Preview
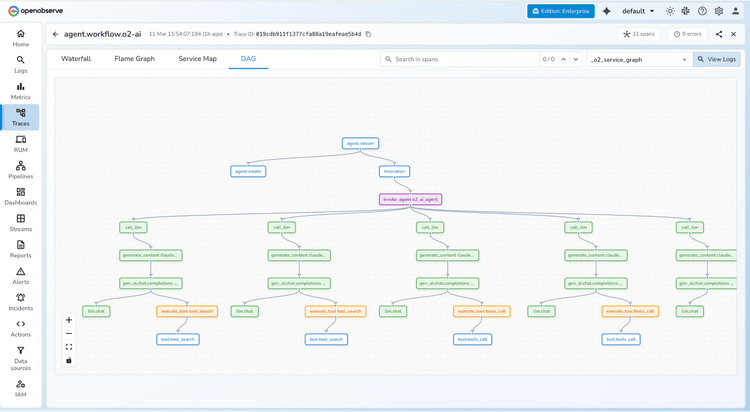
LLM Observability
End-to-end tracing across prompts, responses, and agent workflows.
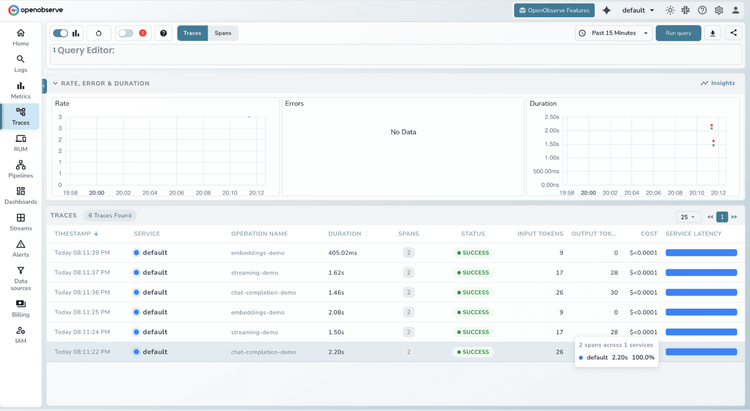
Debug AI Faster
Pinpoint issues across every prompt, tool call, and model response within agent chains.
Eliminate Cost Surprises
Track token consumption and performance across every model.
Own Your Data
Self-host or run in your own cloud, ensuring sensitive prompts and responses never leave your infrastructure.
LLM Observability
Seamless Integration
Multi-Ecosystem Client Support
Connect existing ecosystems like OpenTelemetry, LangChain, and LangFuse to OpenObserve. Ingest instrumentation data immediately, no pipeline re-architecting required.
Unified Schema Normalization
Unify your data schema across all frameworks and model providers. Format incoming telemetry instantly to stop fragmentation and simplify cross-model debugging.
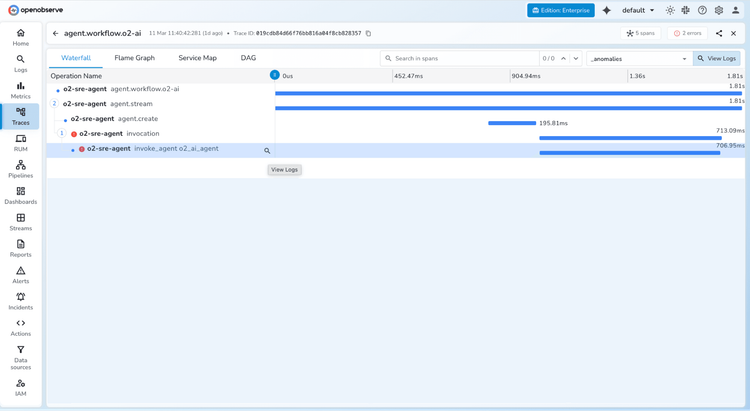
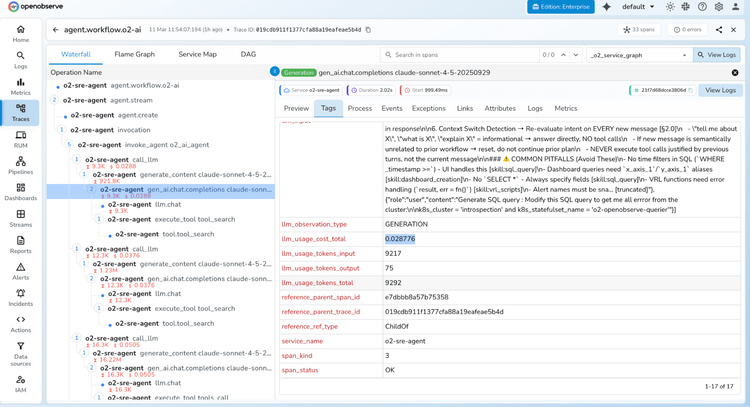
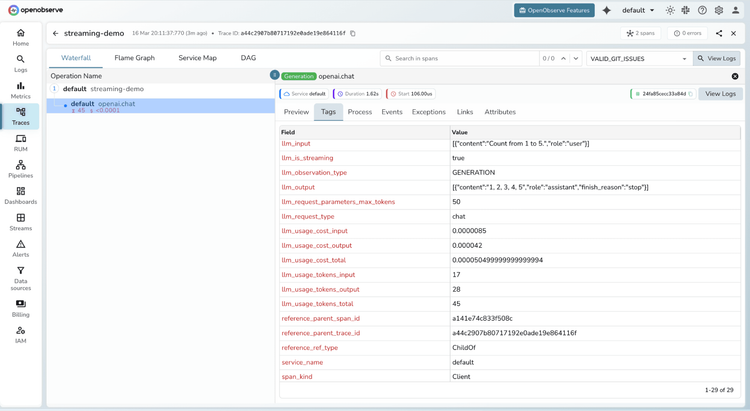
LLM Observability FAQs
Latest From Our Blogs














Ready to get started?
Try OpenObserve today for more efficient and performant observability.