Sensitive Data Redaction in OpenObserve: How to Redact, Hash, and Drop PII Data Effectively

Manas Sharma
November 07, 2025
8 min read
Don’t forget to share!
Try OpenObserve Cloud today for more efficient and performant observability.

As organizations scale their observability systems, the volume of logs, metrics, and traces captured across services continues to grow exponentially. These records often contain more than just operational data, they may inadvertently include sensitive information such as user emails, IP addresses, access tokens, or payment identifiers.
In regulated industries, this creates an immediate compliance challenge. Frameworks like GDPR, HIPAA, and SOC 2 require organizations to ensure that sensitive data is protected, stored responsibly, and never exposed unintentionally.
Traditional observability stacks rely on developers to filter such data within their applications before it’s ingested. But with distributed systems, this approach doesn’t scale as it’s hard to predict where sensitive values may appear.
To address this, OpenObserve Enterprise edition introduces Sensitive Data Redaction (SDR) — a native feature that identifies and protects sensitive data automatically at ingestion or query time. It enables teams to maintain complete visibility while staying compliant and secure.
Every request, event, or trace emitted by your systems can potentially contain personally identifiable information (PII) or secrets. This can happen unintentionally, for example:
Once such data lands in your observability store, it becomes searchable, visualized on dashboards, and sometimes shared across teams amplifying privacy risks.
Manually cleaning up or rewriting this data later is difficult. External scrubbing tools often introduce latency, require additional infrastructure, and may miss dynamically generated fields.
OpenObserve Enterprise eliminates this problem by providing built-in redaction capabilities that operate directly in the data pipeline, ensuring protection from the moment data arrives or is queried.
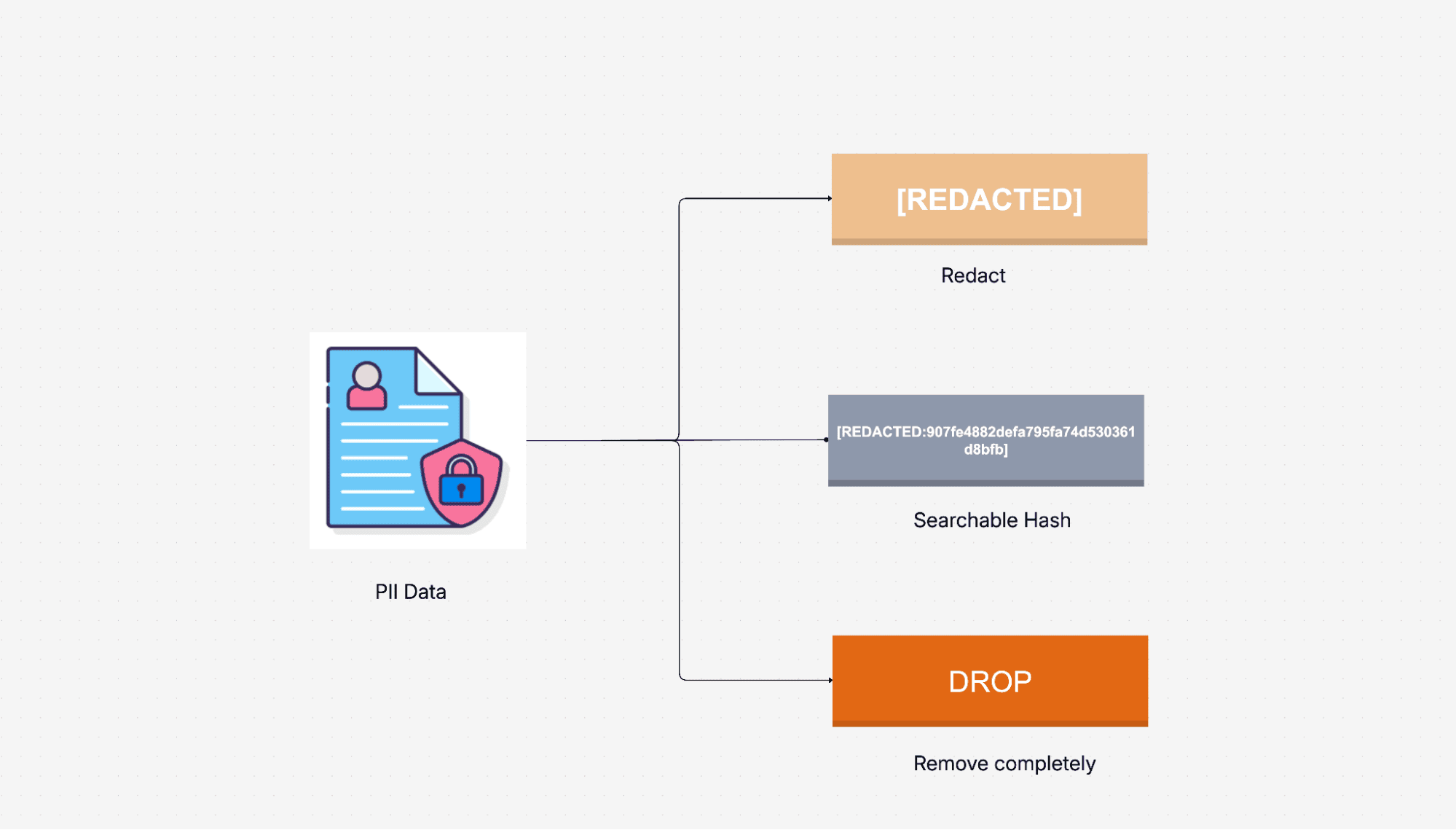
Sensitive Data Redaction (SDR) in OpenObserve works by inspecting data for patterns that match defined regular expressions (regex). Once matched, the system applies a user-defined action: redact, hash, or drop.
