How We Built XDrain in Rust and Why It Made Log Pattern Detection Actually Fast

Ashish Kolhe
March 17, 2026
6 min read
Don’t forget to share!
Try OpenObserve Cloud today for more efficient and performant observability.

Have you ever stared at a search result with millions of log lines and felt like you were just drowning in a wall of text?
For an SRE during an incident, this isn't just a data problem—it's a time-to-resolution problem. The real bottleneck in observability isn't the storage; it's the "intelligence" you can apply to that data in real-time. Instead of manually scrolling through 1,000,000 lines, you need to know instantly that an error is spiking across 50 different servers.
In our previous post, we introduced the concept of automatic log pattern extraction. But once we proved the concept, we hit a new challenge at OpenObserve: making it fast enough to run alongside every single search query without making the user wait.
The goal was to turn those 1,000,000 lines into "5 distinct templates" instantly. We didn't want pre-processing or complex schemas. We wanted it live.
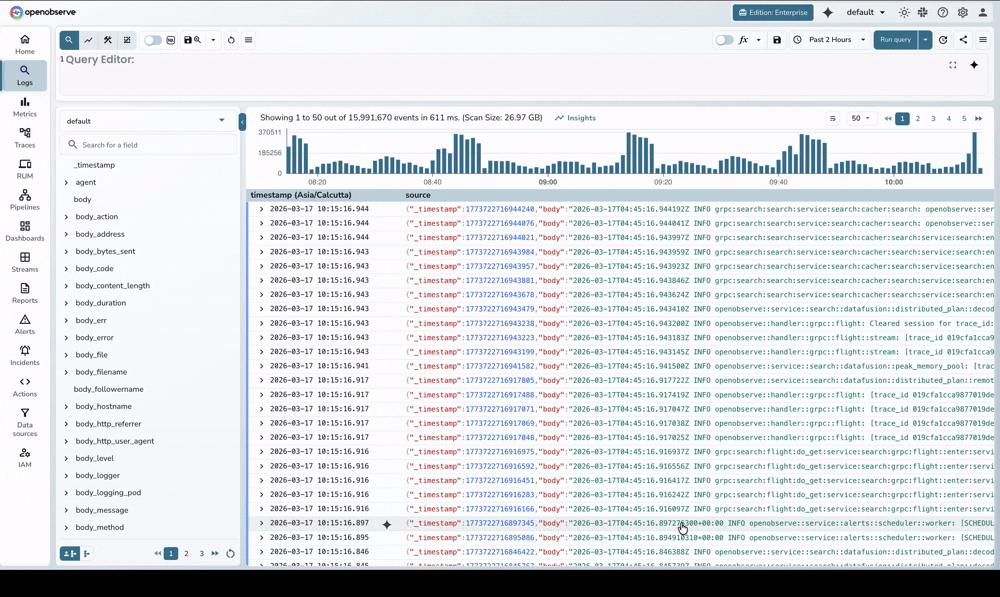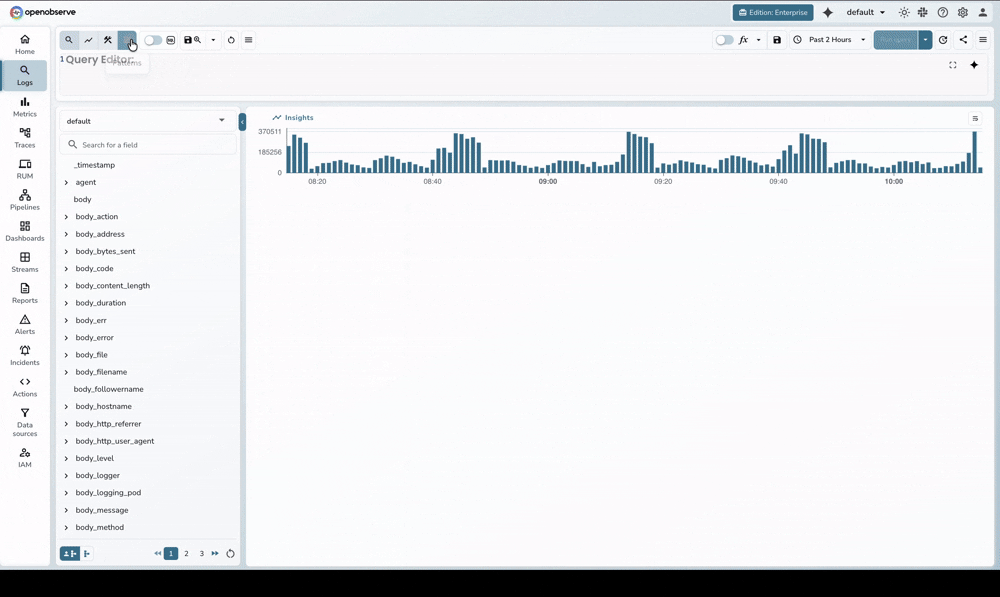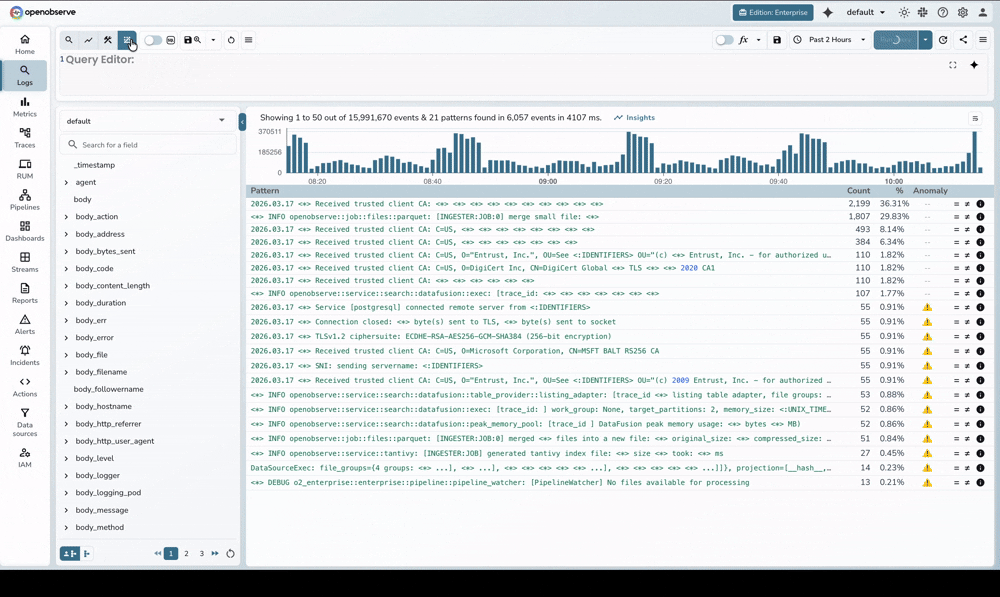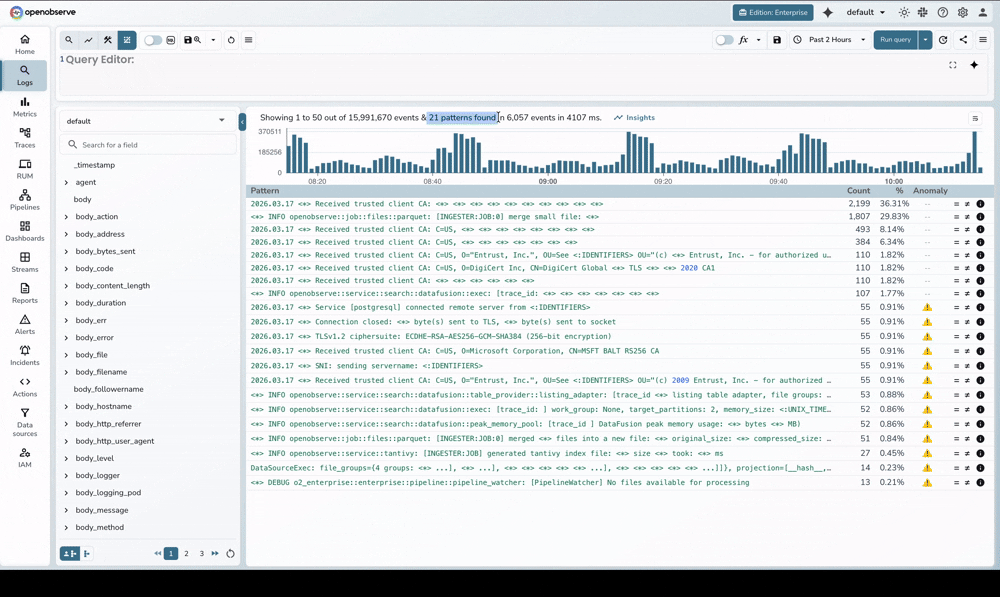
We looked at the academic gold standard, Drain, and its more stable sibling, XDrain. While the original Python implementations were brilliant for research, they struggled with the realities of production. We spent a lot of time researching whether to stick with Python and just optimize the C-extensions, but ultimately, the overhead of Python's Global Interpreter Lock (GIL) and string allocation turned a quick search into a frustrating wait.
So, we did what any performance-obsessed team does: we rewrote it in Rust.
TL;DR: Drain turns unstructured logs into structured templates by identifying common text and grouping variables (like IDs or IPs) into placeholders.
