Grafana is a powerful open-source platform for monitoring and observability that enables teams to query, visualize, alert on, and understand metrics from various data sources. Known for its beautiful dashboards and extensive plugin ecosystem, Grafana has become the go-to visualization layer for many DevOps and SRE teams worldwide.
However, several factors drive teams to seek alternatives:
- Operational Complexity: The Grafana stack (Prometheus + Loki + Tempo + Grafana) requires managing multiple separate tools
- Steep Learning Curve: Each component has its own query language (PromQL, LogQL, TraceQL) to master
- Scaling Challenges: Self-hosted deployments require significant expertise to scale properly
- Limited Built-in Storage: Grafana is primarily a visualization layer that depends on external data sources
- High-Cardinality Issues: Loki struggles with high-cardinality log data at scale
In this guide, we'll explore ten alternatives that address these concerns, from unified open-source platforms to specialized SaaS solutions.
Why Teams Are Seeking Grafana Alternatives
- Operational Overhead: The LGTM stack (Loki, Grafana, Tempo, Mimir) requires managing multiple deployments, configurations, and upgrades. Teams often spend more time maintaining infrastructure than analyzing data.
- Multi-Tool Complexity: Unlike unified platforms, Grafana requires separate tools for each telemetry signal. This creates context-switching overhead and makes cross-signal correlation challenging.
- Visualization-First Architecture: Grafana started as a visualization tool and added observability features over time. Teams seeking a purpose-built observability platform often find limitations in this approach.
- Cost at Scale: While Grafana itself is free, the infrastructure costs for running Prometheus, Loki, Tempo, and Mimir at scale can be substantial, especially for high-volume environments.
Why This Guide Exists
As observability requirements evolve in 2026, organizations increasingly evaluate Grafana alternatives due to proven operational and cost concerns:
Evidence from Real Deployments:
- Operational reduction: Single-platform alternatives eliminate the need to manage 4+ separate tools
- Query simplification: SQL-based alternatives provide familiar syntax vs learning PromQL, LogQL, and TraceQL
- High-cardinality support: Modern alternatives handle high-cardinality data that Loki struggles with
- Cost efficiency: Unified platforms often provide 60-90% cost reduction vs Grafana stack at scale
What to Look for in a Grafana Alternative
When evaluating Grafana alternative observability tools in 2026, assess these critical dimensions:
| Criterion |
Why It Matters |
What to Evaluate |
How to Test |
| Unified Observability |
Reduces tool sprawl and context switching |
Single pane for metrics, logs, traces with cross-signal correlation |
Run distributed transaction and trace from logs → metrics → traces |
| Query Language |
Investigation efficiency and learning curve |
SQL support vs proprietary DSLs like PromQL/LogQL |
Perform real incident investigations |
| Operational Overhead |
Team productivity and maintenance burden |
Single deployment vs multi-component architecture |
Compare time spent on maintenance vs analysis |
| Cost Structure |
Budget predictability and scale economics |
Transparent pricing, infrastructure costs at 2x, 5x, 10x scale |
Model costs for current + projected growth |
| High-Cardinality Support |
Modern application requirements |
User-level tracking, request ID tracing, no performance penalties |
Test with 1M+ unique dimension values |
| Data Ownership |
Compliance, control, flexibility |
Self-hosted option, data export formats, retention control |
Review DPA, export data samples |
| Scalability |
Performance as data volume grows |
Ingestion throughput, query performance, storage efficiency |
Benchmark with production-scale data volumes |
| Migration Ease |
Time and risk to adopt |
OpenTelemetry support, Prometheus compatibility, import tools |
Pilot migration with test cluster |
| Visualization Quality |
Dashboard flexibility and usability |
Dashboard creation experience, template support, sharing |
Create production-grade dashboards |
| Integration Ecosystem |
Works with existing stack |
Cloud provider integrations, database connectors, third-party tools |
Test critical integrations |
Top 10 Grafana Alternatives: Comparison & Use Cases
Jump to comparison table for Grafana alternatives comparison and use cases.
1. OpenObserve
OpenObserve is the #1 open-source Grafana alternative for teams wanting unified observability without operational complexity, high costs, or the need to manage multiple tools. It delivers 60-90% cost savings through 140x compression technology while providing a single platform for logs, metrics, traces, and frontend monitoring.
