Mean Time to Resolution (MTTR): How to Measure It and Cut It with AI-Powered Observability

Manas Sharma
March 18, 2026
20 min read
Don’t forget to share!
Try OpenObserve Cloud today for more efficient and performant observability.
It's 2:47 AM when your payment processing service starts throwing 500 errors. Customers can't complete purchases. Revenue is bleeding. Your on-call engineer wakes up to a flood of alerts from Slack, PagerDuty, and email—seventeen different alerts, all screaming that something is wrong.
But here's the question that determines whether this becomes a $50,000 or a $500,000 incident: How quickly can your team complete incident response and deploy a fix?
This is what mean time to resolution measures—and why improving your mean time to resolution has become the most critical reliability metric for engineering teams running production systems at scale. Mean time to resolution (MTTR) tracks the complete lifecycle from incident detection through root cause analysis, alert correlation, and remediation.
In 2026, the gap between high-performing teams and everyone else isn't in preventing every failure—it's in resolving failures dramatically faster. Teams using AI-powered observability for incident response achieve significant mean time to resolution reductions by eliminating manual root cause analysis and alert correlation that turns minutes into hours during critical incidents.
This guide explores what mean time to resolution is, why MTTR matters, the four phases that inflate it, and how modern teams leverage AI-assisted observability to dramatically cut resolution time.
Mean Time to Resolution (MTTR) is the average time it takes to fully resolve a production incident or system failure—from the moment an issue occurs to the moment normal service is restored.
MTTR = Total Downtime / Number of Incidents
Example: If your team experienced 10 incidents last month with a total downtime of 500 minutes: MTTR = 500 minutes / 10 incidents = 50 minutes per incident
MTTR encompasses the entire lifecycle of incident resolution:
This is critical to understand: MTTR isn't just about how fast your engineers can write a fix. It measures how long your systems stay broken—which directly translates to revenue loss, customer impact, and brand damage.
MTTR belongs to a family of related reliability metrics:
| Metric | Full Name | What It Measures |
|---|---|---|
| MTTR | Mean Time to Resolution | Total time from incident occurrence to full resolution |
| MTTD | Mean Time to Detection | How quickly you discover an incident has occurred |
| MTTA | Mean Time to Acknowledge | How quickly someone responds after detection |
| MTBF | Mean Time Between Failures | Average uptime between incidents |
While MTBF measures reliability (how often things break), MTTR measures resilience (how quickly you recover when they do).
According to a 2024 study by DevOps Research and Assessment (DORA), elite-performing engineering teams maintain MTTR below 60 minutes, while low performers average over 24 hours. The difference isn't talent—it's tooling and process.
MTTR isn't just a technical metric—it's a business-critical KPI with direct financial implications.
For revenue-generating services, every minute of downtime costs money. E-commerce platforms, SaaS applications, and financial services can lose substantial revenue during outages—from thousands to hundreds of thousands of dollars per minute depending on scale.
A simple calculation: A company with $100M annual revenue operating 24/7 loses approximately $190 per minute of downtime. With an MTTR of 120 minutes, each incident costs $22,800 in lost revenue alone.
Beyond immediate revenue, extended outages erode customer confidence. Customers may consider switching providers after significant outages, and multiple incidents correlate with higher churn rates. Brand reputation recovery from major incidents can take months.
High MTTR creates a vicious cycle:
Organizations with high MTTR consistently experience higher engineer turnover rates.
The longer an incident persists, the higher the probability of secondary failures:
Reducing MTTR isn't just about fixing things faster—it's about preventing minor incidents from becoming catastrophic disasters.
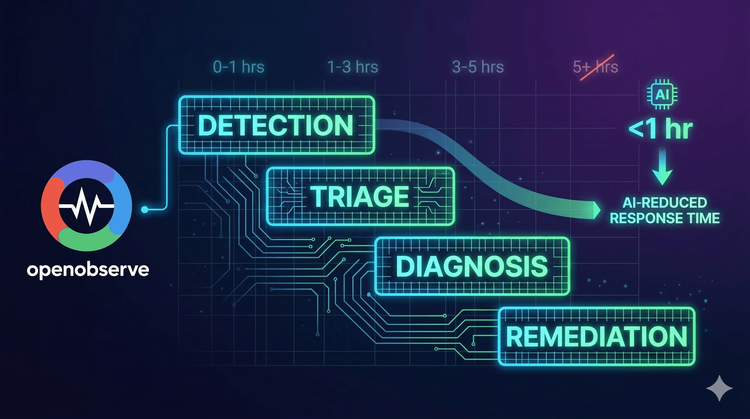
MTTR is the sum of time spent across four distinct phases. Understanding where time is lost reveals where optimization delivers the biggest impact.