Each of these actions has a distinct purpose:
Redact: Replace the matched content with a placeholder like [REDACTED].
Hash: Sensitive data is read from storage and replaced with a deterministic MD5 hash, such as [REDACTED:12314HASH]. This ensures consistency between records while keeping data anonymized for display or correlation.
Drop: Remove the sensitive field or value entirely.
Redaction rules can run at two different stages:
The SDR engine is powered by Intel Hyperscan, a high-performance regex engine optimized for multi-threaded workloads. This ensures minimal latency and near real-time throughput, even at enterprise-scale ingestion rates.
Redaction can happen either before data is written (ingestion-time) or when data is read (query-time). Each mode serves a different operational goal.
When applied at ingestion, sensitive values are redacted, hashed, or dropped before being persisted. This means:
For example, an email like jane.doe@example.com becomes [REDACTED] before reaching storage. Even administrators with direct access to the data cannot retrieve the original value.
Query-time protection operates differently. Sensitive data is still stored but masked dynamically when queried.
For instance, a credit card number may remain stored internally but displayed as [REDACTED] when accessed through the query interface.
Each redaction action serves a unique role in managing data exposure risk.
Replaces sensitive content with a placeholder (e.g., [REDACTED]) while preserving context.
This is useful when you want to retain log readability — such as debugging messages — without storing private values.
Example:
Before: "User john@example.com logged in"
After: "User [REDACTED] logged in"
The matched value is replaced with a deterministic MD5 hash, for example [REDACTED:12314HASH].
This makes the value unreadable but still searchable using its hashed equivalent. It allows