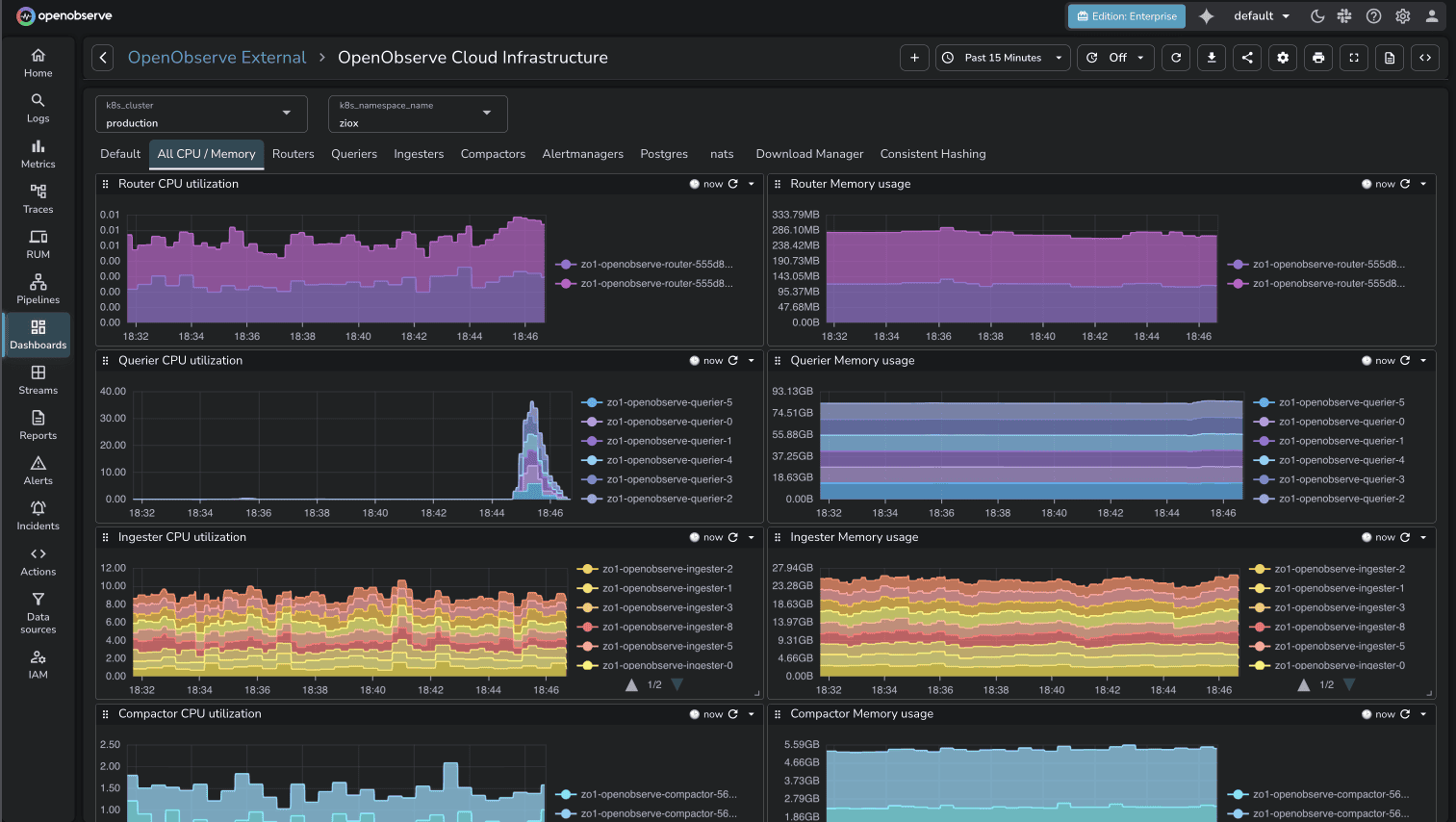
OpenObserve Pros:
- Single Unified Platform: Logs, metrics, traces, and RUM in one tool — no need for separate Prometheus, Loki, and Tempo deployments
- SQL-Based Queries: Avoid learning PromQL, LogQL, and TraceQL — use familiar SQL syntax for all signals
- OpenTelemetry-Native: Drop-in replacement using vendor-neutral instrumentation standards
- 140x Lower Storage Costs: Parquet columnar format with aggressive compression dramatically reduces storage needs
- High-Cardinality Support: Handles high-cardinality data that Loki struggles with at scale
- Single Binary Deployment: Get running in under 2 minutes with minimal infrastructure requirements
- Self-Hosted or Cloud: Full control over data residency and retention with flexible deployment options
- Predictable Costs: No per-host or per-metric billing model — flat-rate pricing
OpenObserve Cons:
- Smaller integration marketplace compared to Grafana's extensive plugin ecosystem
- Requires SQL familiarity for advanced analysis
- Newer ecosystem with community integrations still expanding
Integration / Mitigation:
- Works with OpenTelemetry Collector as a complete stack replacement
- Compatible with Prometheus remote write for seamless migration
- Supports FluentBit, Vector, and other popular log shippers
- Can run alongside Grafana for phased migrations
For a comprehensive technical comparison, explore the detailed OpenObserve vs Grafana comparison. The analysis covers architecture differences, query capabilities, and real-world performance benchmarks.