The Challenge: Many incidents aren't discovered immediately. You can't fix what you don't know is broken.
Common Detection Delays:
The Cost: Every minute between failure occurrence and detection adds directly to MTTR. If it takes 15 minutes to detect an issue that takes 10 minutes to fix, your MTTR is 25 minutes—not 10.
Industry Benchmark: Elite teams achieve MTTD under 5 minutes. Average teams sit at 15-30 minutes. Low-performing teams often discover issues 2-4 hours after they occur.
The Challenge: Once you know something is wrong, you need to rapidly assess:
Common Triage Delays:
The Cost: During triage, the incident is still ongoing but the team hasn't started fixing it. Triage delays are pure waste—time spent gathering context that should be automatic.
Industry Benchmark: Best-in-class teams complete triage in under 5 minutes using automated alert correlation. Average teams spend 15-45 minutes just understanding what broke.
The Challenge: Understanding what broke is different from understanding why it broke. Diagnosis is the investigative phase where engineers hunt for root causes.
Common Diagnosis Delays:
The Cost: Diagnosis often consumes 40-60% of total MTTR. Even experienced engineers can spend hours tracing through distributed systems to find root causes.
Industry Benchmark: With traditional tooling, diagnosis takes 30-90 minutes. With AI-assisted observability, teams reduce this to 5-15 minutes.
The Challenge: Once you know the problem, you need to deploy a fix, verify it works, and confirm the system is healthy.
Common Remediation Delays:
The Cost: Even after diagnosis, remediation can add 20-60 minutes to MTTR. Every minute of deployment and verification time extends the incident.
Industry Benchmark: Elite teams with automated remediation and feature flags resolve incidents in under 10 minutes. Traditional teams average 30-60 minutes.
Here's what the incident response workflow looks like for most engineering teams in 2026:
2:47 AM - Payment service starts failing 2:52 AM - Monitoring detects anomaly (5 minutes) 2:55 AM - On-call engineer wakes up, acknowledges alert (3 minutes) 3:10 AM - Engineer reviews 34 alerts to identify affected service (15 minutes) 3:25 AM - Engineer searches logs for error patterns (15 minutes) 3:45 AM - Engineer requests database expert join call (20 minutes) 4:10 AM - Database team identifies slow query (25 minutes) 4:35 AM - Team deploys query optimization (25 minutes) 4:45 AM - Verification and incident closure (10 minutes)
Total MTTR: 118 minutes
During this incident, the team lost nearly $22,000 in revenue, affected 15,000 customer transactions, and burned two hours of engineer time at 3 AM.
Now let's see how AI-powered observability changes this equation.
Modern observability platforms leverage artificial intelligence and machine learning across all four phases of incident resolution. The result: dramatically faster detection, triage, diagnosis, and remediation.
Traditional approach: Static thresholds that generate alerts when metrics exceed predefined limits (e.g., error rate > 5%). This creates two problems:
AI-powered approach: Machine learning models establish dynamic baselines for normal system behavior and detect statistical anomalies in real-time.
How it works:
Impact: MTTD reduction from 15-30 minutes to under 5 minutes. Instead of waiting for error rates to breach static thresholds, ML models detect degradation at the first sign of deviation.
Traditional approach: Logs in Splunk, metrics in Datadog, traces in Jaeger. Engineers jump between three tools to correlate signals during incidents.
AI-powered approach: Unified observability with intelligent alert correlation groups related alerts into a single incident view.
How it works:
Impact: Triage time reduced from 15-45 minutes to under 5 minutes. Instead of manually correlating 34 alerts, engineers see a single incident with correlated context.
