What Is AIOps? The Complete Guide to AI-Powered IT Operations in 2026

Manas Sharma
March 18, 2026
14 min read
Don’t forget to share!
Try OpenObserve Cloud today for more efficient and performant observability.

When a critical payment service goes down at 3 AM, your on-call engineer doesn't just need to know what broke—they need to know why, where, and how to fix it before customers notice. In modern cloud-native environments with hundreds of microservices, thousands of dependencies, and millions of log lines per minute, finding that answer manually is like searching for a needle in a haystack while the haystack is on fire.
This is the problem AIOps was designed to solve.
AIOps (Artificial Intelligence for IT Operations) applies artificial intelligence and machine learning to IT operations data—logs, metrics, traces, and events—to detect anomalies, correlate incidents, predict failures, and automate remediation. Instead of overwhelming human operators with thousands of alerts, AIOps platforms identify patterns, surface root causes, and in some cases, resolve issues autonomously.
In 2026, AIOps has evolved from simple anomaly detection systems into agentic AI platforms capable of understanding system behavior, drafting fixes, and orchestrating complex remediation workflows. This guide explores what AIOps is, how it works, and why the quality of your observability data determines the intelligence of your AI-powered operations.
The term "AIOps" was coined by Gartner in 2016 to describe platforms that combine big data and machine learning to enhance IT operations. Gartner's original definition focused on platforms that "combine big data and machine learning functionality to support all primary IT operations functions through the scalable ingestion and analysis of the ever-increasing volume, variety and velocity of data generated by IT."
For years, however, AIOps struggled to live up to its promise. Early platforms excelled at detecting anomalies but failed at the next critical step: explaining what those anomalies meant and taking meaningful action. They created alert storms rather than reducing them, generating a different kind of noise that still required human investigation.
Three fundamental shifts have transformed AIOps from a research concept into production-grade infrastructure:
1. Agentic AI Replaces Predictive Models
The breakthrough in large language models (LLMs) and agentic AI systems has fundamentally changed what's possible. Instead of simple anomaly scoring, modern AIOps platforms can:
According to Gartner's 2025 Market Guide for AIOps Platforms, "by 2027, 30% of enterprises will have adopted AIOps platforms with agentic AI capabilities that can autonomously resolve common incidents without human intervention."
2. Full-Fidelity Data Beats Sampling
Early AIOps implementations failed because they operated on incomplete data. When telemetry was sampled, aggregated, or dropped to control costs, AI models lost the critical context needed for accurate correlation and root cause analysis.
The shift to cost-efficient, petabyte-scale observability platforms has removed this constraint. Modern AIOps works best when it can analyze all your data—not just sampled fragments. This is why the observability foundation matters as much as the AI layer on top.
3. Transparency Over Black Boxes
First-generation AIOps platforms operated as black boxes: they'd declare an incident and suggest a root cause, but engineers couldn't see how the system reached that conclusion. This lack of transparency created distrust.
Modern platforms provide complete visibility into AI decision-making. Engineers can review:
This transparency doesn't just build trust—it helps teams learn from the AI's reasoning and improve their own troubleshooting skills.
AIOps isn't a single technology—it's a collection of AI-powered capabilities that work together to enhance IT operations. Here are the core functions that define modern AIOps platforms:
At its foundation, AIOps uses machine learning to establish baselines of normal system behavior and detect deviations that indicate potential issues.
How it works:
The challenge: Not all anomalies are incidents. A traffic spike during a product launch is an anomaly, but not a problem. Effective AIOps must understand context—which is why correlation is critical.
Modern distributed systems generate thousands of alerts during incidents. A single failed database might trigger alerts across dozens of dependent services. AIOps correlates these related events into a single incident.
Key techniques:
According to a 2024 study by Enterprise Management Associates, organizations using AIOps for event correlation reduced alert volume by an average of 76% while improving incident detection accuracy.
Instead of forcing engineers to manually trace an incident through logs, metrics, and traces, AIOps automates the investigative process.