2. Datadog
Datadog is a comprehensive SaaS-based observability platform that offers a familiar all-in-one experience similar to what teams seek when moving from the Grafana stack.
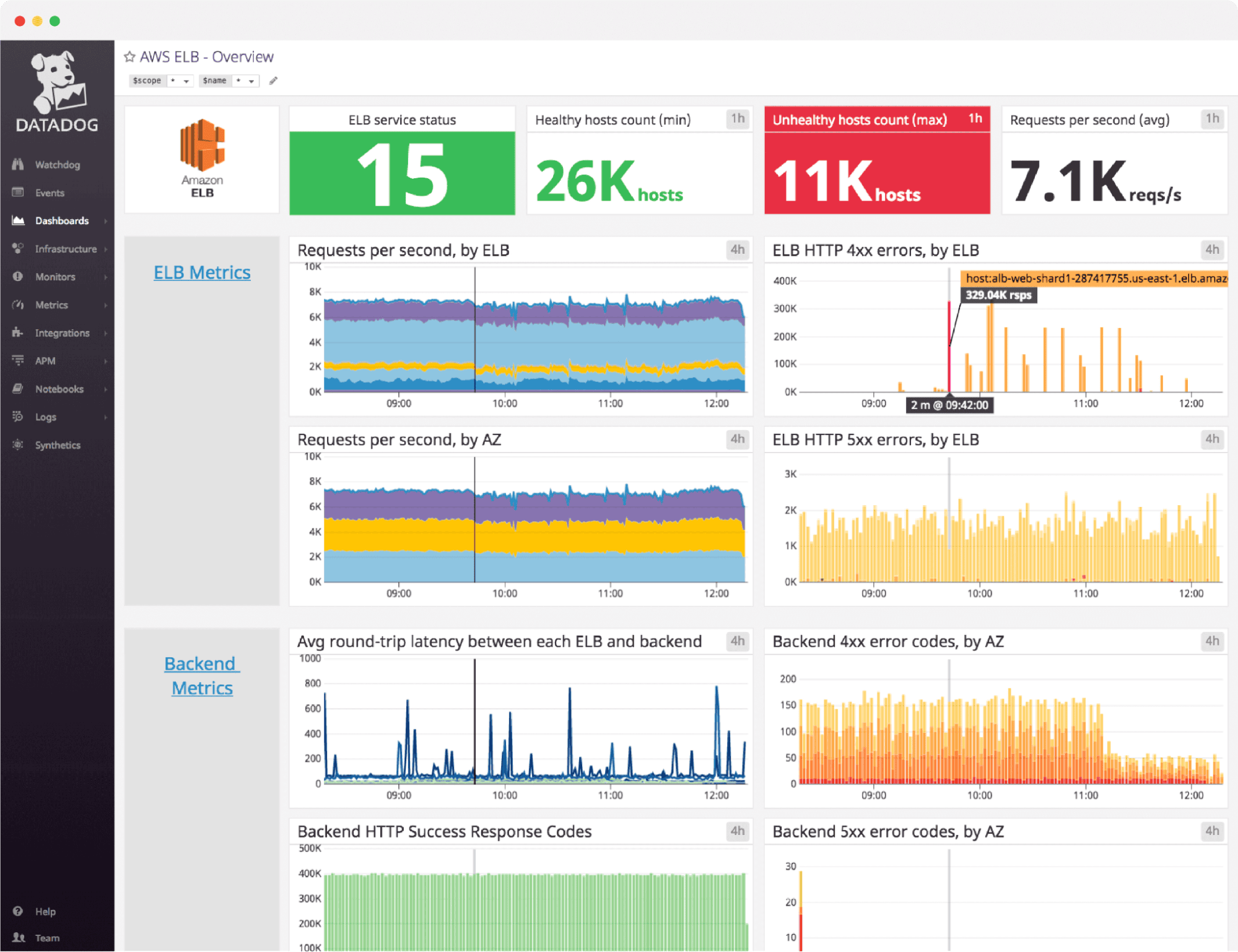
Datadog Pros:
- Truly Unified Platform: Metrics, logs, traces, RUM, synthetics, and security in one integrated solution
- No Operational Overhead: Fully managed SaaS eliminates infrastructure maintenance
- 700+ Integrations: Extensive out-of-the-box support for virtually any technology
- Strong APM Capabilities: Deep code-level visibility and automatic service discovery
- Enterprise Features: Advanced security, compliance, and team collaboration tools
Datadog Cons:
- Expensive at scale — costs can grow rapidly with data volume and host count
- Vendor lock-in with proprietary agents and data formats
- Custom metrics pricing creates unpredictable bills
- No self-hosted option for data sovereignty requirements
Integration / Mitigation:
- OpenTelemetry support allows some vendor flexibility
- Migration from Grafana stack is straightforward for metrics
- Consider phased migration starting with one signal type
3. New Relic