security and operations teams to trace repeated occurrences without accessing the original sensitive information.
Example:
Before: "Credit Card:4111-1111-1111-1111"
After: "Credit Card:[REDACTED:907fe4882def....]"
Completely removes the field or value before it’s stored or displayed. Use this when you want to ensure certain data (like passwords or tokens) never persists in your observability store.
OpenObserve’s redaction system is fully configurable through its management UI, refer to below steps:
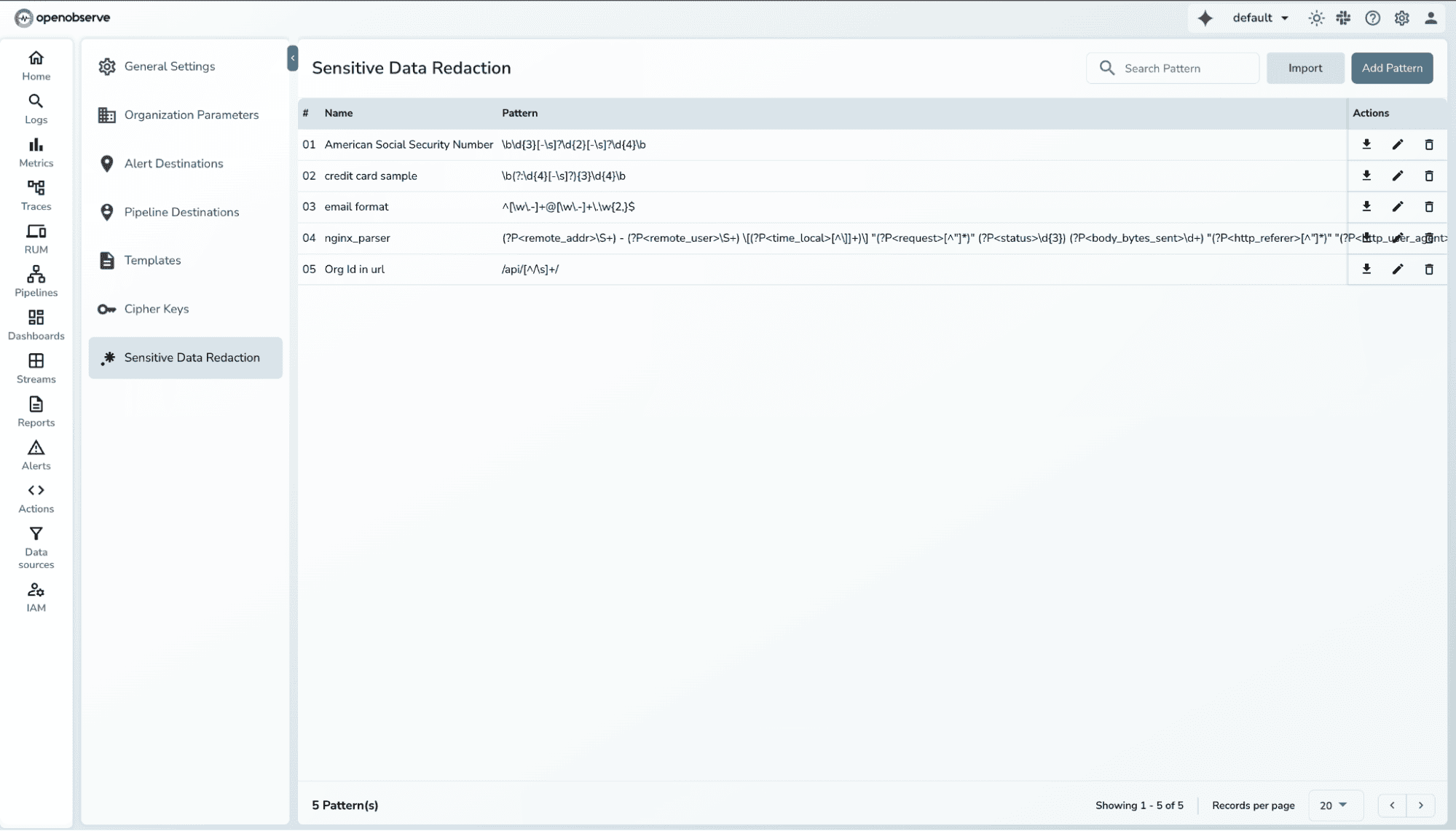
Click Create Pattern to define a new regex rule.
Enter a regex expression that identifies the target data (e.g., email addresses, IPs).
