Log Searching and Filtering

Simran Kumari
October 29, 2025
11 min read
Don’t forget to share!
Try OpenObserve Cloud today for more efficient and performant observability.
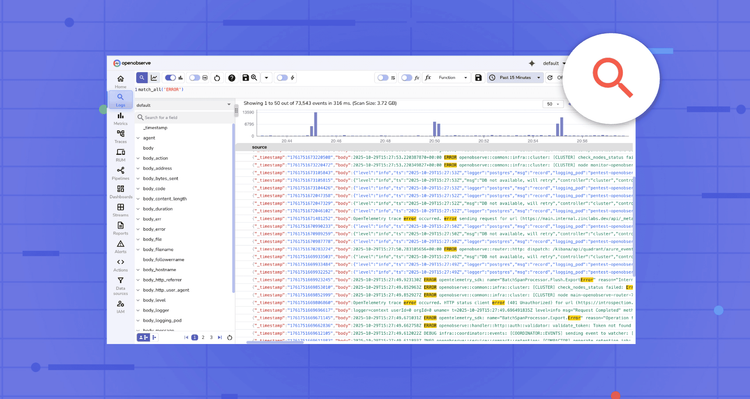
Logs are the heartbeat of modern applications. They help you debug issues, monitor system health, and understand user behavior. But with massive volumes of logs generated every second, finding relevant information quickly becomes challenging. That’s where log searching and filtering come in.
In this blog, we’ll cover:
Before diving into searching and filtering, it’s important to understand what logs look like. Broadly, logs fall into two categories:
Structured logs are machine-readable and contain clearly defined fields. For example:
{
"timestamp": "2025-10-15T10:23:45Z",
"service": "login",
"level": "ERROR",
"user_id": "12345",
"message": "Failed login attempt"
}
Advantages:
There are several structured log formats : JSON, key-value pairs, CSV-style lines, and even semi-structured formats generated by frameworks or log libraries. For simplicity and consistency, we’ll focus on JSON logs, since they’re the most common.
