Why I’m Joining OpenObserve as CRO: It’s Time to Fix Observability

Shani Shoham
January 25, 2026
6 min read
Don’t forget to share!
Try OpenObserve Cloud today for more efficient and performant observability.
Get Started For Free
By Shani Shoham, Chief Revenue Officer, OpenObserve
I've spent over a decade watching transformative technologies follow the same pattern: they start as enablers, become necessities, then morph into expensive complexity that barely anyone can manage. And I've decided to join OpenObserve to break that pattern.
I saw the transformation to cloud and then to cloud native at Perfecto and Testim, where we built testing labs in the cloud. What used to require racks of physical mobile devices became automated cloud infrastructure.
When I joined WekaIO in 2019, we were delivering on the cloud promise in a specific, tangible way: data tiering that expanded into the cloud. Organizations got the performance of local storage with the economics and flexibility of cloud scale. Neocloud’s then emerged offering GPUs for training and inference in the cloud.
The promise was the same: trade capital expense for operational efficiency, trade complexity for simplicity.
That promise was real. For a while.
Fast forward to 2026, and the economics have flipped entirely. Midsize IT companies now spend an average of 10% of their annual revenue on cloud services, with 29% spending over 13% of revenue. Cloud costs have become the second-largest expense after payroll.
And observability? It's become its own budget crisis. In 2022, a major cryptocurrency exchange was reportedly spending $65 million annually on observability. Industry analysts estimate the observability market reached $12 billion in 2024, with observability spend typically running at 15-20% of cloud infrastructure costs.
I'm having the same conversation with every VP Engineering and CTO:
"Our AWS bill is $2M monthly. Our observability spend is $800K annually. And we still can't debug production because we hit sampling limits."
But here's what kills me: it's not just the cost. It's the operational nightmare.
The real cost isn't on the invoice. it's in the 15-20 hours per week DevOps teams spend babysitting infrastructure. Recent SRE research found that 57% of SREs spend more than half their week on toil, manual, repetitive work that scales linearly with service growth—despite widespread automation tool adoption.
Let me be specific about what "modern observability" actually costs operationally:
The Elasticsearch Reality: Your DevOps team spends 15-20 hours weekly managing clusters. Shard rebalancing. Disk pressure alerts. JVM heap tuning. Index lifecycle policies. Disaster recovery that takes 45 minutes because stateful data restoration is slow. Engineers became "Elasticsearch experts" not by choice, but by necessity. And when it breaks at 2am, they're the ones getting paged.
The Alternative Open-Source Reality: You chose an open-source alternative because it's "cheaper." Now you're managing ClickHouse with MergeTree engines and replication strategies. Plus Kafka for ingestion. Plus ZooKeeper for coordination. Your "cost-effective" solution requires a distributed systems PhD to operate.
The LGTM Stack Reality: Loki for logs, Grafana for visualization, Tempo for traces, Mimir for metrics. Four separate services to deploy, version, upgrade, and scale. Each with its own configuration, failure modes, and operational quirks. Your SRE team spends more time managing observability than improving application reliability.
The Integration Hell: Even when paying for enterprise observability platforms, you're stitching together 5-7 tools. During a 2am incident, engineers open five tabs and waste 20 minutes correlating data. MTTR isn't slow because engineers aren't capable—it's slow because tools are fragmented.
We're spending more money and engineering time to get worse results.
Organizations paying $500K-$1M annually get observability that forces data sampling (creating blind spots), requires dedicated headcount (Elasticsearch admins, ClickHouse experts), slows incident response (fragmentation), and burns out SRE teams.
The human cost is staggering: The 2024 Harness State of Developer Experience report found that addressing toil could reclaim 740,000 work hours annually for every 1,000 developers—a 37% productivity boost. That toil is driving an estimated $300 billion yearly cost to employers through burnout and attrition.
This isn't marginal inefficiency. This is a fundamentally broken category.
I've scaled four B2B companies from early stages through acquisition. I've evaluated every observability vendor. When I first looked at OpenObserve, I was skeptical—another observability platform?
Then I examined the architecture. This is actually different.
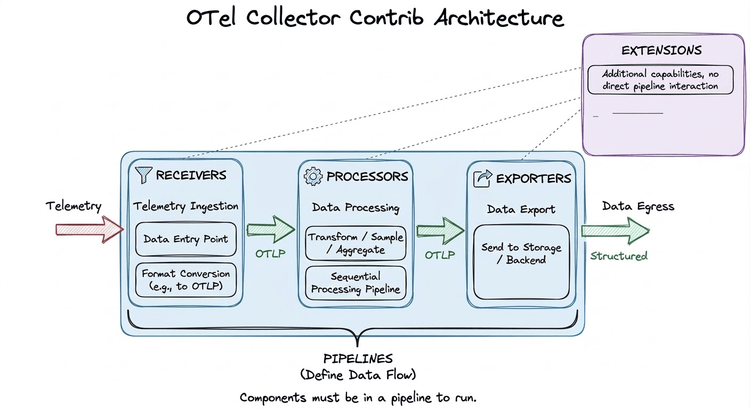
S3-Native Architecture = Zero Database Operations No ClickHouse. No Elasticsearch. No shards, replicas, or cluster coordination. Data goes to S3 in Parquet columnar format with 11-nines durability AWS guarantees. Your database operations become: monitor S3 costs. That's it. Those 15-20 hours per week your team spends managing Elasticsearch? Gone.
Single Rust Binary = Operational Simplicity Not microservices to orchestrate. Not four components to version. One binary. Stateless query nodes that restart in 30 seconds. Scale by adding nodes - no re-architecture, no state migration, no downtime. This is the operational simplicity that actually reduces toil.
Unified Platform = Actual Problem Solving Logs, metrics, traces, RUM, dashboards, alerts in one platform with one UI. Engineers open one tab, write one query (SQL or PromQL), correlate everything instantly. MTTR drops 40-60% by eliminating the tool fragmentation that wastes those critical minutes during 2am incidents.
140x Storage Cost Reduction = Real Savings Parquet columnar compression on S3 delivers 140x lower storage costs than Elasticsearch. Organizations spending $800K/year on enterprise observability platforms spend $250K with OpenObserve—with full retention, no sampling, complete visibility. That's $550K in annual savings. That's 4-5 senior engineers you can hire instead.
I've seen the pattern of solving real infrastructure pain combined with world class go-to-market execution led to 4x YoY growth and 2 acquisitions.
When an incumbent category becomes expensive and complex, there's space for a fundamentally better approach. OpenObserve is that better approach.
And the market is ready. Fortune 500 companies and innovative startups are adopting OpenObserve because the economics finally make sense and the operational model is sustainable.
I'm joining OpenObserve to do what I do best: scale go-to-market and turn product-market fit into category leadership.
That means:
Over the next few weeks we’ll be hiring aggressively across:
If you want to help engineering teams solve real problems while building a category-defining company, reach out!
Shani Shoham is the Chief Revenue Officer at OpenObserve. He previously scaled WekaIO from $1M to $30M ARR (2019-2021), served as President/CRO at Testim.io (acquired by Tricentis for $200M+), and founded 21 Labs (acquired by Perforce). He holds a Computer Engineering degree from Technion and an MBA from Stanford GSB.
Try OpenObserve: Get started free | Schedule demo | Join our team
Shani Shoham is the CRO of OpenObserve and a veteran of the dev-tool industry. With previous leadership roles at WekaIO, Testim, and 21 Labs, he specializes in scaling high-growth infrastructure companies. He is an alum of Stanford GSB and Technion, currently based in Silicon Valley.