For detailed strategies on alert correlation, see our guide: How to Reduce MTTD and MTTR with OpenObserve's Alert Correlation.
Traditional approach: Engineers manually grep logs, query metrics, and trace request flows to identify root causes. This is the most time-consuming phase.
AI-powered approach: Intelligent assistants that analyze observability data and generate root cause hypotheses automatically.
How it works:
Modern solutions like OpenObserve with the MCP (Model Context Protocol) server enable engineers to query their entire observability dataset using natural language through AI assistants. Instead of manually searching logs and correlating metrics, AI assistants:
Impact: Diagnosis time reduced from 30-90 minutes to 5-15 minutes. What used to require deep system knowledge and hours of manual investigation happens in minutes through conversational interfaces.
For broader context on AI-powered operations, explore our comprehensive guide: Top 10 AIOps Platforms in 2026.
Traditional approach: Once root cause is identified, engineers search documentation, runbooks, or past incidents for remediation steps.
AI-powered approach: Context-aware remediation suggestions based on correlated data and historical incident patterns.
How it works:
OpenObserve's approach:
OpenObserve's correlated dashboards unify logs, metrics, and traces in a single view, enabling engineers to:
Impact: Remediation time reduced from 30-60 minutes to 10-20 minutes. Engineers spend less time figuring out what to do and more time executing fixes.
The combination of ML anomaly detection, unified observability, AI-assisted diagnosis, and intelligent remediation delivers significant MTTR improvements:
MTTR is only useful if you measure it consistently. Track incident timestamps from start to resolution and calculate:
MTTR = Sum of (Resolution Time - Incident Start Time) / Number of Incidents
Example: 5 incidents with durations of 88, 33, 85, 23, and 65 minutes = 294 total minutes / 5 incidents = 58.8 minutes MTTR
Best practices:
While AI-powered observability delivers the biggest impact, these strategies amplify results:
Feature Flags for Instant Rollback: Disable problematic features without deploying new code, reducing remediation time from 20-30 minutes to under 1 minute.
Chaos Engineering: Proactively inject failures to test detection and recovery. This builds incident response muscle memory and familiarity with failure patterns.
Service Ownership and Runbooks: Clear ownership reduces triage time. Documented runbooks with debugging commands and dashboard links accelerate diagnosis and remediation.
Automated Remediation: Identify predictable incident patterns and automate fixes (auto-restart, auto-scale, cache clearing). Start with low-risk automations and include circuit breakers.
Post-Incident Reviews: Blameless postmortems reveal what slowed detection, diagnosis, and remediation. Track action items and measure MTTR improvements for similar incident types.
Understanding where you stand helps set realistic improvement targets.
Based on DORA's 2024 State of DevOps Report and industry data:
| Performance Tier | MTTR | Characteristics |
|---|---|---|
| Elite | < 1 hour | AI-powered observability, automated remediation, chaos engineering |
| High | 1-4 hours | Good instrumentation, clear ownership, runbooks |
| Medium | 4-24 hours | Basic monitoring, manual investigation, unclear ownership |
| Low | > 24 hours | Reactive monitoring, limited instrumentation, siloed teams |
Different industries have different expectations:
| Industry | Median MTTR | Notes |
|---|---|---|
| Financial services | 15-30 min | High stakes, extensive automation |
| E-commerce | 30-60 min | Revenue-critical, strong observability |
| SaaS platforms | 45-90 min | Varies by company maturity |
| Healthcare | 2-4 hours | Slower due to compliance requirements |
| Enterprise IT | 4-8 hours | Legacy systems, change control processes |
Don't aim for perfection immediately. Set incremental targets:
Current MTTR: 120 minutes
Focus on the phases consuming the most time. If diagnosis takes 60 of your 120 minutes, that's where AI-assisted observability delivers maximum impact.