Unstructured logs are freeform text, often written by developers or applications without a defined schema:
2025-10-15 10:23:45 ERROR [login] User 12345 failed to login due to invalid password
Challenges:
Whether structured or unstructured, the goal of log searching is the same: find relevant information quickly. Filtering helps narrow down results to meaningful subsets.
Here’s a structured approach:
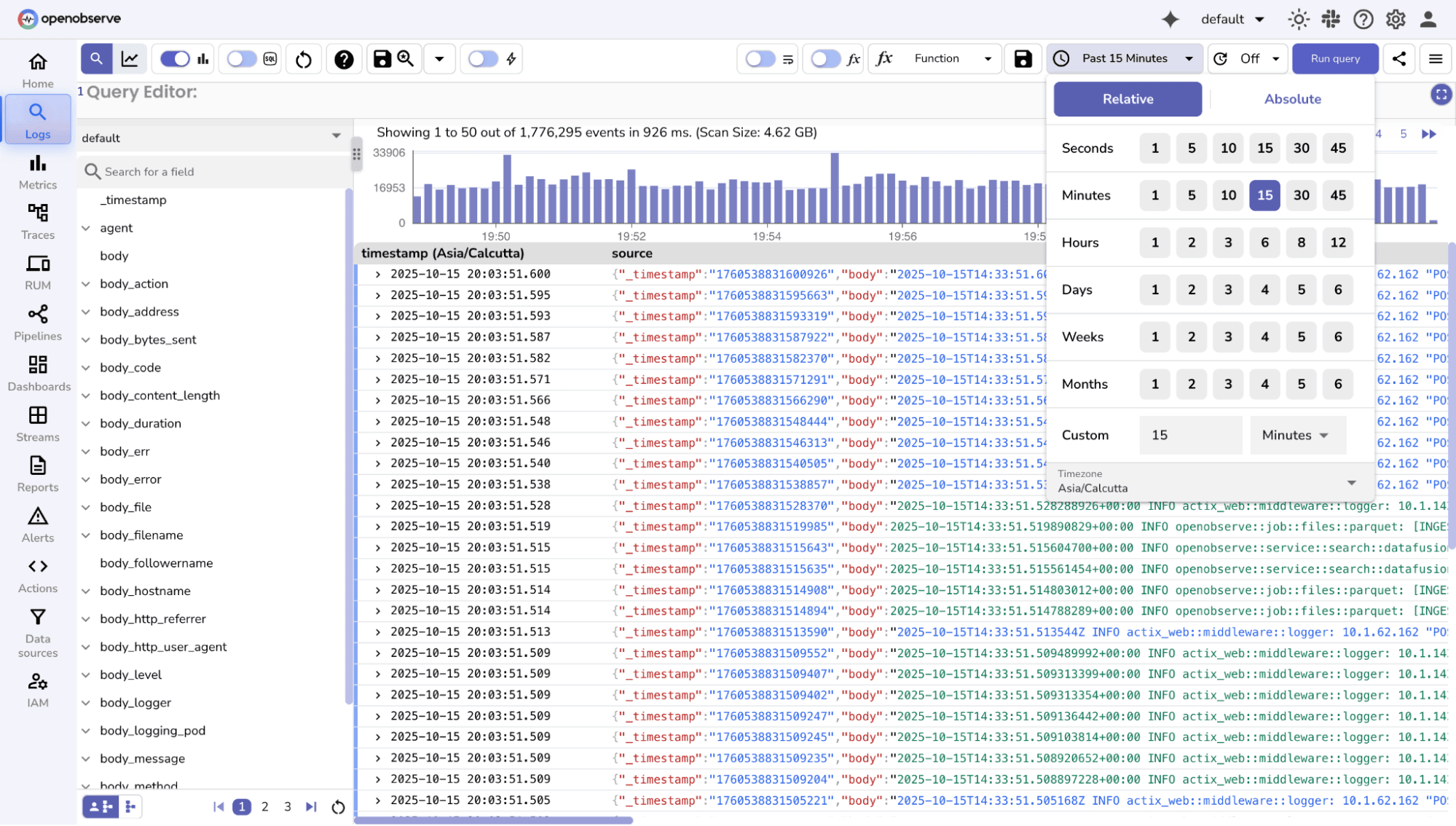
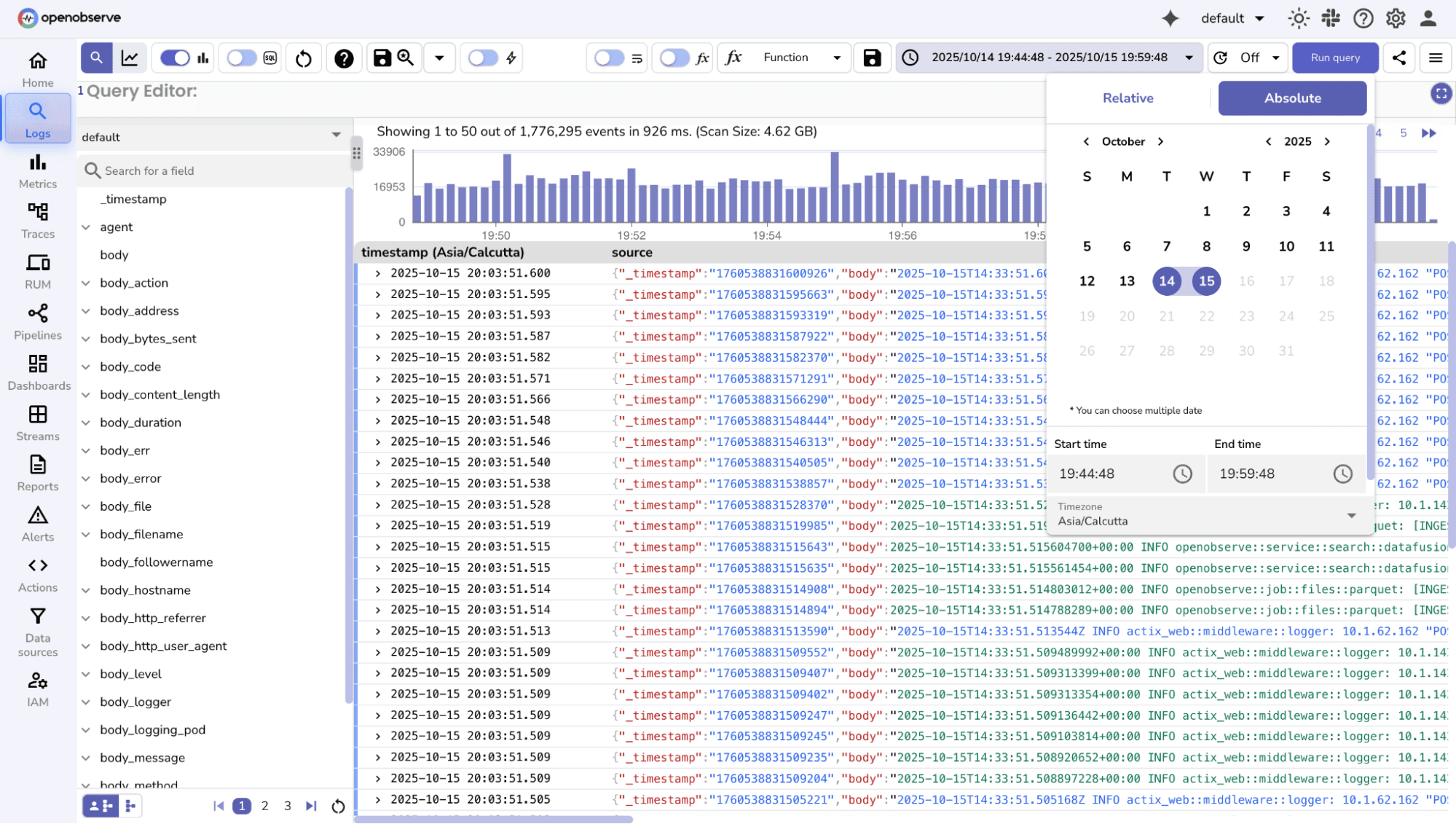
Time is usually the first filter you apply when exploring logs. Filtering logs within a specific time range, e.g., last hour, day, or week is essential for isolating incidents and analyzing trends.
OpenObserve lets you filter logs by time directly from the UI, without any queries. You can choose predefined relative ranges (last 5 minutes, hour, 24 hours, 7 days) for real-time monitoring, or select custom start and end times for detailed analysis or audits.
Filtering logs by specific fields helps you zoom in on relevant information. Fields are attributes associated with logs, such as service name, log level, host, user ID, or custom tags.