New Relic is a SaaS-based observability platform known for strong APM capabilities and a comprehensive all-in-one experience.
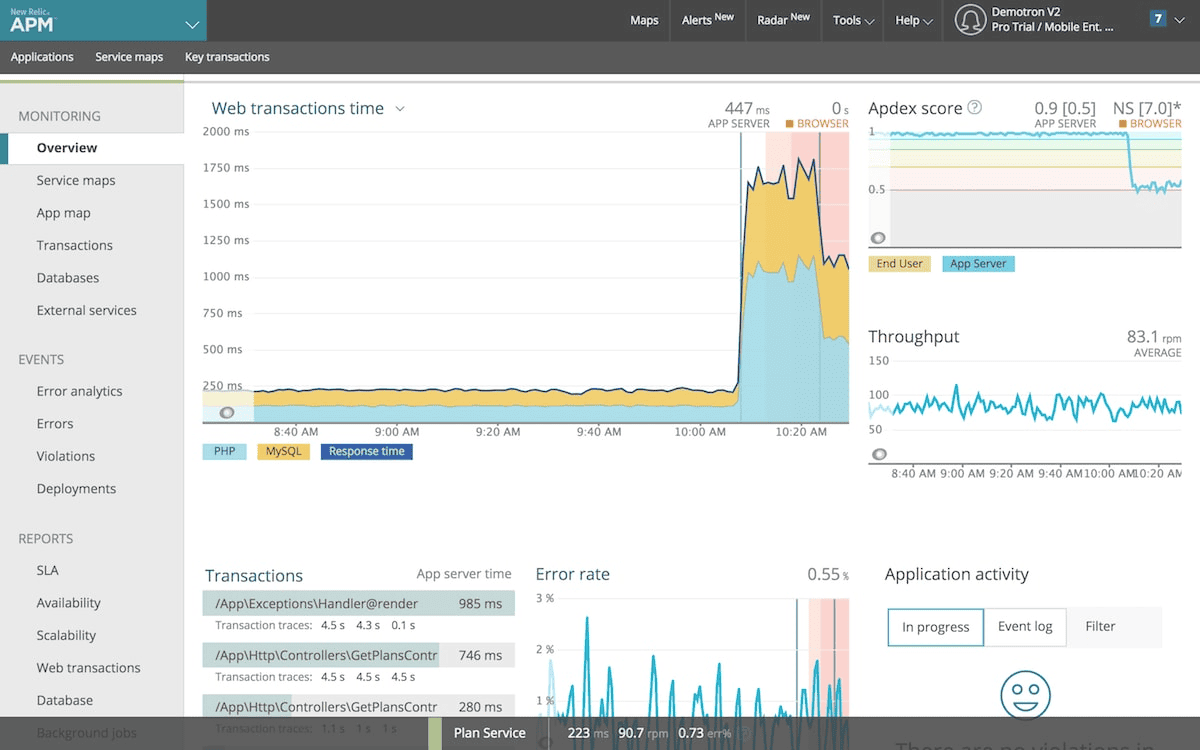
New Relic Pros:
- Comprehensive APM: Deep code-level performance insights and automatic instrumentation
- Unified Platform: Metrics, logs, traces, RUM, and synthetics in one solution
- Free Tier Available: 100 GB free per month makes it accessible for smaller teams
- Strong OpenTelemetry Support: Easy migration from vendor-specific instrumentation
- AI-Powered Insights: Automatic anomaly detection and root cause analysis
New Relic Cons:
- Costs can grow quickly with high data volumes beyond free tier
- Less control over data residency than self-hosted options
- Proprietary platform with some vendor lock-in
Integration / Mitigation:
- OpenTelemetry support enables future flexibility
- Prometheus integration eases Grafana stack migration
- Suitable for teams wanting managed solution without operational burden
4. Honeycomb
Honeycomb is a modern observability platform purpose-built for debugging distributed systems, with exceptional high-cardinality data handling and exploratory analysis capabilities.