Modern RCA capabilities:
The quality of RCA depends entirely on the quality and completeness of observability data. Incomplete logs or sampled traces create blind spots that AI cannot overcome.
AIOps is only as intelligent as the data it analyzes. This is why understanding the observability foundation is critical.
Modern AIOps platforms consume three primary types of telemetry data:
Logs capture discrete events: errors, warnings, transactions, user actions, system state changes. They provide the "what happened" context.
Why logs matter for AIOps:
The challenge: High-cardinality logs (unique identifiers, UUIDs, IP addresses) create massive data volumes. Cost concerns often force teams to sample or drop logs—which starves AIOps of critical context.
Metrics are numeric measurements collected at regular intervals: CPU usage, memory consumption, request rates, error rates, latency percentiles.
Why metrics matter for AIOps:
The challenge: Metrics alone lack context. A spike in error rate doesn't tell you which errors or why they're happening. This is why AIOps must correlate metrics with logs and traces.
Traces follow individual requests as they flow through distributed systems, capturing timing and dependencies across services.
Why traces matter for AIOps:
The challenge: Tracing generates enormous data volumes. Teams often sample traces (capturing 1% of requests), which creates blind spots. Rare but critical errors might never be traced.
Here's the uncomfortable truth: sampling breaks AIOps.
When you drop 99% of traces, aggregate logs, or tier data into "hot" and "cold" storage, you're making trade-offs that limit AI effectiveness. The anomaly you're trying to detect might be in the data you didn't capture. The correlated event that explains root cause might be in a log line you dropped.
This is why the economics of observability matter. If storing full-fidelity data is prohibitively expensive, teams make compromises that undermine AIOps capabilities. Platforms that can ingest and analyze complete telemetry data—without sampling or tiering—create a significant advantage for AI-powered operations.
Gartner's annual AIOps Market Guide provides the industry's most authoritative assessment of platform maturity and vendor capabilities. The 2025 report highlights several key trends:
Gartner notes that "the most successful AIOps implementations are tightly integrated with observability platforms rather than deployed as standalone tools." The reason is simple: AIOps depends on comprehensive, high-quality telemetry data. Observability platforms that add native AIOps capabilities have a structural advantage over point solutions.
Early AIOps focused on incident response—detecting and resolving issues faster. Modern platforms emphasize proactive capabilities: predicting failures, optimizing costs, preventing incidents before they happen.
Gartner projects that "by 2027, organizations using proactive AIOps will reduce unplanned downtime by 60% compared to reactive monitoring approaches."
Generic AIOps platforms are giving way to specialized solutions optimized for specific domains:
The most capable platforms support multiple domains through modular, extensible architectures.
Gartner emphasizes the importance of OpenTelemetry adoption. Platforms that support open standards for telemetry collection avoid vendor lock-in and enable hybrid AIOps strategies where organizations can combine best-of-breed tools.
It's easy to confuse AIOps with traditional monitoring or observability. Here's how they differ:
| Capability | Traditional Monitoring | Observability | AIOps |
|---|---|---|---|
| Data Collection | Metrics, basic logs | Metrics, logs, traces | Metrics, logs, traces + correlation |
| Alerting | Static thresholds | Dynamic baselines | Anomaly detection + event correlation |
| Investigation | Manual log searching | Query-driven exploration | AI-assisted root cause analysis |
| Remediation | Manual runbooks | Scripted automation | Intelligent, context-aware automation |
| Learning | No feedback loop | Dashboard tuning | Continuous model improvement |
Traditional monitoring tells you that something is wrong. Observability lets you ask why it's wrong. AIOps figures out why it's wrong and what to do about it.