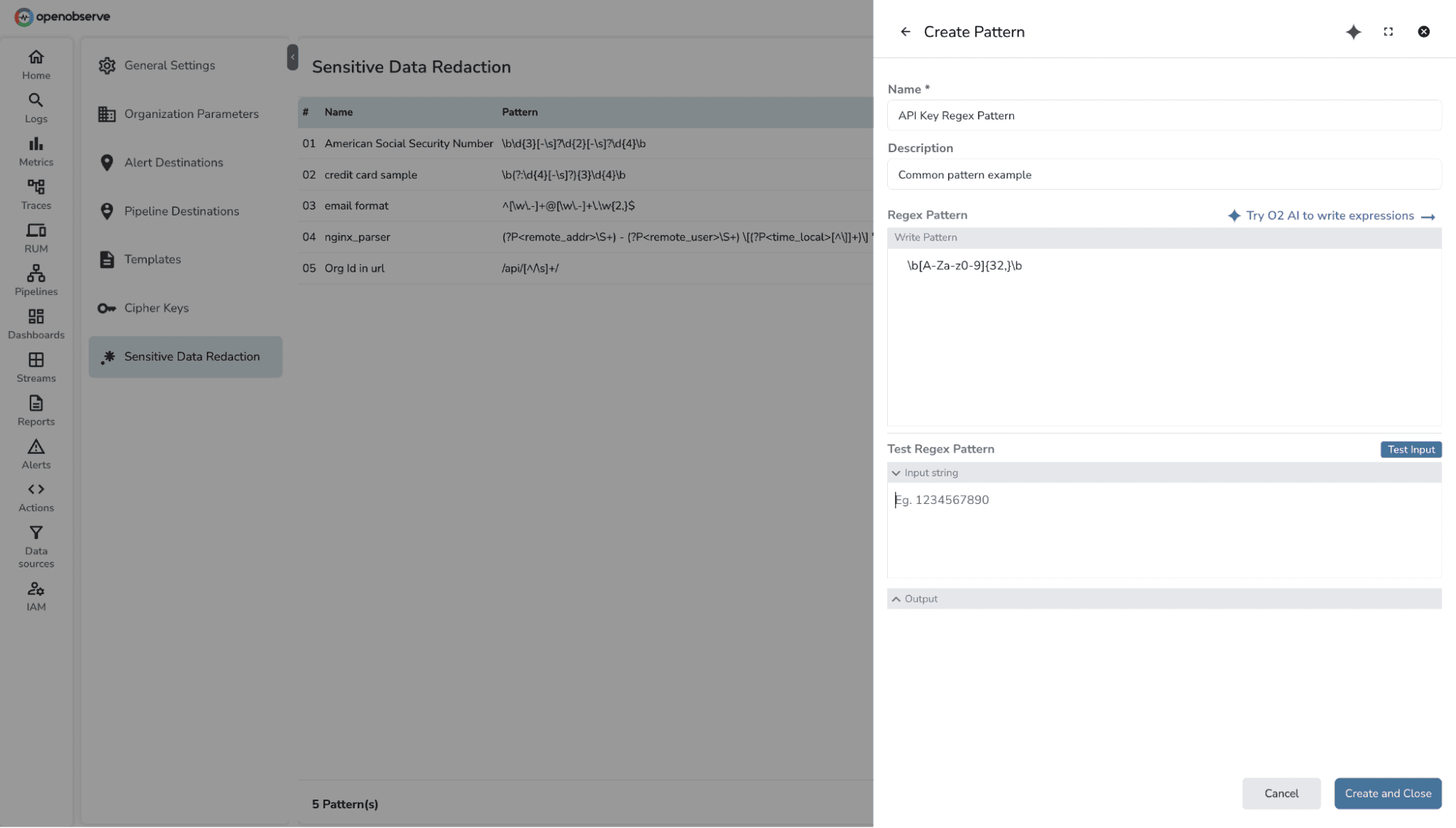
![[REDACTED] output based on regex pattern](https://openobserve.ai/assets/image5_a5a8336b0d.png)
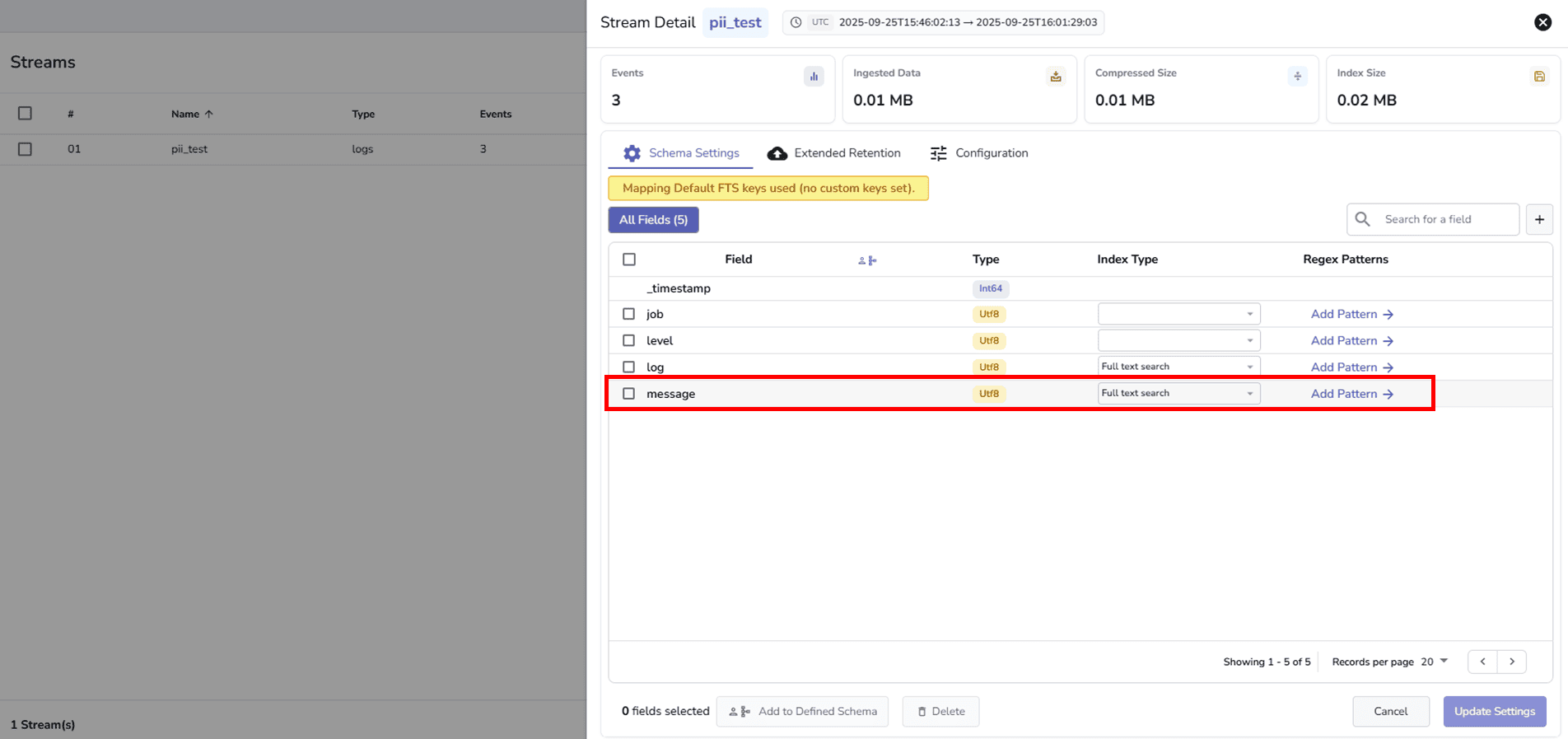
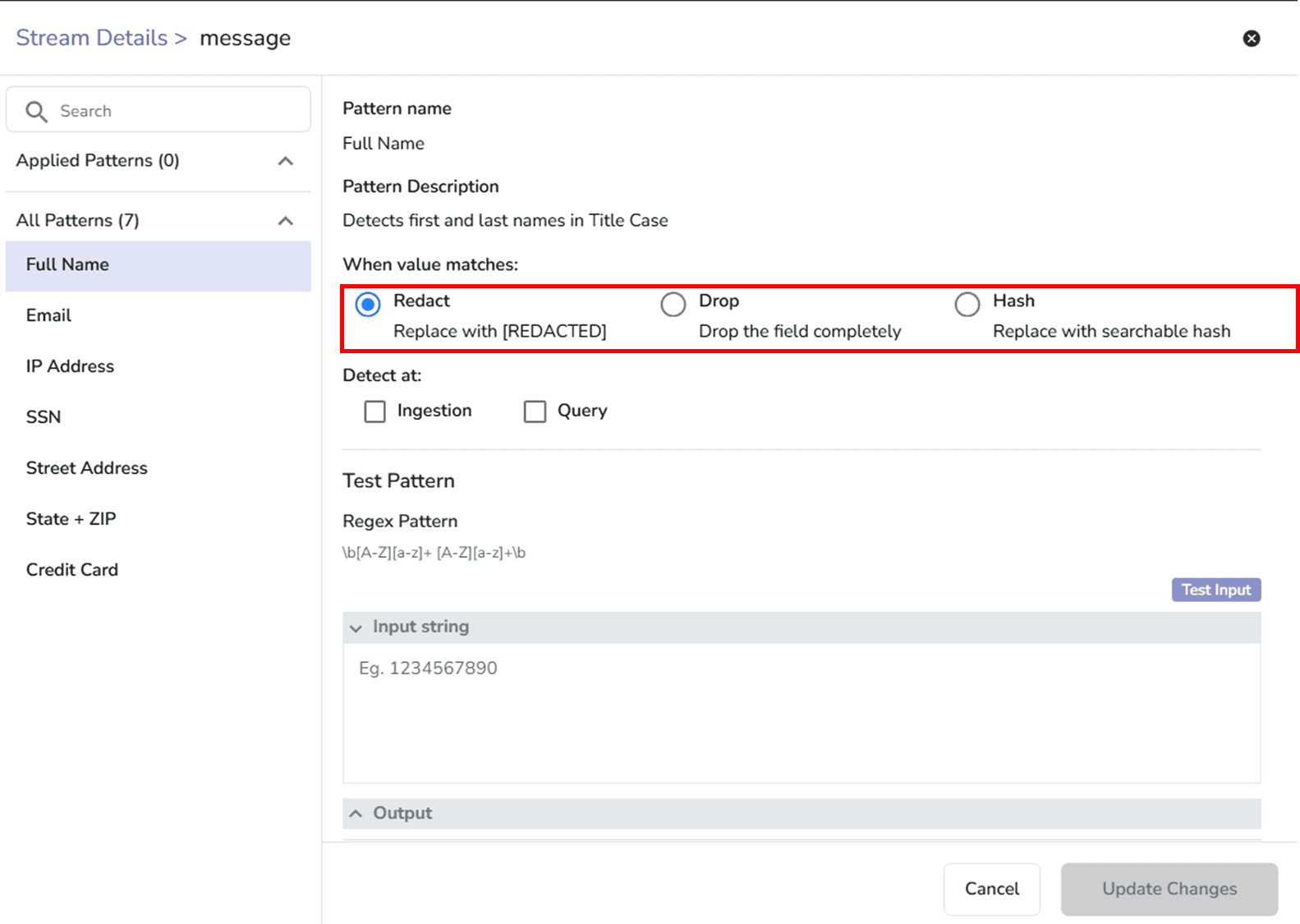
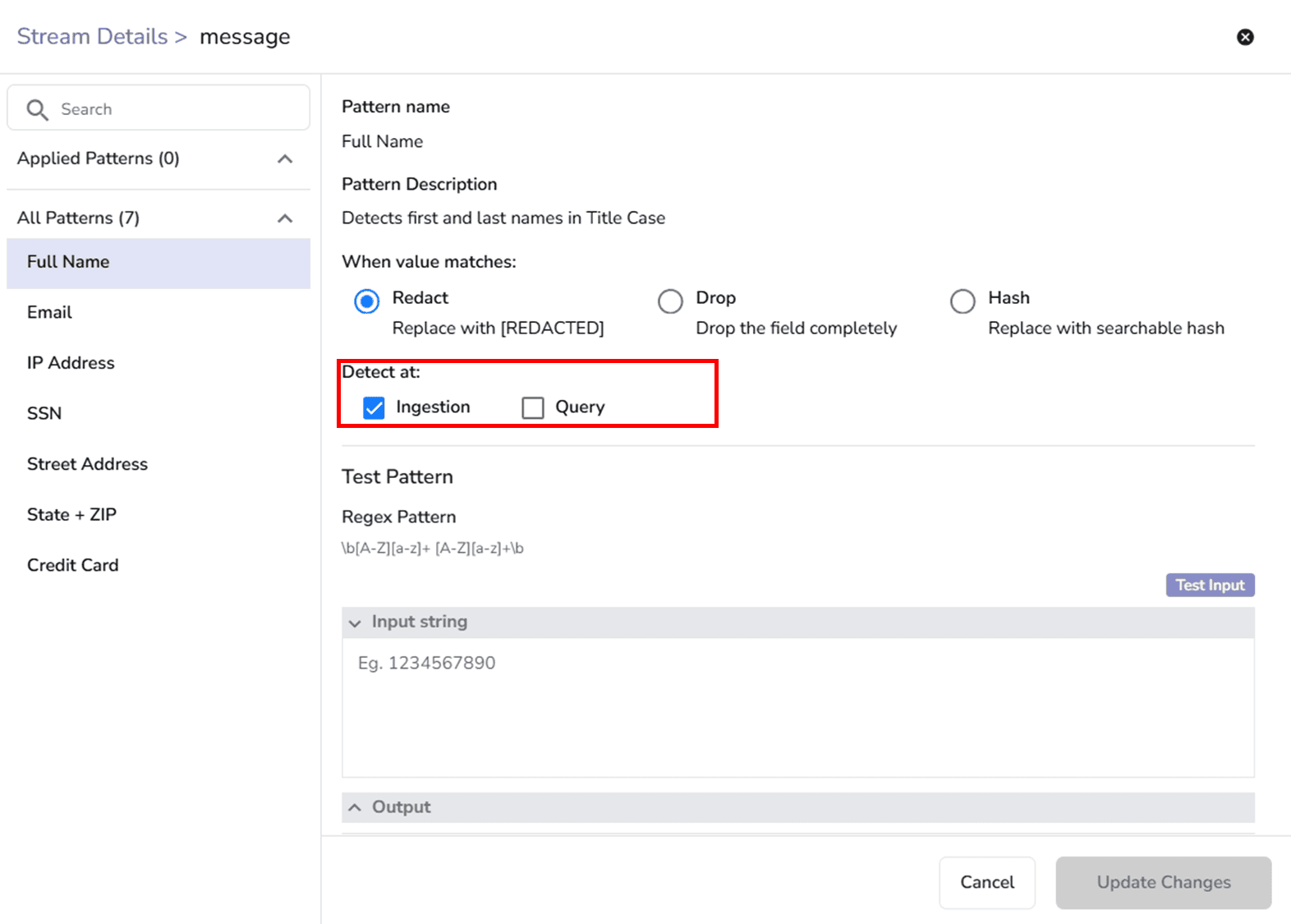
You can attach multiple patterns to the same stream. This makes it easy to maintain different policies for various data types (e.g., emails, tokens, IPs).
Sensitive data management must be restricted to authorized users. OpenObserve Enterprise integrates SDR directly with its IAM and RBAC system to maintain security boundaries.