Honeycomb Pros:
- Exceptional High-Cardinality Support: Handles millions of unique dimension values without performance degradation — unlike Loki which struggles with high cardinality
- Fast Exploratory Queries: BubbleUp feature automatically surfaces anomalies and patterns in complex data
- Purpose-Built for Distributed Systems: Designed from the ground up for microservices debugging and tracing
- Strong SLO Workflows: First-class SLOs, error budgets, and burn-rate alerts tied to real request data
- OpenTelemetry-Native: Excellent OTel support for vendor-neutral instrumentation
- Developer-Centric Experience: Intuitive UI designed around debugging workflows rather than dashboards
Honeycomb Cons:
- SaaS-only — no self-hosted option available
- Less focus on traditional infrastructure dashboards
- Pricing scales with event volume which can be costly at high scale
- Different mental model than traditional metrics-based monitoring
Integration / Mitigation:
- OpenTelemetry-native ingestion makes migration straightforward
- Can selectively replace Grafana Tempo for tracing while keeping other components
- Often used alongside infrastructure monitoring tools for comprehensive coverage
5. Elastic Observability (ELK Stack)
Elastic Observability is a comprehensive platform built on the Elastic Stack, particularly strong for log analytics and search-driven observability.
Elastic Observability Pros:
- Powerful Log Search: Elasticsearch excels at full-text and structured log search
- Unified Logs, Metrics, and APM: Covers most observability use cases in one platform
- Flexible Deployment: Cloud, self-hosted, or hybrid options available
- Mature Ecosystem: Large community, extensive documentation, proven at scale
- Security + Observability: Strong SIEM capabilities for security-conscious teams
Elastic Observability Cons:
- Expensive to operate at scale — high infrastructure and tuning overhead
- Storage costs grow quickly with log volumes
- Complex cluster management compared to simpler alternatives
- Steep learning curve for optimization
Integration / Mitigation:
- Beats and Logstash can coexist with existing Grafana stack during migration
- Supports OpenTelemetry ingestion
- Managed Elastic Cloud reduces operational burden
6. Dynatrace
Dynatrace is an enterprise-grade observability platform focused on automatic instrumentation, AI-driven insights, and comprehensive full-stack visibility.
Dynatrace Pros:
- Automatic Instrumentation: OneAgent provides code-level visibility without manual setup
- AI-Powered Root Cause Analysis: Davis AI automatically identifies problems and root causes
- End-to-End Visibility: Infrastructure to user experience in one platform
- Enterprise-Ready: Handles very large, complex enterprise environments
- Hybrid and On-Prem Support: Suitable for regulated industries with data residency requirements
Dynatrace Cons:
- Premium pricing — often more expensive than other options
- Less flexible than open-source alternatives
- Proprietary agents and data formats create lock-in
- May be overkill for smaller or cloud-native teams
Integration / Mitigation:
- OneAgent simplifies migration from manual Grafana instrumentation
- OpenTelemetry support improving for vendor neutrality
- Best suited for enterprises requiring comprehensive automation
7. Splunk Observability
Splunk offers enterprise-grade observability with strong analytics capabilities, particularly for log-heavy environments and security-focused teams.