OpenObserve Approach:
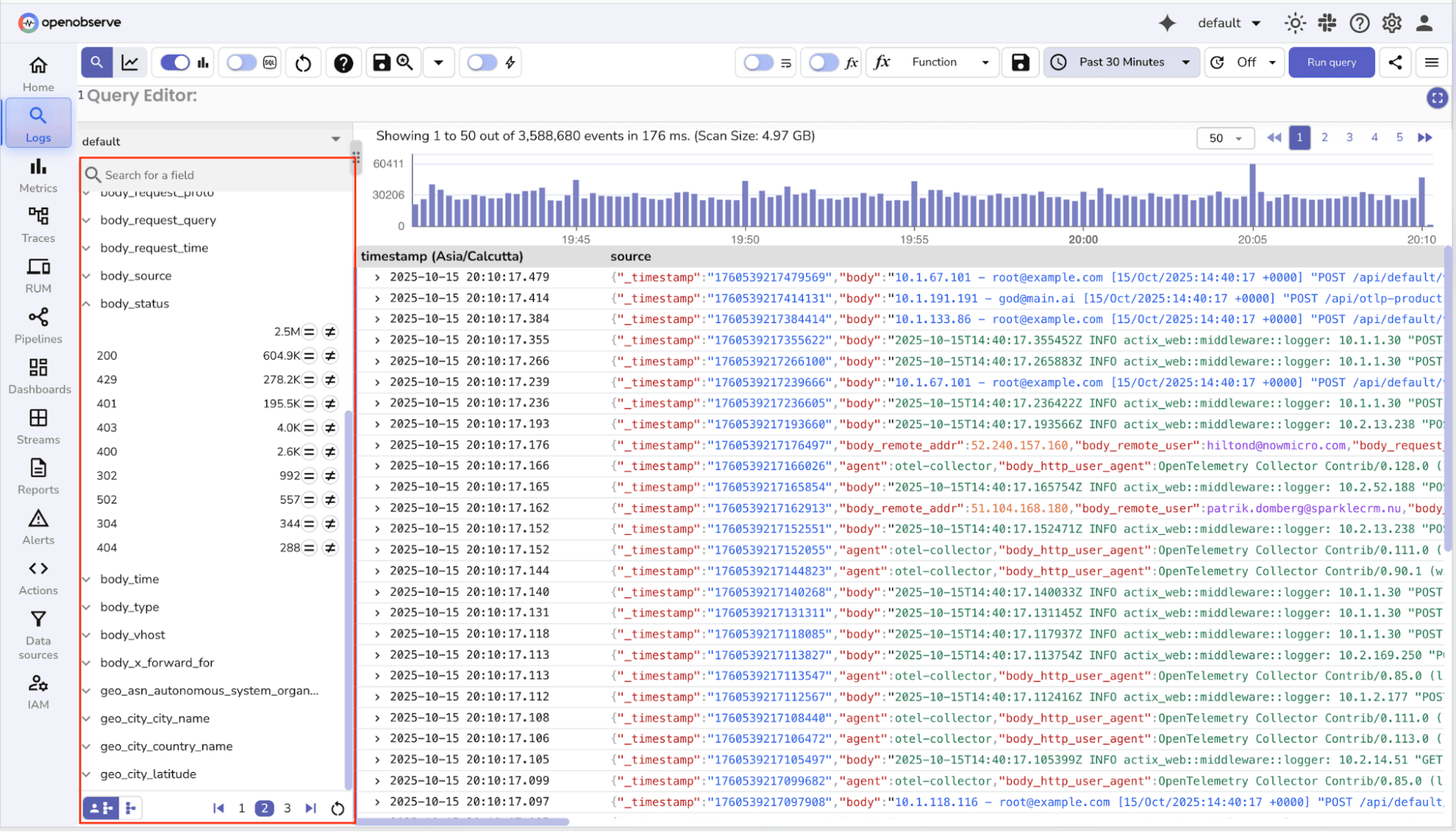
You can select a field (e.g., service=login or level=ERROR) and instantly see matching logs.
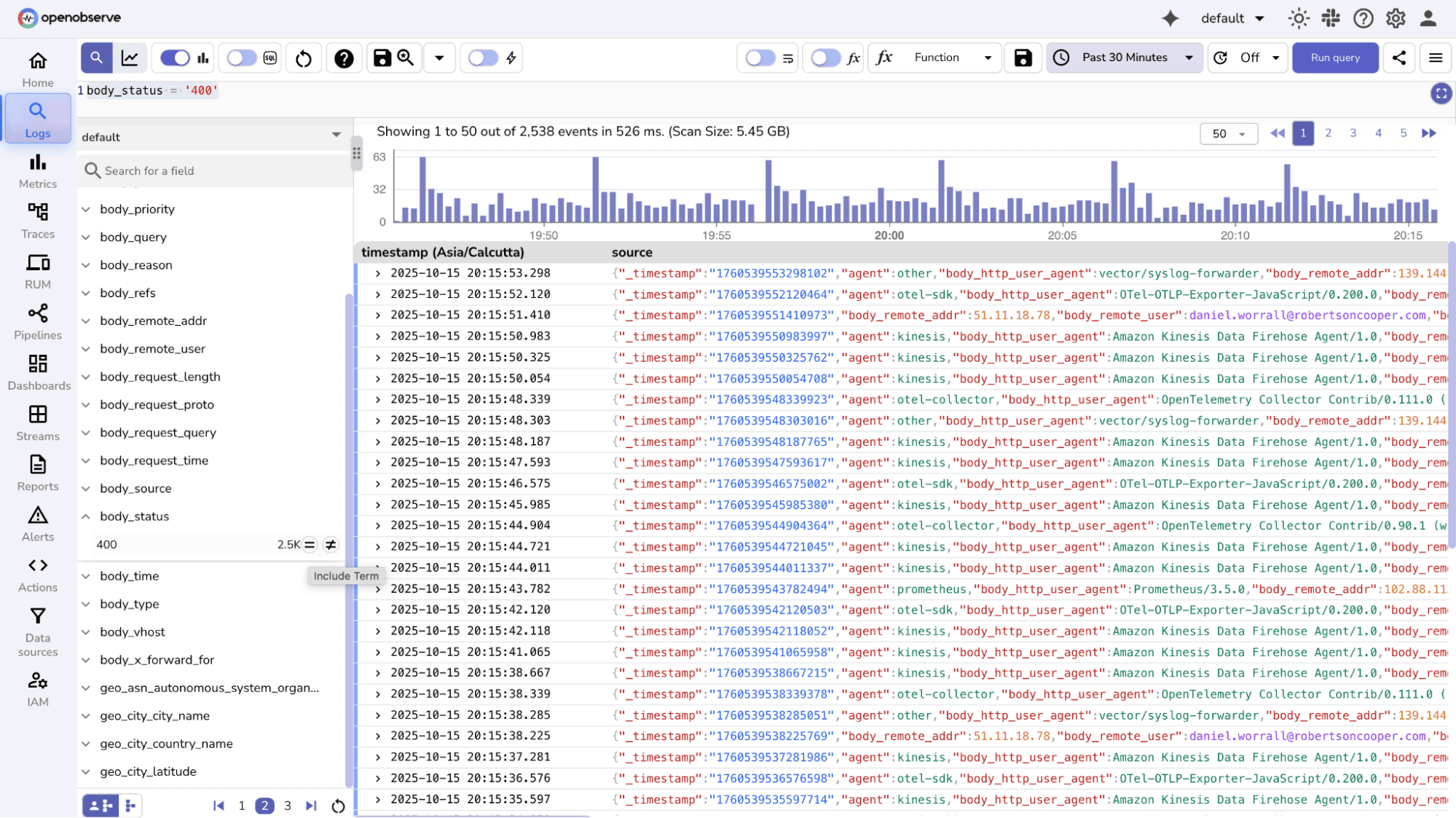
Multiple fields can be combined to focus on specific services, severity levels, hosts, or users, making investigations faser and more precise. You can make use of AND and OR to combine multiple conditions.