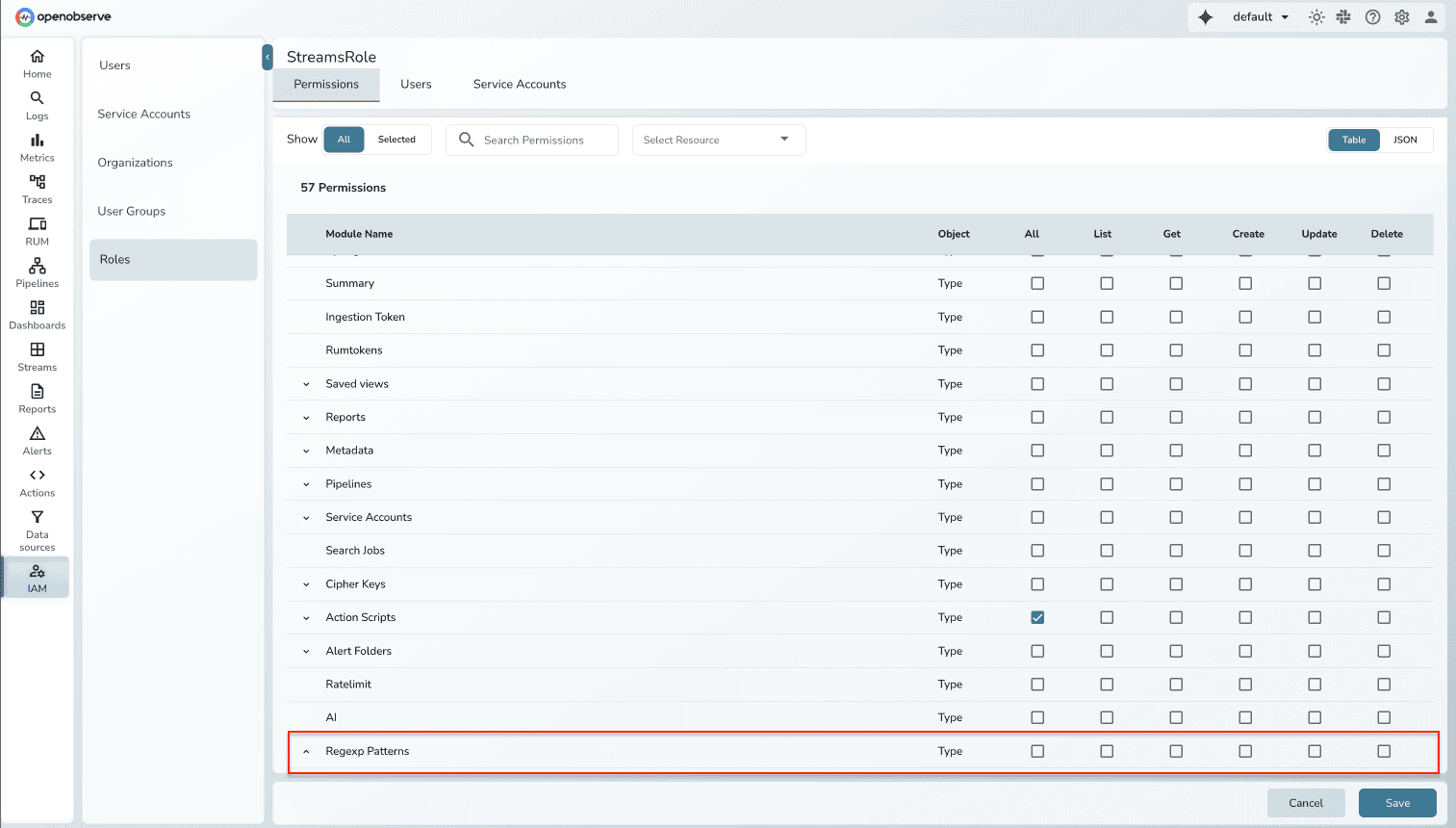
This ensures that pattern creation and rule enforcement remain separated — a key principle for compliance audits and internal governance.
match_all_hash()When using the Hash action, OpenObserve allows you to search for hashed values using the original string — without revealing it.
The function match_all_hash() converts your query term into its hash internally and matches it against stored values.