At its heart, the Drain algorithm is a prefix tree (trie). It breaks a log line into tokens and follows branches to see if a similar line has appeared before.
Imagine these two log lines entering the system:
[10:00] User 123 logged in from 1.1.1.1
[10:01] User 456 logged in from 2.2.2.2
The prefix tree processes them like this:
Root
└── User
└── <ID> (Collapses 123 and 456)
└── logged
└── in
└── from
└── <IP> (Collapses 1.1.1.1 and 2.2.2.2)
Resulting Template: User <*> logged in from <*>
However, Drain has a frustrating weakness: it is incredibly sensitive to order. If logs arrive in a slightly different sequence, the tree might branch incorrectly, leaving you with two messy clusters instead of one clean one. XDrain fixes this with a "voting" mechanism: you shuffle the logs, run the parser multiple times, and let the results vote on the most stable template.
In Python, multi-pass shuffling for every search request is a performance nightmare. In Rust, we could make it fly.
We didn't pick Rust just for the "cool factor." We needed three specific things to make search-time analysis viable:
Zero-Cost Abstractions: Traversing prefix trees and calculating similarity scores needs to happen without runtime baggage.
Predictable Memory: In a "noisy" log stream (think: unique UUIDs in every line), memory can explode. We needed a way to cap memory strictly so one heavy search doesn't crash the entire node.
Hardware Acceleration: We wanted to use vectorscan-rs (Intel's Vectorscan) for masking. Rust's FFI makes this low-level C integration seamless.
Ecosystem Synergy: OpenObserve is built from the ground up in Rust. It's the language we know best, and by writing XDrain in the same stack, we avoid "impedance mismatch"—the library can be embedded directly into our query engine for maximum performance without any serialization overhead.
One of the biggest concerns with search-time analysis is "noisy neighbors." To prevent memory bloat, we used a dual-mode cluster storage system via the lru crate. If a log stream gets too chaotic, older patterns get evicted automatically.
enum ClusterStorage {
Unbounded(HashMap<ClusterId, Cluster>),
Bounded(LruCache<ClusterId, Cluster>),
}
By using an enum, we let the type system enforce memory limits at compile time. We don't need to pepper the code with if/else checks everywhere; the code path remains clean, and the performance overhead is virtually zero.
One thing that kept us up at night was the "First-N" trap. If you only process the first 10,000 logs and call it a day, you're biased toward the beginning of your time range. You'll completely miss error patterns that only show up at the end of the query window.
We implemented systematic sampling in our PatternAccumulator. As more logs arrive, we calculate a sampling interval that grows, effectively grabbing a representative sample across the entire result set.
let sampling_interval = if total_count > max_capacity {
total_count / max_capacity
} else {
1
};
if total_count % sampling_interval == 0 {
process_log(log);
}
If you have 1,000,000 logs but a 10k cap, this logic ensures you're seeing a "slice" of the whole million. It gives you a representative skeleton of the data rather than just the first 1%.
We benchmarked the Rust implementation against the original Python logic using mixed logs (HDFS, Apache, Syslog):
| Mode | Throughput |
|---|---|
| Python XDrain | ~9,000 logs/sec |
| Rust XDrain (Single Pass) | ~361,000 logs/sec |
| Rust XDrain (Homogeneous logs) | ~676,000 logs/sec |
| Rust XDrain (Voting/3 Shuffles) | ~60,000 logs/sec |
On average, the Rust implementation is 40x faster. While the "Voting" mode is significantly slower than the single-pass mode, it still clears 60k logs/sec. That turns a 20-second wait into a sub-second response—which is the difference between a tool being "useful" and being "annoying."
Type Safety is a Feature: Using enums for configuration instead of boolean flags made the logic significantly more robust. The compiler simply won't let you forget an edge case.
LRU is Mandatory: In the real world, log data is messy. Without bounded storage, a noisy stream will eat your RAM.
Strategy > Size: How you sample matters more than how much you sample. Systematic sampling provides much better patterns than simple truncation.
We are already working on ways to improve the "Voting" performance further. We're currently looking into Parallel Voting using Rayon to run the shuffle passes concurrently. This should bring multi-pass speeds much closer to our single-pass benchmarks.
If you're building observability tools, check it out—and feel free to drop a comment if you want to geek out over prefix tree implementations!
New to OpenObserve? Register for our Getting Started Workshop for a quick walkthrough.
Try OpenObserve: Download for self-hosting or sign up for OpenObserve Cloud with a 14-day free trial.
Ashish leads Engineering at OpenObserve. Ashish is obsessed with building high performance systems with simplicity in mind. He has vast experience in multiple disciplines like streaming, analytics, big data and more.