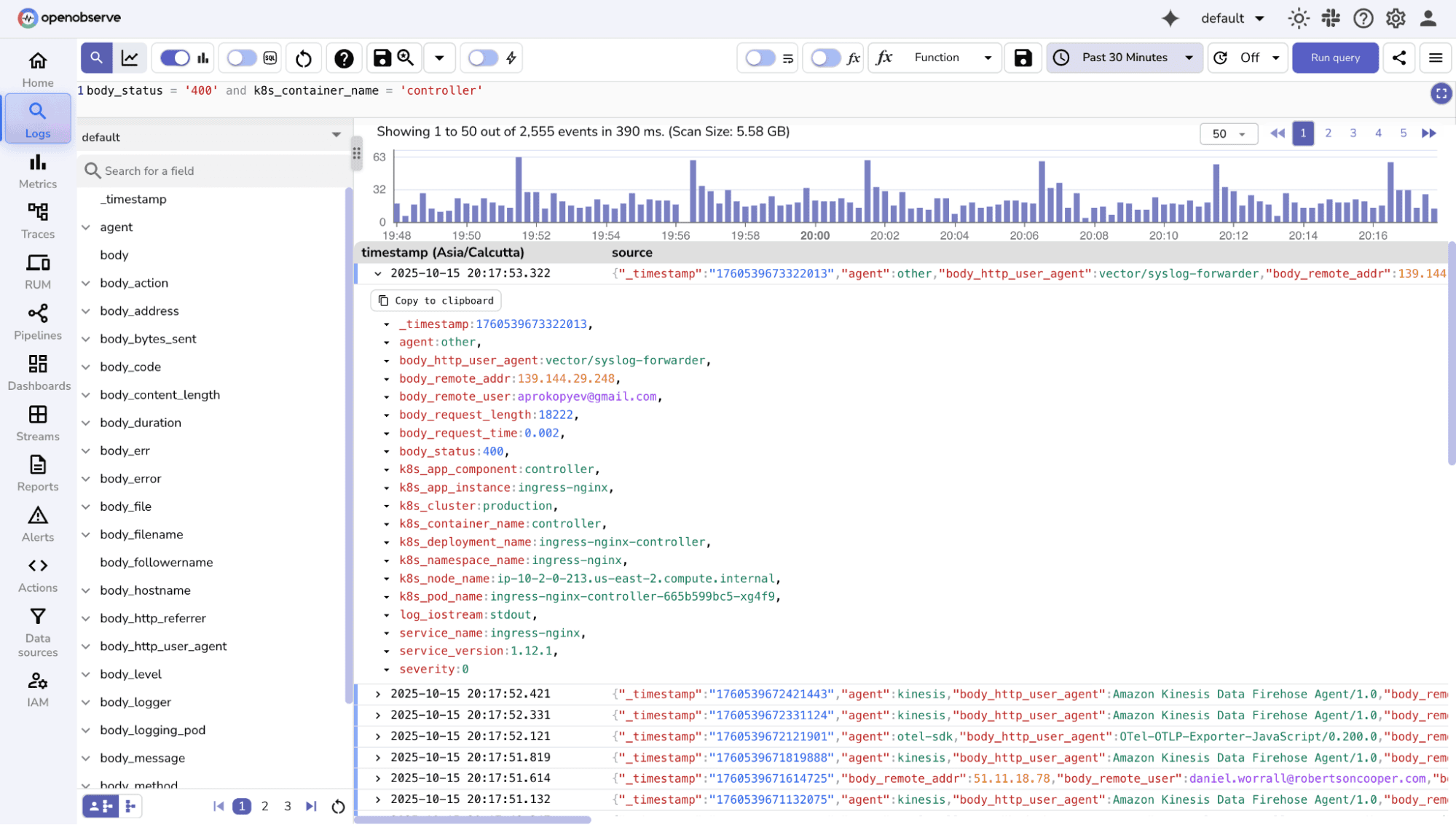
Besides categorical fields, numeric fields like status codes or response times can also be filtered using comparison operators. For numeric field comparison you can use statements like status_code = 200 , status_code > 399, status_code is null to filter out relevant data.