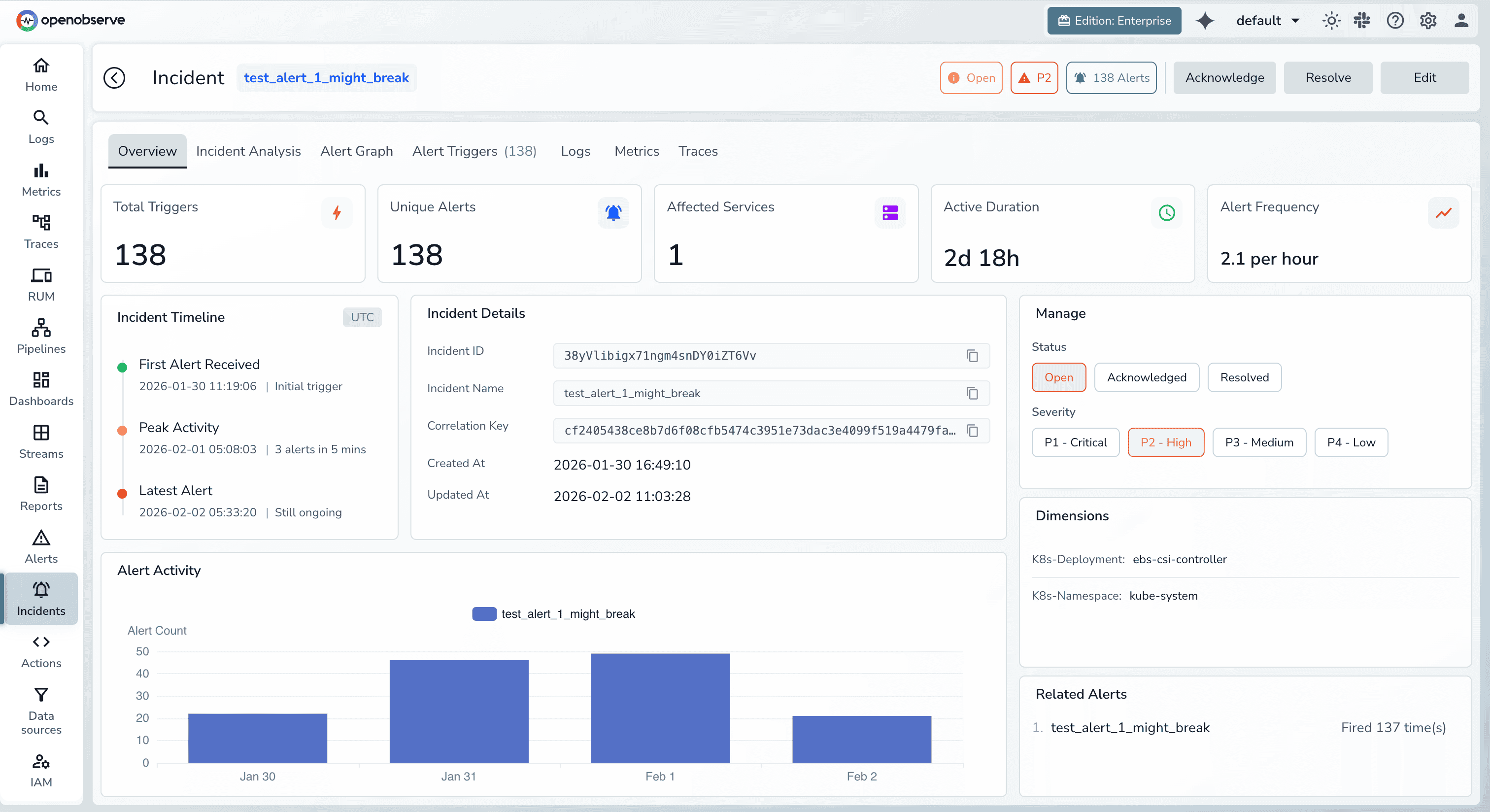
AI-powered incident response is only as good as the data it analyzes. This creates a fundamental challenge: complete observability data is expensive.
Traditional platforms (Splunk, Datadog, Dynatrace) charge per GB ingested, forcing teams to:
Every cost-saving measure degrades AI effectiveness. The anomaly you need to detect might be in the data you didn't capture.
OpenObserve was architected to solve this problem. By using columnar storage (Parquet), aggressive compression, and efficient indexing, OpenObserve delivers 140x lower storage costs than legacy platforms.
This economic advantage unlocks a fundamentally different approach to MTTR optimization:
1. Full-fidelity telemetry becomes affordable
Ingest 100% of logs, metrics, and traces without sampling. AI models analyze complete datasets, eliminating blind spots that delay diagnosis.
