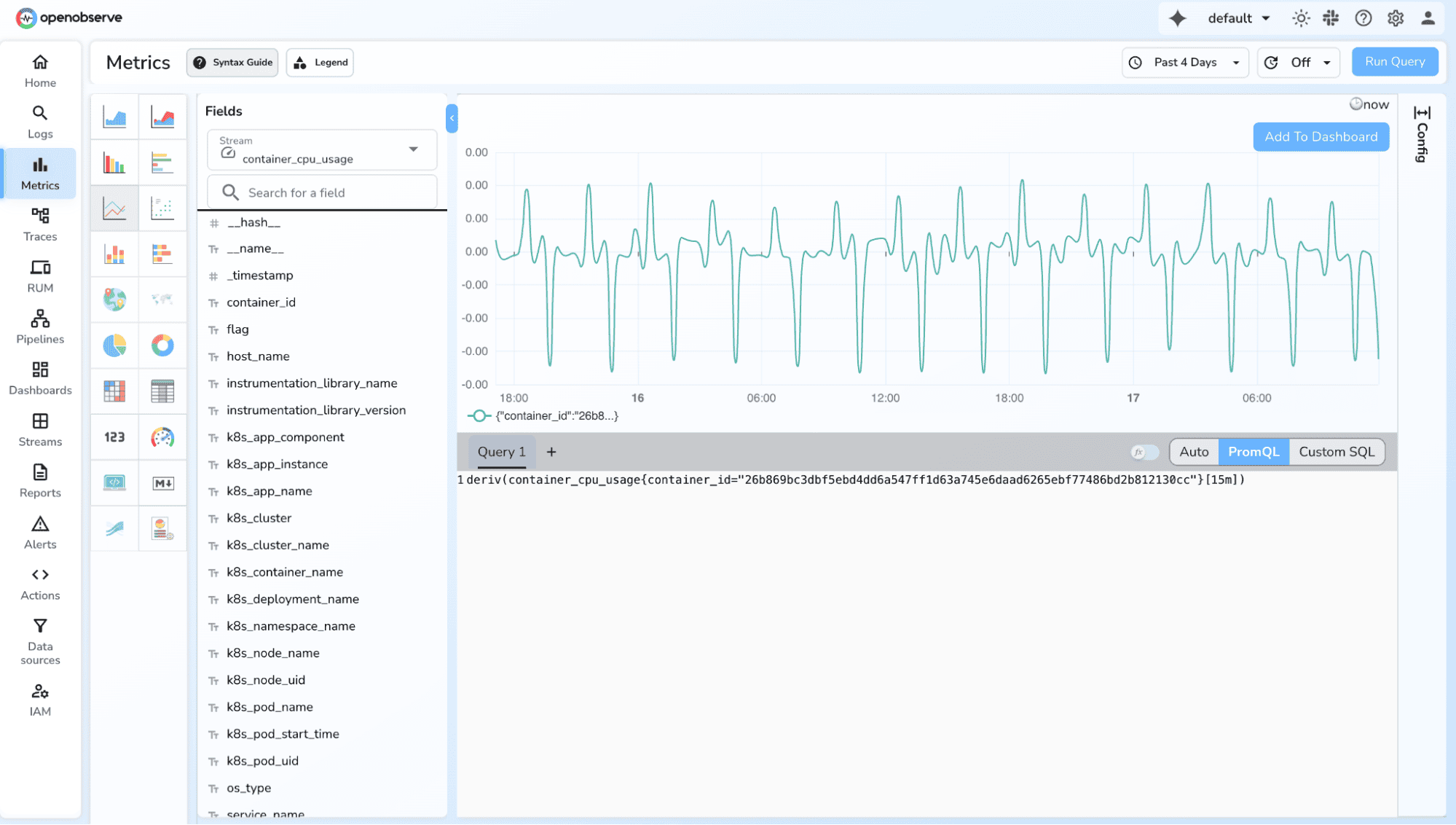
5. Grouped distribution
max(memory_usage_bytes) by (instance)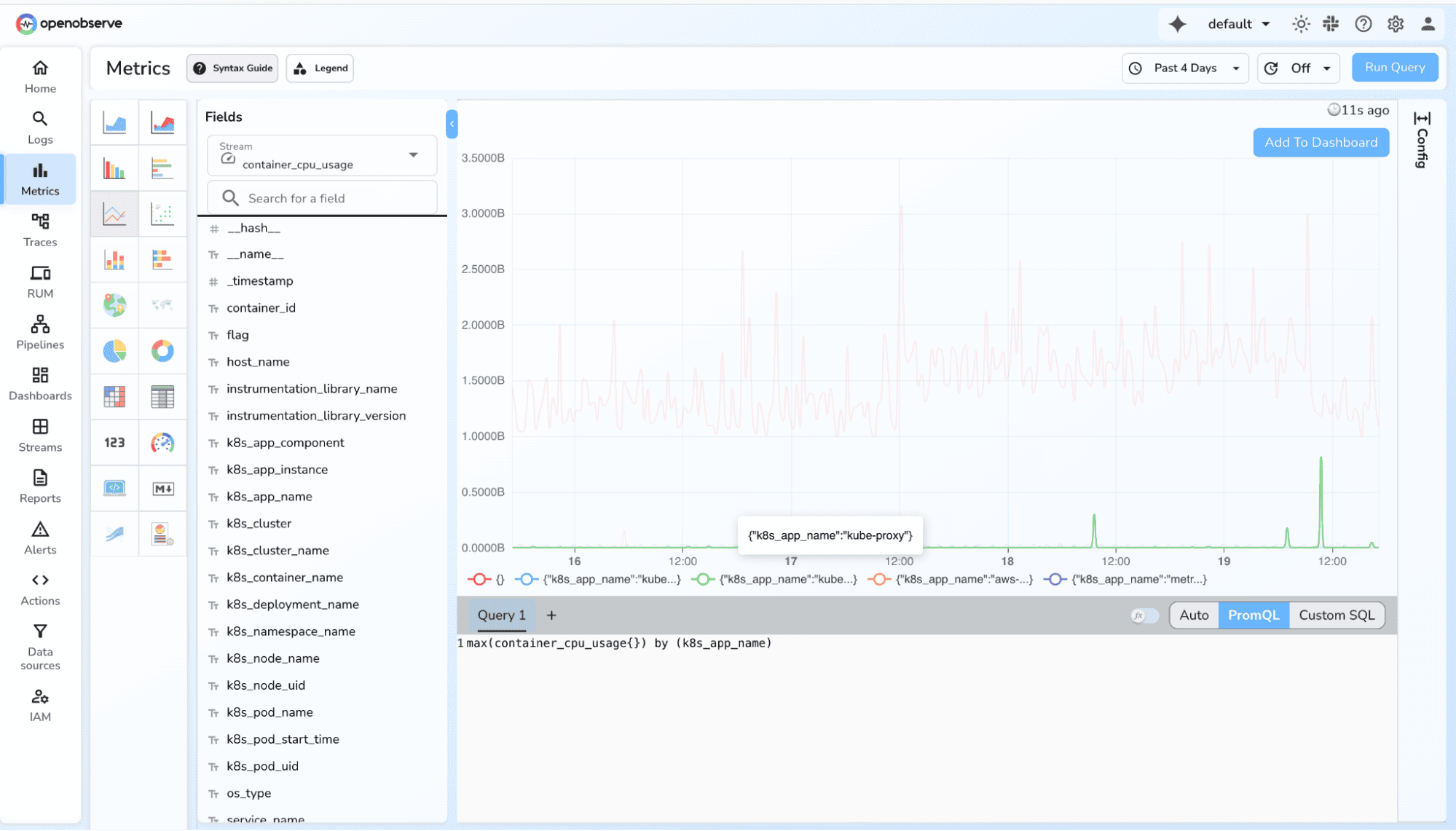
Histogram metrics expose bucket counts, sum, and count, making them ideal for analyzing latency, size distributions, and duration-based performance.