Splunk Observability Pros:
- Extremely Powerful Analytics: SPL query language enables deep correlation and analysis
- Enterprise-Grade Security: Strong compliance, audit, and security capabilities
- Mature Platform: Proven reliability at massive enterprise scale
- On-Prem and Cloud Options: Flexible deployment for various compliance needs
- Strong Log Management: Industry-leading log analytics and search
Splunk Observability Cons:
- One of the most expensive tools on the market
- Complex pricing and licensing model
- Steep learning curve for SPL query language
- Heavy resource requirements for self-hosted deployments
Integration / Mitigation:
- Universal Forwarders can collect data alongside existing Prometheus exporters
- OpenTelemetry support available for modern instrumentation
- Often used for specific use cases (security, compliance) alongside other tools
8. Prometheus + Thanos/Cortex
Prometheus with Thanos or Cortex provides a scalable metrics solution that addresses some of Prometheus's limitations while maintaining compatibility.
Prometheus + Thanos/Cortex Pros:
- CNCF Standard: Prometheus is the industry standard for Kubernetes metrics monitoring
- Unlimited Retention: Thanos/Cortex add long-term storage with global query capabilities
- High Availability: Eliminates single points of failure in Prometheus deployments
- PromQL Compatibility: No query language changes required for existing users
- Open Source: Full control and transparency
Prometheus + Thanos/Cortex Cons:
- Metrics only — still requires separate tools for logs and traces
- Significant operational complexity to set up and maintain
- Requires expertise to tune for performance at scale
- Multiple components to manage and upgrade
Integration / Mitigation:
- Can serve as the metrics backend while replacing Loki/Tempo with unified alternatives
- Grafana remains compatible for visualization
- OpenTelemetry Collector can route metrics to Thanos/Cortex
9. VictoriaMetrics
VictoriaMetrics is a fast, cost-effective time-series database that serves as a drop-in Prometheus replacement with better performance and lower resource usage.
VictoriaMetrics Pros:
- Superior Performance: Faster queries and better compression than Prometheus
- Drop-In Prometheus Replacement: PromQL compatible, works with existing exporters
- Lower Resource Usage: Significantly reduced CPU and memory requirements
- High-Cardinality Friendly: Handles high-cardinality metrics better than Prometheus
- Simple Operations: Single binary deployment option available
VictoriaMetrics Cons:
- Metrics only — doesn't replace Loki or Tempo for logs and traces
- Still requires Grafana or another tool for visualization
- Smaller ecosystem than Prometheus
- Some advanced features require enterprise license
Integration / Mitigation:
- Direct replacement for Prometheus in existing Grafana stack
- Compatible with existing dashboards and alerts
- Can coexist with Prometheus during migration
10. Uptrace
Uptrace is an OpenTelemetry-native observability platform focused on distributed tracing and lightweight APM with a ClickHouse backend.
Uptrace Pros:
- Built for OpenTelemetry: Native OTel support for traces, metrics, and logs without adapters
- Excellent Tracing Performance: Fast trace ingestion and querying optimized for distributed systems
- Cost-Effective ClickHouse Backend: Efficient storage with high-performance analytics
- Self-Hosted or Cloud: Flexible deployment options for different requirements
- Clean, Simple UI: Intuitive interface focused on tracing and debugging workflows
Uptrace Cons:
- Smaller ecosystem and community than established platforms
- Less mature alerting compared to Grafana Alertmanager
- Narrower scope than full-featured observability platforms
- Limited enterprise features
Integration / Mitigation:
- Seamless replacement via OpenTelemetry instrumentation
- Docker and Kubernetes friendly deployments
- Often paired with VictoriaMetrics for comprehensive metrics solution
Comparison Table: Grafana Alternatives 2026
| Tool |
Deployment |
Metrics |
Logs |
Traces |
Query Language |
Why Teams Choose It Over Grafana |
Migration Ease |
| OpenObserve |
Self-hosted / Cloud |
✅ |
✅ |
✅ |
SQL |
Single unified platform, 140x lower storage costs, no operational overhead |
⭐⭐⭐⭐⭐ (OTel-native) |