Example:
match_all_hash('4111-1111-1111-1111')
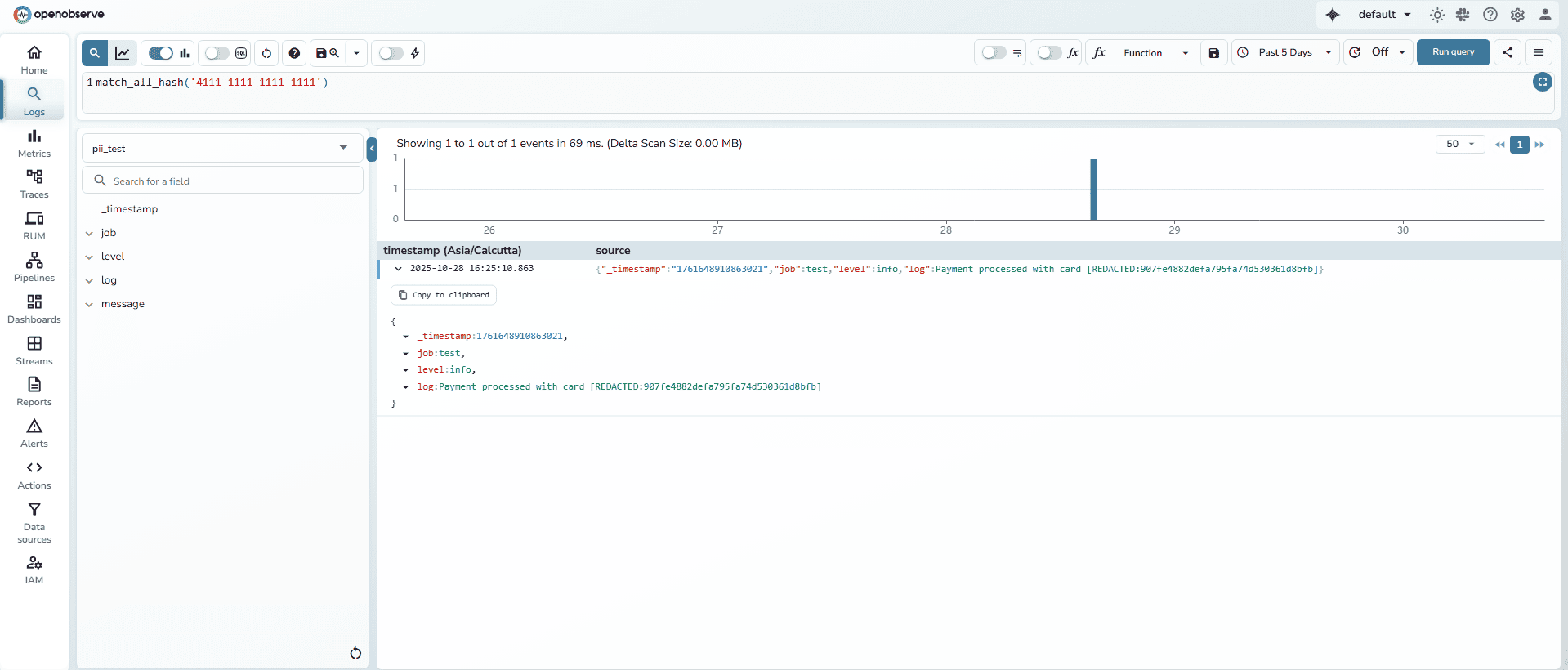
This will return all records that contain the hashed form of that card number, even though the actual value is not stored.
Note: match_all_hash() only works on fields where full-text search has been enabled. It is recommended to turn on full-text search for any field that uses Sensitive Data Redaction with hashing.
This ensures that searches for sensitive values (via their hashed equivalent) are fast and accurate.
If full-text search is not enabled for a field, you can still search using the hash directly. To generate the hash, calculate the MD5 hash of your input value using any tool.
For example, on a terminal you can run:
echo -n "openobserve" | md5
Then search using a LIKE '%HASH%' query to match the hashed token.
Sensitive Data Redaction is built for production-scale observability environments. Its Intel Hyperscan integration allows parallel regex evaluation across streams, minimizing ingestion latency.
However, there are a few practical notes:
Compared to transformation pipelines or external filters, SDR delivers higher performance with less operational complexity.
Sensitive Data Redaction in OpenObserve Enterprise helps teams balance visibility with security. It provides a native, automated way to identify and protect sensitive information — without additional tools or manual intervention.
With flexible redaction modes, role-based access, and high-performance regex matching, OpenObserve gives organizations the confidence to scale observability safely and compliantly.
This feature is available in OpenObserve Cloud and Enterprise Self-Hosted Edition only. It is not part of the Open Source edition.
If you’re using the open-source version, check out this guide: ➡ How to Redact Sensitive PII Data Using VRL Transformations
Try OpenObserve Cloud free for 14 days or deploy the Enterprise Edition self-hosted. Enterprise is free up to 200 GB/day ingestion, and includes additional features like enhanced performance, advanced user management, and built-in security capabilities.
Manas is a passionate Dev and Cloud Advocate with a strong focus on cloud-native technologies, including observability, cloud, kubernetes, and opensource. building bridges between tech and community.