1. P90 / P95 / P99 Latency
histogram_quantile(0.95, rate(http_request_duration_seconds_bucket[5m]))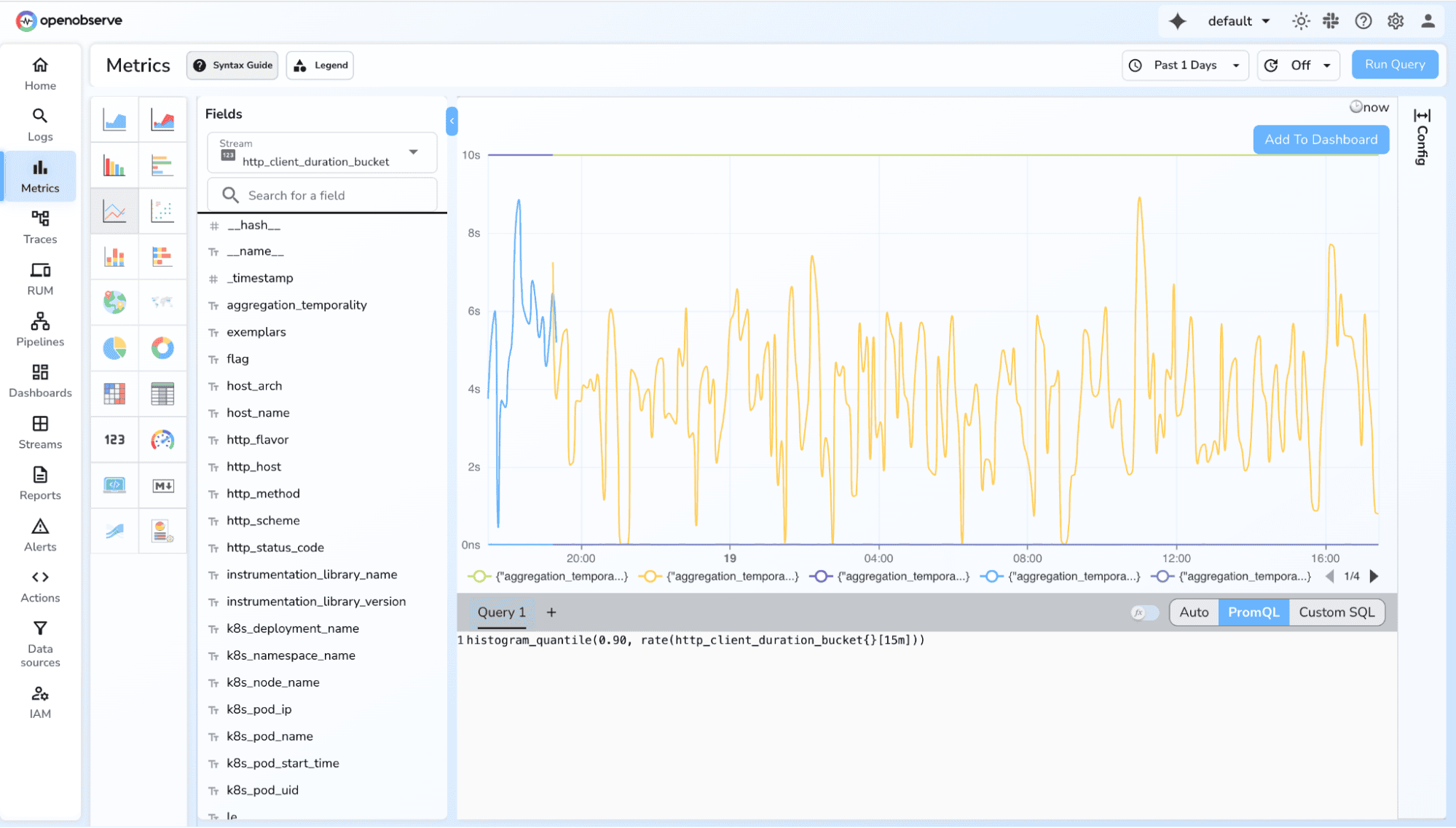
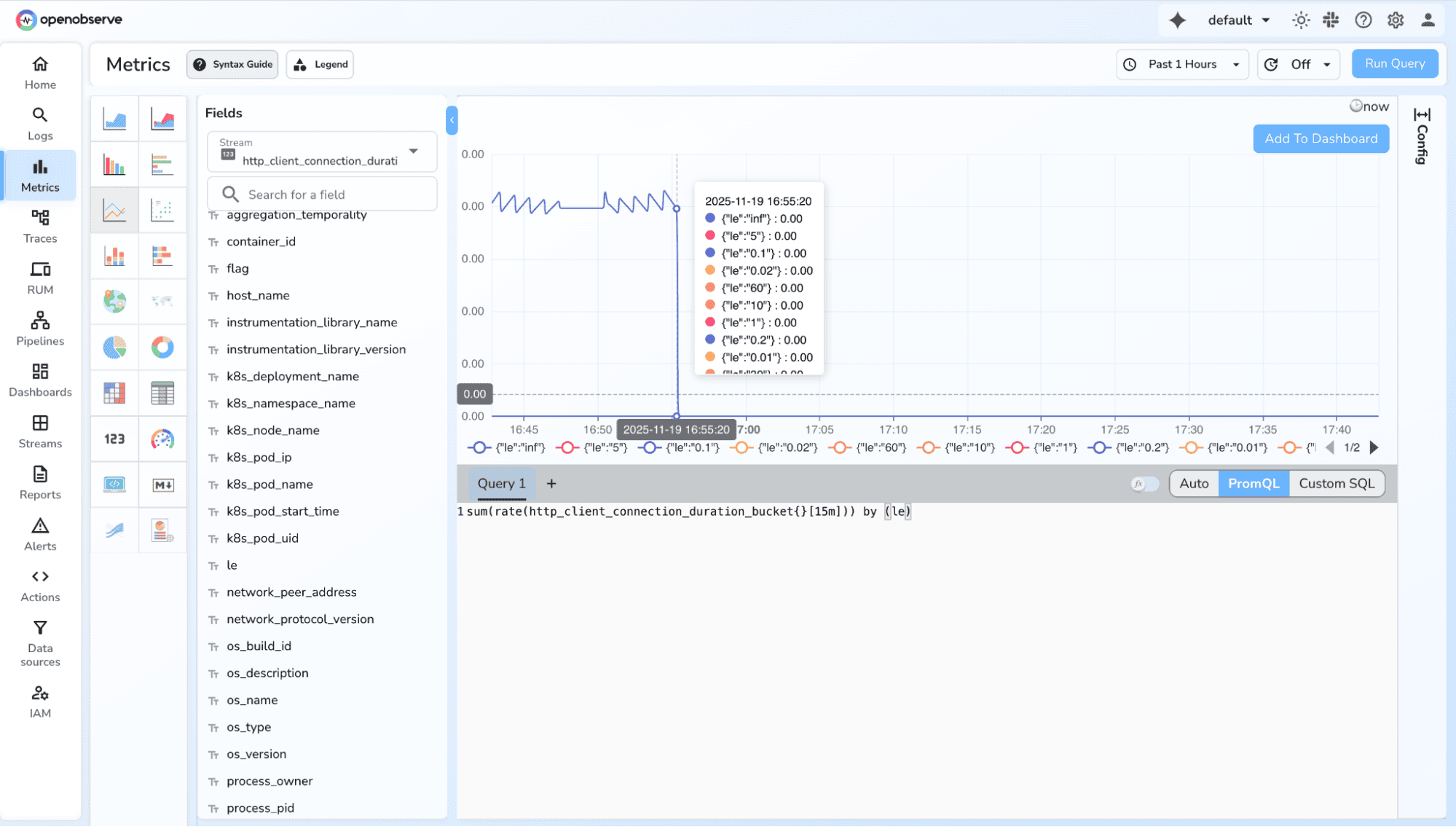
2. Full Latency Distribution
Why: See how requests spread across buckets
Example Query:
sum(rate(http_request_duration_seconds_bucket[5m])) by (le)
Summaries provide client-side quantiles, total count, and sum, useful for quantile tracking when precise percentile values are needed without buckets.