You can enable SQL mode and look for relevant fields and corresponding values using SQL queries.
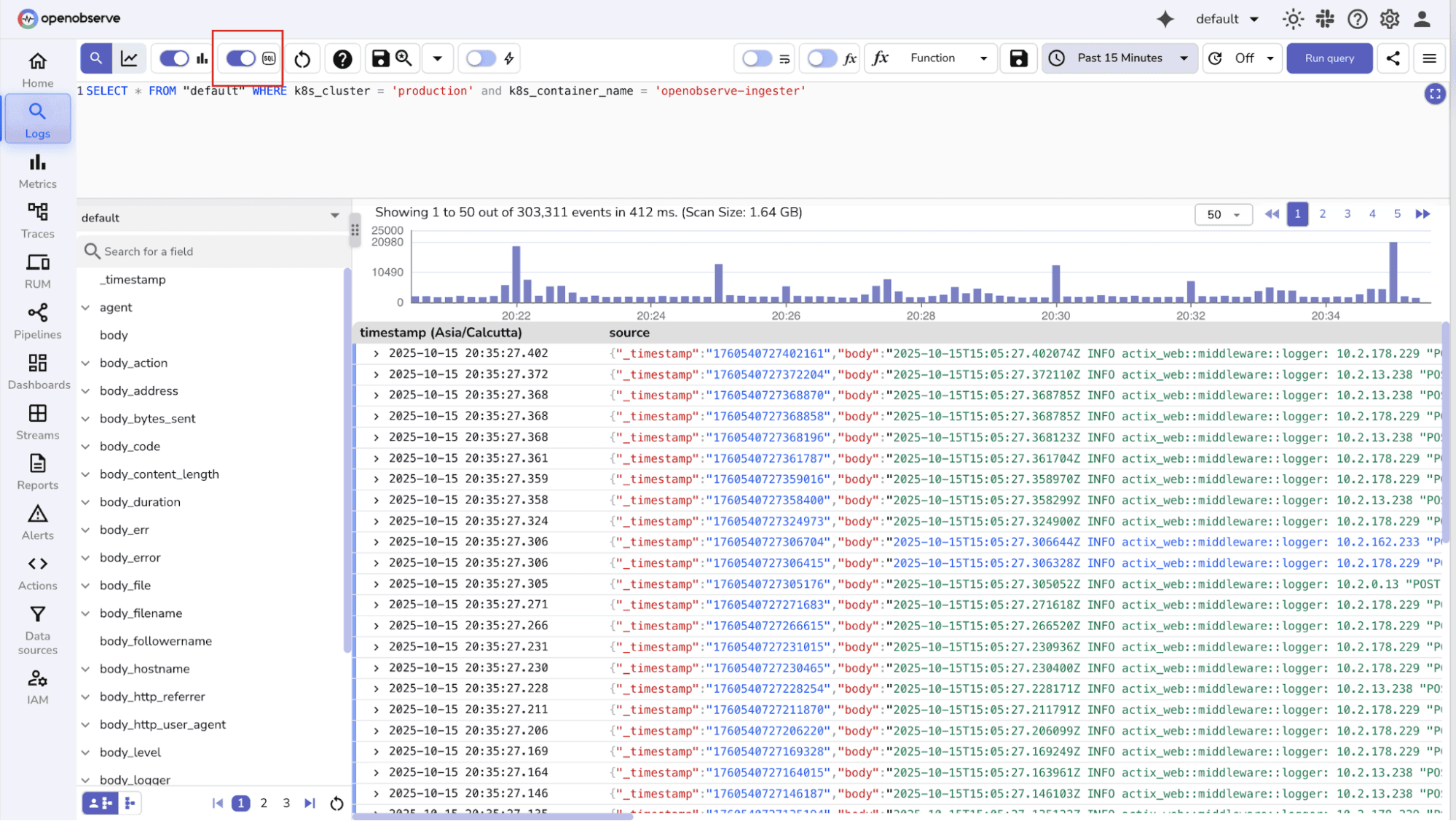
Keyword search is the simplest way to find relevant logs: just look for specific words, phrases, or patterns.Pattern search (using regex or wildcards) allows finding more complex matches, especially in unstructured logs.