| Datadog |
SaaS |
✅ |
✅ |
✅ |
Proprietary |
Zero operational burden, 700+ integrations out of the box |
⭐⭐⭐⭐ (Agent-based) |
| New Relic |
SaaS |
✅ |
✅ |
✅ |
NRQL |
100GB free tier, comprehensive APM without infrastructure management |
⭐⭐⭐⭐ (OTel support) |
| Honeycomb |
SaaS |
⚠️ |
⚠️ |
✅ |
Proprietary |
Best high-cardinality support, purpose-built for distributed tracing |
⭐⭐⭐⭐⭐ (OTel-native) |
| Elastic Observability |
Self-hosted / Cloud |
✅ |
✅ |
✅ |
KQL/Lucene |
Industry-leading log search and security integration |
⭐⭐⭐ (More ops work) |
| Dynatrace |
SaaS / Hybrid |
✅ |
✅ |
✅ |
DQL |
Automatic instrumentation eliminates manual Grafana config |
⭐⭐⭐⭐ (OneAgent) |
| Splunk Observability |
SaaS / On-prem |
✅ |
✅ |
✅ |
SPL |
Enterprise compliance and powerful analytics for large orgs |
⭐⭐⭐ (Different model) |
| Prometheus + Thanos |
Self-hosted |
✅ |
❌ |
❌ |
PromQL |
Unlimited retention with PromQL compatibility |
⭐⭐⭐⭐ (Same ecosystem) |
| VictoriaMetrics |
Self-hosted / Cloud |
✅ |
⚠️ |
❌ |
MetricsQL |
Better performance and lower resources than Prometheus |
⭐⭐⭐⭐⭐ (Drop-in) |
| Uptrace |
Self-hosted / Cloud |
✅ |
✅ |
✅ |
SQL |
Lightweight OTel-native alternative with efficient ClickHouse storage |
⭐⭐⭐⭐⭐ (OTel-native) |
How to Choose the Right Grafana Alternative
Selecting the right Grafana alternative depends on several factors:
1. Operational Simplicity vs Flexibility
If you're tired of managing Prometheus, Loki, Tempo, and Grafana separately, unified platforms like OpenObserve or Datadog provide everything in one tool. If you value the modularity of separate tools, consider VictoriaMetrics as a Prometheus replacement while keeping Grafana for visualization.
2. Budget Constraints
For teams with tight budgets, open-source options like OpenObserve and VictoriaMetrics provide maximum value. OpenObserve's 140x storage compression is particularly cost-effective at scale. For moderate budgets with reduced operational burden, New Relic's free tier or managed OpenObserve Cloud are attractive options. Enterprise budgets may justify Dynatrace, Splunk, or Datadog for their comprehensive features and support.
3. Query Language Preference
If your team is heavily invested in PromQL, consider VictoriaMetrics or Prometheus + Thanos which maintain full compatibility. If you prefer SQL-based querying that's easier to learn, OpenObserve and Uptrace use familiar SQL syntax. If you're comfortable with proprietary languages, Datadog, Splunk, and New Relic each have their own DSLs.
4. Deployment Preference
For self-hosted requirements driven by data sovereignty or compliance, choose OpenObserve, Elastic, or Uptrace. For SaaS preferences that eliminate operational burden, Datadog, New Relic, or Dynatrace are excellent choices. For hybrid needs, Dynatrace, Elastic, and managed versions of open-source tools provide flexibility.
5. Primary Use Case
For general observability replacing the full Grafana stack, OpenObserve, Datadog, or New Relic provide comprehensive coverage. For APM-focused monitoring, Dynatrace, New Relic, or Datadog excel with automatic instrumentation and code-level insights. For distributed tracing and high-cardinality debugging, Honeycomb leads with purpose-built exploration tools. For log analytics and security, Elastic and Splunk lead with powerful search and SIEM capabilities. For metrics-only replacement of Prometheus, VictoriaMetrics or Thanos maintain compatibility while adding scale.
6. Migration Strategy
For quick migration with minimal changes, choose OpenTelemetry-native tools like OpenObserve or Uptrace that work with existing OTel instrumentation. For gradual transition, start by replacing one component — for example, swap Loki for OpenObserve while keeping Prometheus and Grafana. For parallel running during evaluation, most alternatives can receive data alongside your existing Grafana stack using OpenTelemetry Collector's fanout capabilities.
Migrating from Grafana Stack to OpenObserve
Migrating from the Grafana stack (Prometheus + Loki + Tempo + Grafana) to OpenObserve can be done incrementally using OpenTelemetry, without rewriting your existing instrumentation. By routing telemetry through the OpenTelemetry Collector, teams can standardize on OTLP while gaining full control over data, costs, and storage.