2. Unified logs, metrics, and traces accelerate triage
No more jumping between tools during incidents. OpenObserve correlates all telemetry signals in a single platform, surfacing related alerts and evidence instantly.
3. The OpenObserve MCP server enables conversational diagnosis
Engineers query live production data using natural language through AI assistants. This conversational interface to observability data eliminates the manual investigation that typically consumes 40-60% of MTTR.
4. Correlated telemetry reveal remediation paths instantly
When root cause is identified, OpenObserve automatically surfaces:
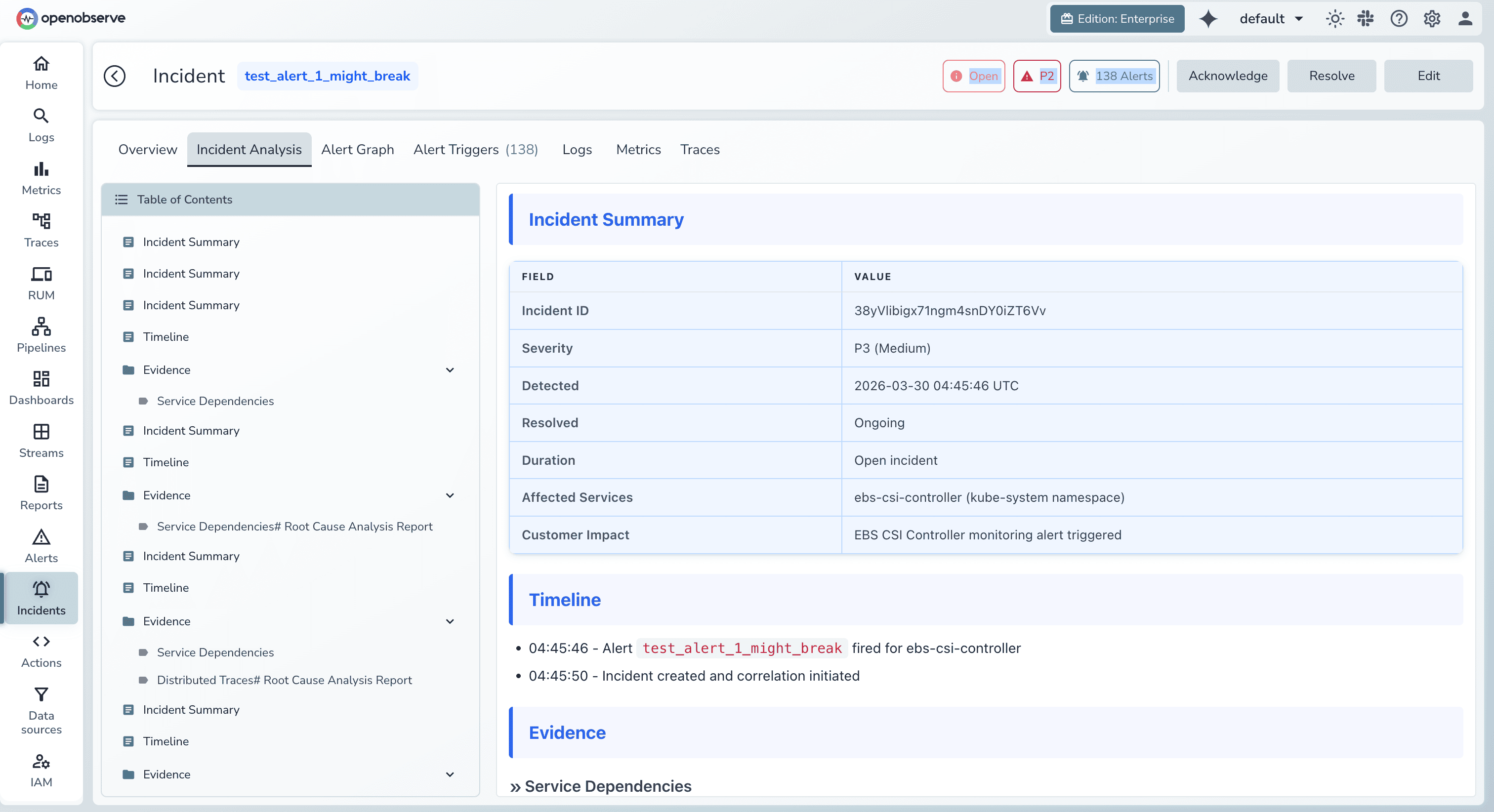
5. Transparent AI reasoning builds trust
OpenObserve's AI doesn't operate as a black box. Engineers can review:
This transparency doesn't just build confidence—it helps engineers learn and improve their own troubleshooting skills.