OpenObserve Approach:
str_match() function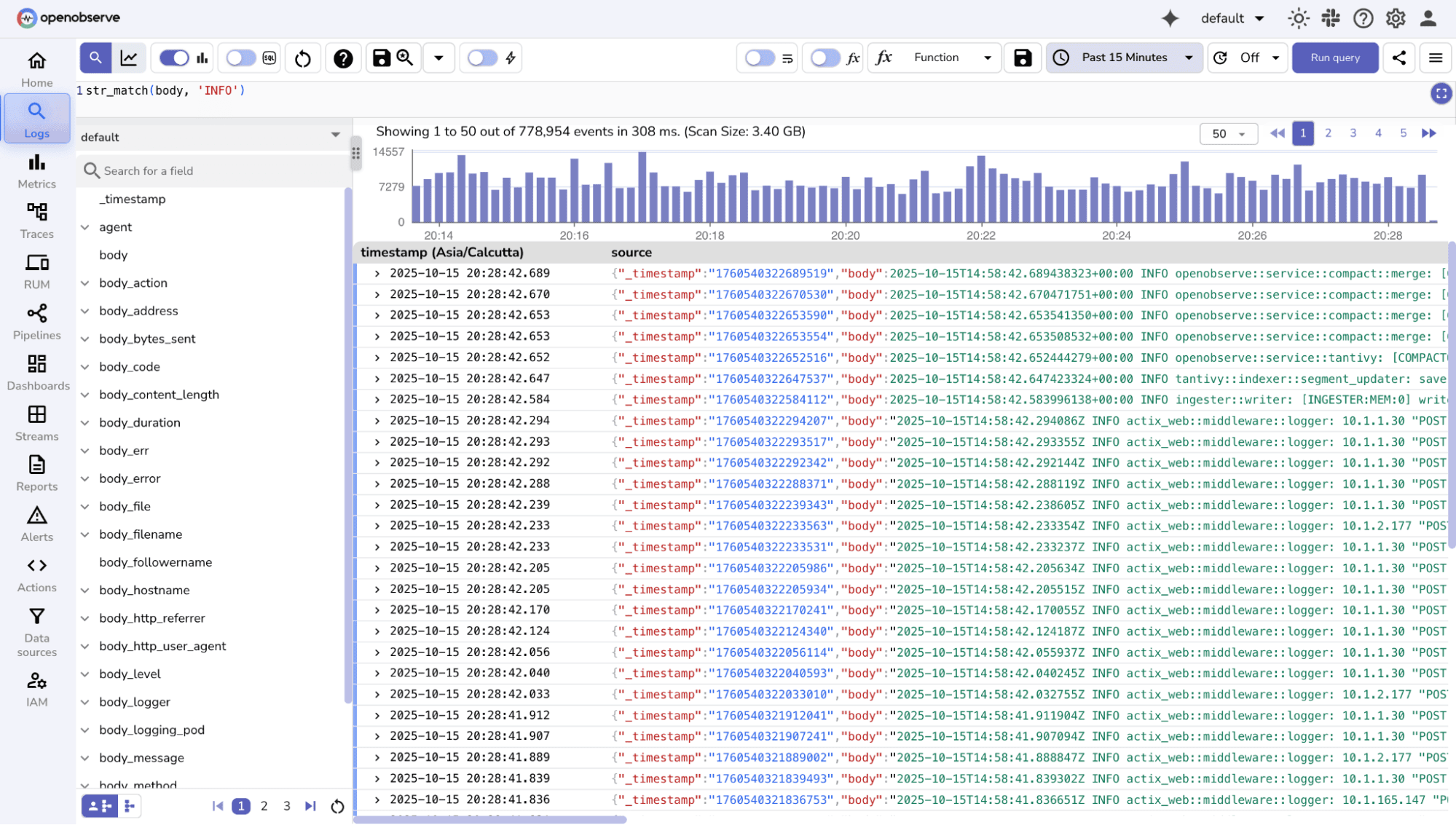
Similarly there are a bunch of functions you can use to search for relevant keywords, check out the detailed documentation here.
re_match, making it easy to identify repeated errors, exceptions, or unusual events.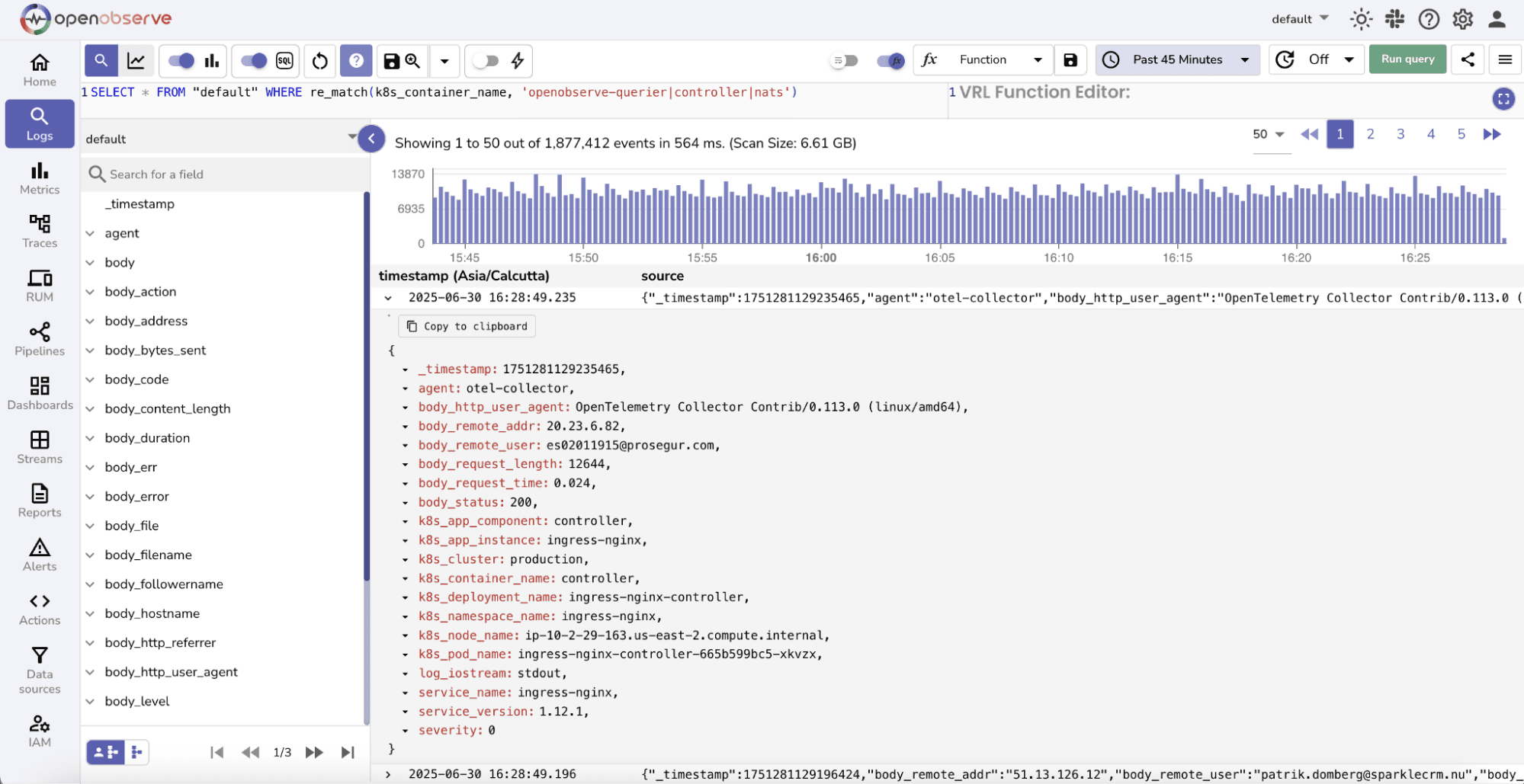
The type of log you’re dealing with influences how you search and filter. Structured logs allow direct field-based queries, while unstructured logs often require keyword or pattern searches. Regardless of the type, you can always apply time filters to narrow down your results.