AIOps isn't equally valuable for every organization. Here are the scenarios where it delivers transformational impact:
Organizations running hundreds of microservices in Kubernetes generate overwhelming operational complexity. AIOps becomes essential for:
Teams shipping multiple deployments per day need rapid feedback loops. AIOps helps by:
For teams managing always-on services (e-commerce, SaaS, financial services), AIOps reduces on-call burden by:
As cloud spending grows, AIOps supports financial operations by:
While distinct from traditional AIOps, similar AI techniques apply to security:
Here's a principle borrowed from the world of large language models: the quality of AI output is directly proportional to the quality and comprehensiveness of input data.
Just as an LLM trained on a small, low-quality corpus produces poor results, an AIOps platform analyzing incomplete, sampled, or aggregated telemetry data will deliver limited intelligence.
Effective AIOps requires:
This presents a fundamental challenge: traditional observability platforms charge per GB ingested or per host monitored, making full-fidelity data collection prohibitively expensive.
According to industry benchmarks, organizations running on legacy observability platforms (Splunk, Datadog, Dynatrace) spend $500,000 to $5 million annually on telemetry data ingestion and storage. To control costs, they:
Each of these cost-saving measures degrades AIOps effectiveness. The anomaly you need to detect is often in the data you didn't capture.
This is where architecture makes all the difference. OpenObserve was built from the ground up to solve the full-fidelity problem.
By using columnar storage (Parquet), aggressive compression, and efficient indexing, OpenObserve delivers 140x lower storage costs than traditional platforms. This economic advantage enables a fundamentally different approach to AIOps:
Full-fidelity telemetry becomes affordable. Teams can ingest 100% of logs, traces, and metrics without sampling or dropping data. The AI models powering AIOps analysis have access to complete, uncompromised datasets.
Petabyte-scale analysis becomes practical. With lower storage costs, organizations can retain months or years of telemetry data for historical analysis, pattern recognition, and continuous model training.
No data silos. OpenObserve unifies logs, metrics, and traces in a single platform, enabling seamless correlation without stitching together multiple vendor tools.