For detailed implementation strategies, see: How to Reduce MTTD and MTTR with OpenObserve's Alert Correlation.
Looking ahead, the next frontier in MTTR optimization is autonomous incident resolution—systems that detect, diagnose, and remediate common failures without human intervention.
Modern AIOps platforms are evolving toward agentic AI systems that:
Gartner predicts that by 2028, 40% of routine production incidents will be resolved autonomously by AI agents, reducing MTTR for these incidents to under 5 minutes.
Future systems won't just resolve incidents—they'll prevent recurrence:
For organizations ready to embrace this future, the foundation is clear: invest in comprehensive, cost-efficient observability that feeds AI models with full-fidelity data.
Explore the broader context of AI-powered operations: Top 10 AIOps Platforms in 2026.
Mean time to resolution (MTTR) is the average time it takes to fully resolve a production incident or system failure, measured from when an issue occurs to when normal service is restored. It encompasses detection, triage, diagnosis, and remediation.
Calculate MTTR using this formula: MTTR = Total Downtime / Number of Incidents. For example, if you had 5 incidents with durations of 88, 33, 85, 23, and 65 minutes, your MTTR is 294 minutes / 5 incidents = 58.8 minutes.
Elite-performing teams maintain MTTR below 60 minutes, high performers average 1-4 hours, medium performers 4-24 hours, and low performers exceed 24 hours. Industry varies: financial services targets 15-30 minutes, e-commerce 30-60 minutes, and SaaS platforms 45-90 minutes.
MTTR (Mean Time to Resolution) measures total time to resolve an incident, while MTTD (Mean Time to Detection) measures only how quickly you discover an incident has occurred. MTTD is a component of MTTR—you can't resolve what you haven't detected.
Reduce MTTR through: (1) ML-powered anomaly detection for faster detection, (2) unified observability and alert correlation for faster triage, (3) AI-assisted root cause analysis for faster diagnosis, (4) automated remediation and feature flags for faster fixes. AI-powered observability platforms can significantly reduce MTTR across all four phases.
High MTTR stems from four phases: slow detection (15-30 min) from static thresholds and alert fatigue, slow triage (15-45 min) from alert storms and data silos, slow diagnosis (30-90 min) from manual log searching and trace sampling gaps, and slow remediation (20-60 min) from complex deployments and manual verification.
MTTR directly impacts business outcomes: revenue loss (companies lose $190+ per minute of downtime), customer trust (25% consider switching after one outage), engineering productivity (teams with MTTR over 4 hours see 60% higher turnover), and compound failure risk (longer incidents increase probability of cascading failures).
AI reduces MTTR across all four phases: ML anomaly detection accelerates detection through dynamic baselines instead of static thresholds, alert correlation speeds triage by automatically grouping related alerts, AI-assisted diagnosis accelerates root cause analysis through conversational interfaces to observability data, and intelligent remediation speeds fixes through historical incident matching and automated runbooks.
Mean Time to Resolution isn't just a metric—it's a measure of your organization's ability to maintain reliability under pressure. In 2026, the teams winning on MTTR aren't the ones with the best engineers—they're the ones with the best observability foundations and AI-powered tooling.
Every minute of MTTR reduction translates to:
New to OpenObserve? Register for our Getting Started Workshop for a quick walkthrough.
Try OpenObserve: Download for self-hosting or sign up for OpenObserve Cloud with a 14-day free trial.
Manas is a passionate Dev and Cloud Advocate with a strong focus on cloud-native technologies, including observability, cloud, kubernetes, and opensource. building bridges between tech and community.