Once you understand filtering basics, here’s how to express them in OpenObserve.
Note: These functions are for additional help; you can always use SQL queries directly to filter, match, or search logs as needed.
| Function | Syntax | Description | Example |
| str_match | str_match(field, 'value') Alias: match_field(field, 'value')
|
Filters logs where the specified field contains the exact string (case-sensitive). | SELECT * FROM "default" WHERE str_match(k8s_pod_name, 'main-openobserve-ingester-1')
|
| str_match_ignore_case | str_match_ignore_case(field, 'value') Alias: match_field_ignore_case(field, 'value')
|
Filters logs where the field contains the string (case-insensitive). | SELECT * FROM "default" WHERE str_match_ignore_case(k8s_pod_name, 'MAIN-OPENOBSERVE-INGESTER-1')
|
| match_all | match_all('value')
|
Searches across all full-text indexed fields (case-insensitive). | SELECT * FROM "default" WHERE match_all('openobserve-querier')
|
| re_match | re_match(field, 'pattern') Case-insensitive: re_match(field, '(?i)pattern')
|
Filters logs by regex pattern. Useful for complex matches or multiple keywords. | SELECT * FROM "default" WHERE re_match(k8s_container_name, 'openobserve-querier')
|
| re_not_match | re_not_match(field, 'pattern')
|
Returns logs where the field does not match the regex pattern. | SELECT * FROM "default" WHERE re_not_match(k8s_container_name, 'openobserve-querier')
|
service='payments' AND code >= 500
service='login' AND message LIKE '%failed%'