1. High-percentile latency (P90, P99)
http_request_duration_seconds2. Sum and Count Based Averages
rate(http_request_duration_seconds_sum[5m]) / rate(http_request_duration_seconds_count[5m])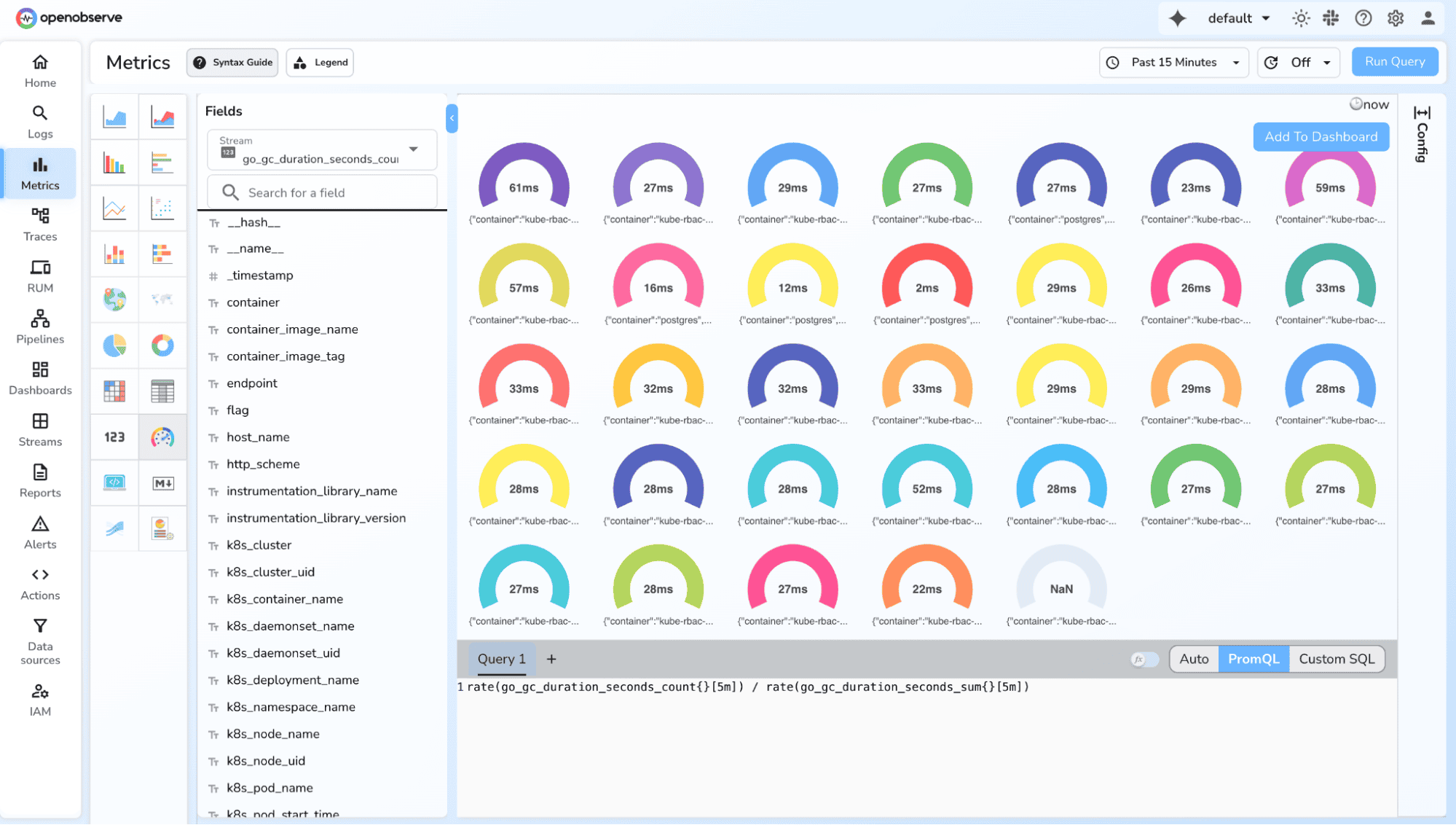
Prometheus gives you a powerful foundation for understanding your system through metrics - counters for tracking events, gauges for real-time state, histograms for latency distributions, and summaries for client-side quantiles. Once you understand how to choose and use these metric types effectively, you unlock deep visibility into your application's behavior.
But real-world observability doesn’t stop at collecting metrics; you also need long-term storage, scalable querying, and correlation across logs and traces. That’s where OpenObserve completes the story. By sending your Prometheus metrics into O2, you get limitless retention, unified dashboards, and full multi-signal observability all without the operational overhead of running extra Prometheus ecosystem components. Together, Prometheus + OpenObserve give you a complete, production-ready monitoring stack that scales with your system and makes every metric actionable.
Get Started with OpenObserve Today! Sign up for a free cloud trial.
Passionate about observability, AI systems, and cloud-native tools. All in on DevOps and improving the developer experience.