This approach allows you to run Grafana and OpenObserve side by side during migration, validate data parity, and gradually transition dashboards and alerts — all while avoiding vendor lock-in.
The migration typically follows these phases:
- Phase 1: Deploy OpenTelemetry Collector alongside existing Prometheus exporters and configure dual-write to both Grafana stack and OpenObserve.
- Phase 2: Recreate critical dashboards in OpenObserve using its built-in visualization capabilities and SQL-based queries.
- Phase 3: Migrate alerting rules from Alertmanager to OpenObserve's unified alerting system.
- Phase 4: Decommission Grafana stack components once validation is complete.
Conclusion
While Grafana is a powerful visualization platform, its multi-component architecture creates operational overhead that various alternatives address in different ways.
- OpenObserve stands out for teams wanting unified observability with massive cost savings, SQL-based querying, and the flexibility of open source in a single platform rather than managing Prometheus, Loki, Tempo, and Grafana separately.
- Open-source options (OpenObserve, VictoriaMetrics, Uptrace) provide maximum control and transparency while addressing the operational complexity of the Grafana stack.
- SaaS alternatives (Datadog, New Relic, Dynatrace) offer zero operational overhead with comprehensive features, though at higher cost and with vendor lock-in considerations.
- OpenTelemetry adoption makes migration significantly easier by decoupling instrumentation from backends, allowing you to switch platforms without changing application code.
The right choice depends on your team's specific needs, technical expertise, budget constraints, and long-term observability strategy. Many teams find that unified alternatives not only reduce operational burden but also provide better performance, simpler querying, and features specifically designed for modern cloud-native architectures.
Take the Next Step
Ready to explore the best Grafana alternative for your team?
Try OpenObserve: Start with the open source version or sign up for OpenObserve Cloud
FAQs: Grafana Alternative Tools
What is the best Grafana alternative in 2026?
OpenObserve is the best overall Grafana alternative for teams seeking unified observability. It combines logs, metrics, traces, and frontend monitoring in a single platform with SQL-based querying, eliminating the need to manage separate tools like Prometheus, Loki, and Tempo. With 140x lower storage costs and single-binary deployment, OpenObserve provides a compelling alternative to the operational complexity of the Grafana stack.
Which Grafana alternative is most cost-effective?
OpenObserve provides the most dramatic cost savings among Grafana alternatives, with 140x compression technology that significantly reduces storage costs. VictoriaMetrics also offers excellent cost efficiency for metrics-specific use cases with lower resource requirements than Prometheus. For teams preferring SaaS without operational costs, New Relic's 100GB free tier makes it accessible for smaller deployments.
Can I migrate from Grafana without losing my dashboards?
While direct dashboard import varies by platform, most alternatives provide dashboard building capabilities that can recreate Grafana visualizations. OpenObserve offers an intuitive dashboard builder with similar visualization types. For metrics-focused migrations, VictoriaMetrics maintains PromQL compatibility, allowing existing Grafana dashboards to continue working with minimal changes. The OpenTelemetry Collector enables dual-write during migration, letting you build new dashboards while keeping existing ones operational.
Which Grafana alternative is best for Kubernetes monitoring?
OpenObserve excels at Kubernetes monitoring with native OpenTelemetry support and efficient handling of container metrics. VictoriaMetrics serves as an excellent Prometheus replacement for Kubernetes metrics with better performance and high-cardinality support. For teams wanting zero operational overhead, Datadog and New Relic provide comprehensive Kubernetes observability with automatic service discovery and container-native features.
Should I choose a unified platform or stick with the modular Grafana approach?
The answer depends on your team's priorities. Unified platforms like OpenObserve or Datadog reduce operational complexity by eliminating the need to manage multiple tools, making them ideal for teams that want to focus on observability rather than infrastructure. The modular Grafana approach offers maximum flexibility and allows best-of-breed selection for each component, but requires more operational expertise. Many teams are moving toward unified platforms as the operational cost of managing separate tools becomes harder to justify.
How does OpenTelemetry help with migration from Grafana?
OpenTelemetry provides vendor-neutral instrumentation that decouples your applications from any specific observability backend. By adopting OpenTelemetry, you can switch from the Grafana stack to any OTel-compatible platform like OpenObserve or Uptrace without changing your application code. The OpenTelemetry Collector acts as a central hub that can route data to multiple destinations simultaneously, enabling gradual migration with side-by-side comparison of platforms.