On top of this comprehensive data foundation, OpenObserve layers three AI-powered capabilities:
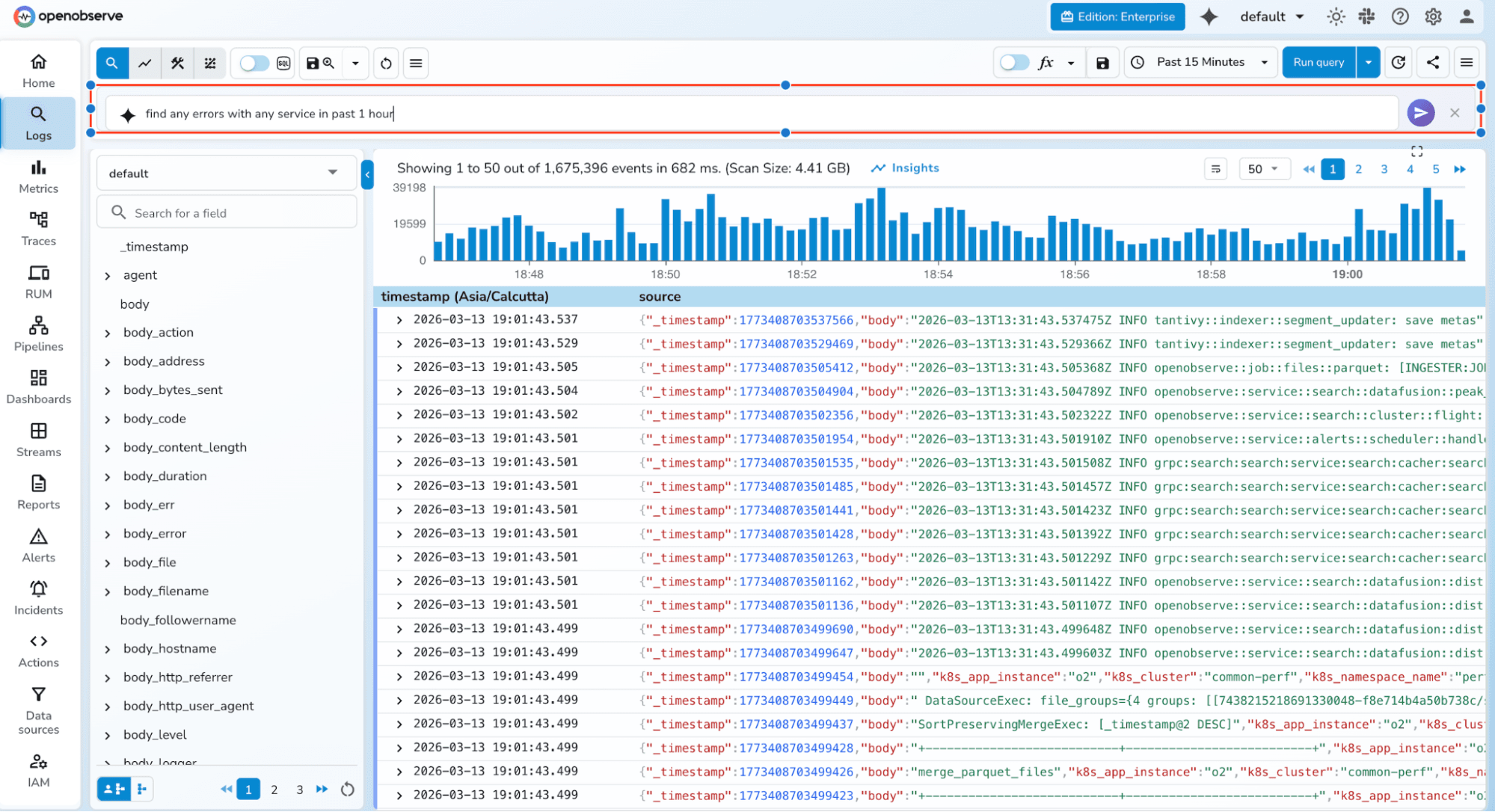 3. O2 SRE Agent: An always-on Site Reliability Engineer that automates root cause analysis, correlates incidents, and improves MTTR through historical learning
3. O2 SRE Agent: An always-on Site Reliability Engineer that automates root cause analysis, correlates incidents, and improves MTTR through historical learning
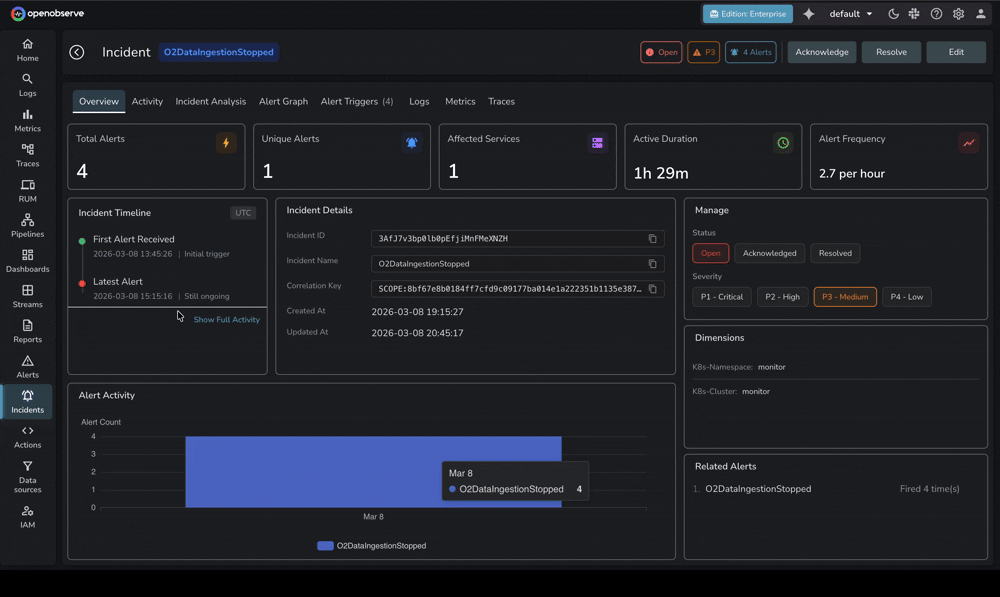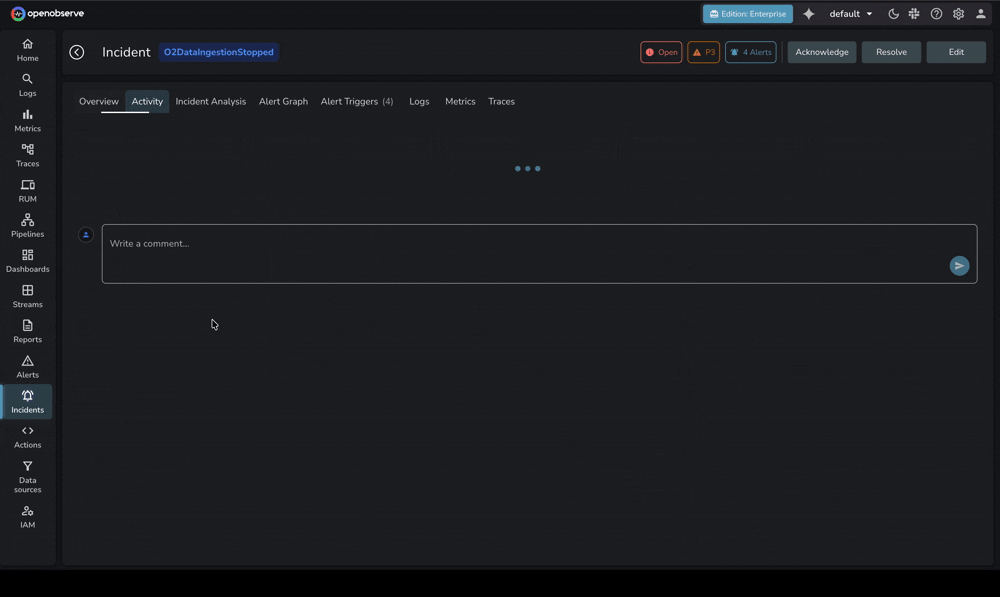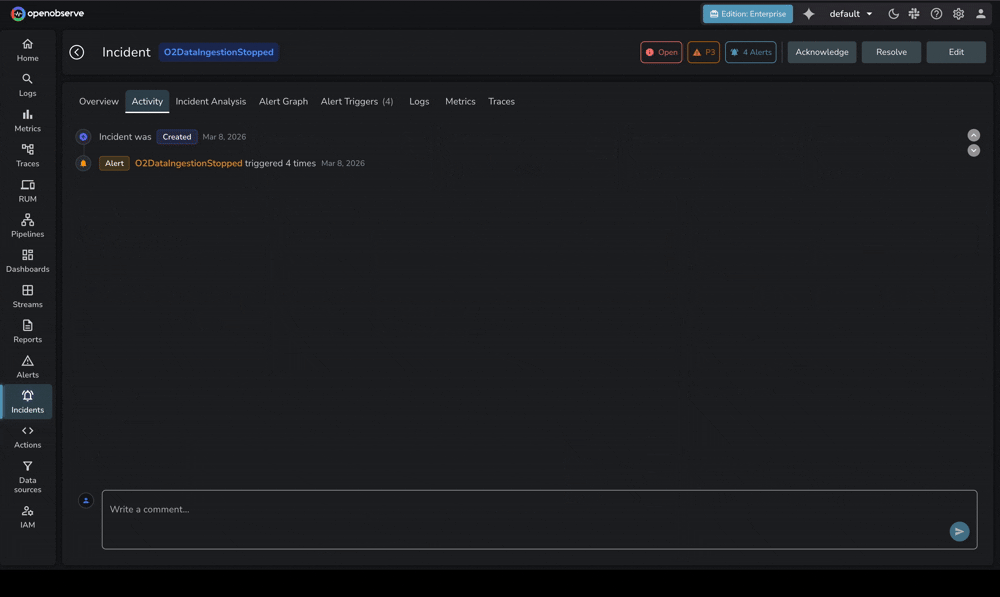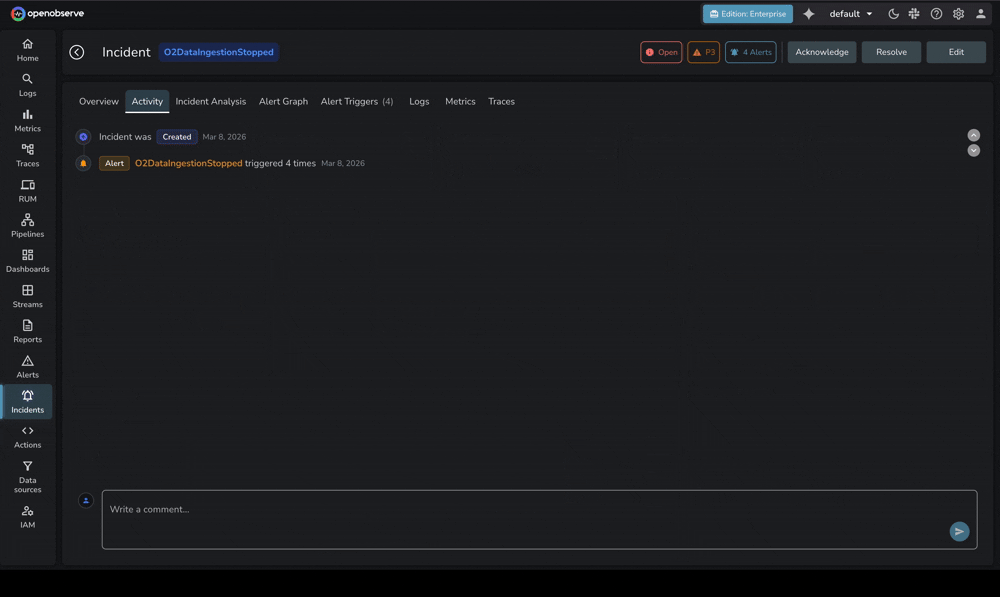
Critically, OpenObserve's AIOps capabilities maintain transparency. When the O2 SRE Agent identifies a root cause, engineers can review exactly which logs, metrics, and traces informed the analysis—building trust and enabling teams to learn from AI reasoning.
For organizations serious about AI-powered operations, the observability foundation isn't a secondary concern—it's the primary determinant of success.
For a detailed comparison of leading AIOps platforms and their capabilities, see our guide: Top 10 AIOps Platforms in 2026.
Looking ahead, AIOps will continue evolving toward fully autonomous operations. Key trends to watch:
Agentic AI orchestration: AI agents that not only diagnose issues but coordinate remediation across multiple systems and teams.
Continuous learning loops: Systems that improve automatically from every incident, building organizational memory that never forgets.
Proactive issue prevention: Shifting from reactive incident response to predictive maintenance that prevents failures before they occur.
Unified AIOps + LLMOps: As organizations deploy more AI-powered applications, monitoring AI systems themselves becomes critical. Platforms that handle both traditional IT operations and LLM observability will win.
For organizations ready to embrace this future, the path forward is clear: invest in a comprehensive, cost-efficient observability foundation that can feed AI models with full-fidelity data. The intelligence of your operations depends on it.
New to OpenObserve? Register for our Getting Started Workshop for a quick walkthrough.
Try OpenObserve: Download for self-hosting or sign up for OpenObserve Cloud with a 14-day free trial.
Manas is a passionate Dev and Cloud Advocate with a strong focus on cloud-native technologies, including observability, cloud, kubernetes, and opensource. building bridges between tech and community.