service='api' AND response_time > 2000
match_all('staging') AND str_match(service, 'payments')
re_not_match(k8s_container_name, 'openobserve-querier|controller')
When debugging, a single log line rarely tells the full story. You often need to see what happened before and after an error or warning to understand the root cause. That’s exactly what the Search Around feature in OpenObserve helps you do.
The Search Around feature retrieves log entries that were stored immediately before and after a selected record. Unlike filters or queries, it does not apply your original search conditions, this ensures you get the complete surrounding context as it appears in the backend storage.
Essentially, it helps you answer questions like:
search around button at the bottom of the page:
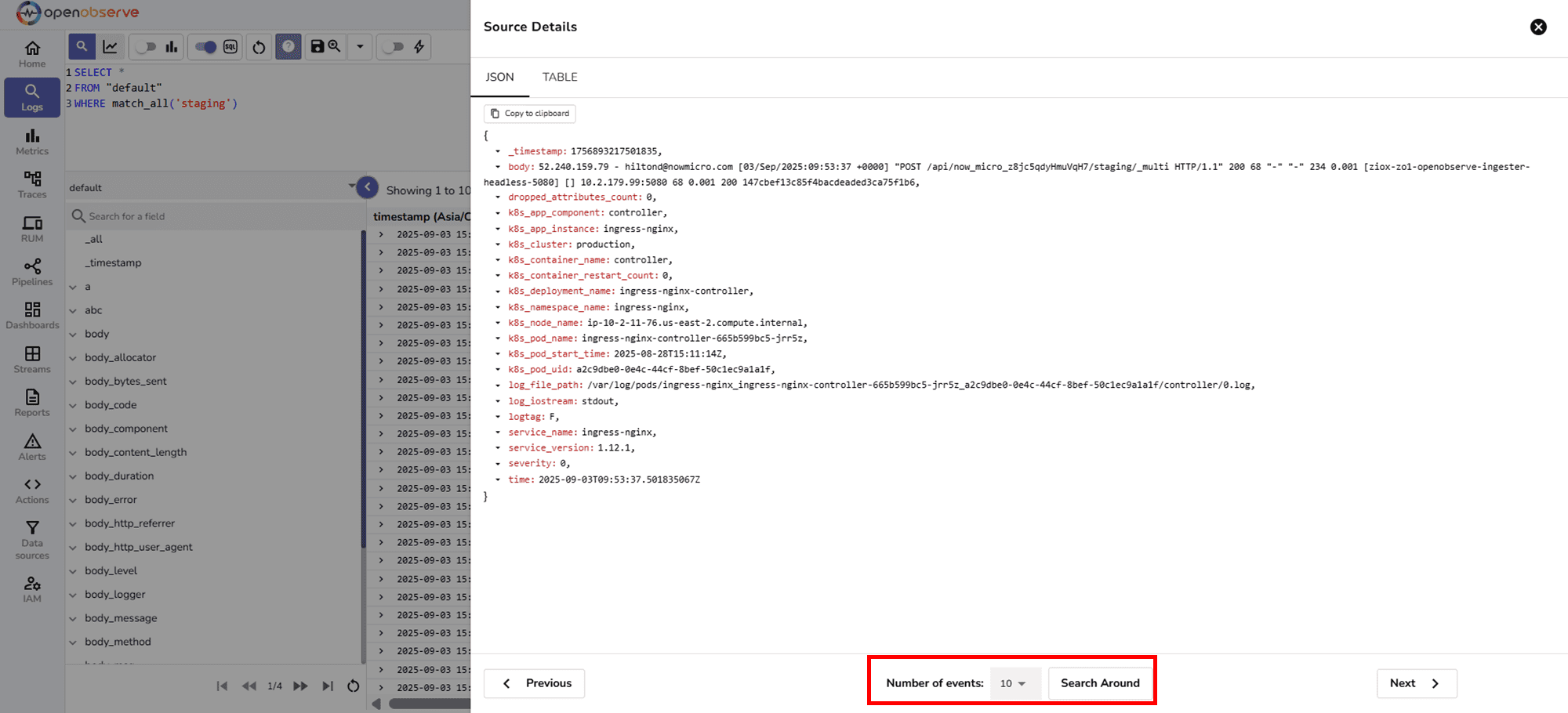
Search Around.
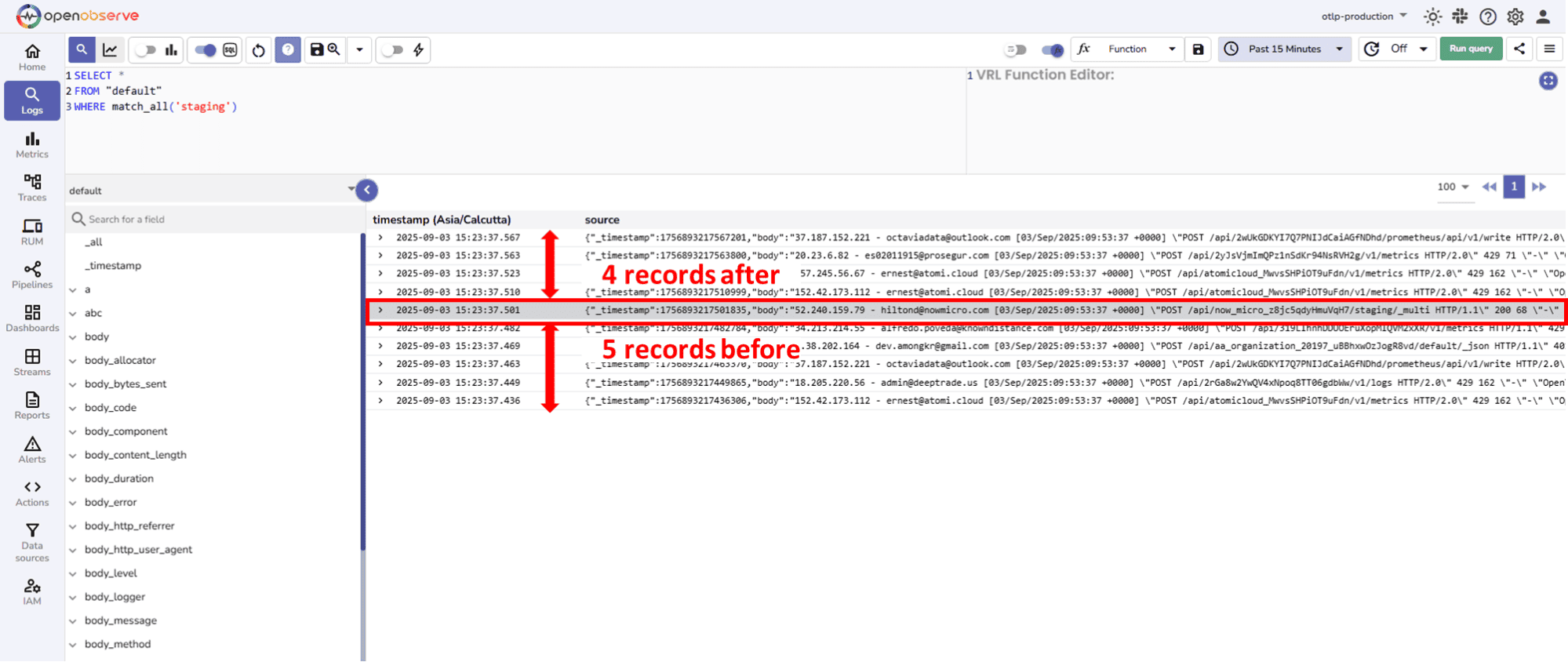 For example, when you select 10, the result set contains 10 records in total, including the selected record. The split is 5 records before the selected record and 4 records after.
For example, when you select 10, the result set contains 10 records in total, including the selected record. The split is 5 records before the selected record and 4 records after.Once you’ve searched and filtered logs, the next step is aggregation, summarizing log data to uncover trends, patterns, and insights that individual log lines alone cannot reveal.
Why Aggregation Matters
Common Aggregation Techniques
Count & Group By
service, level, or host.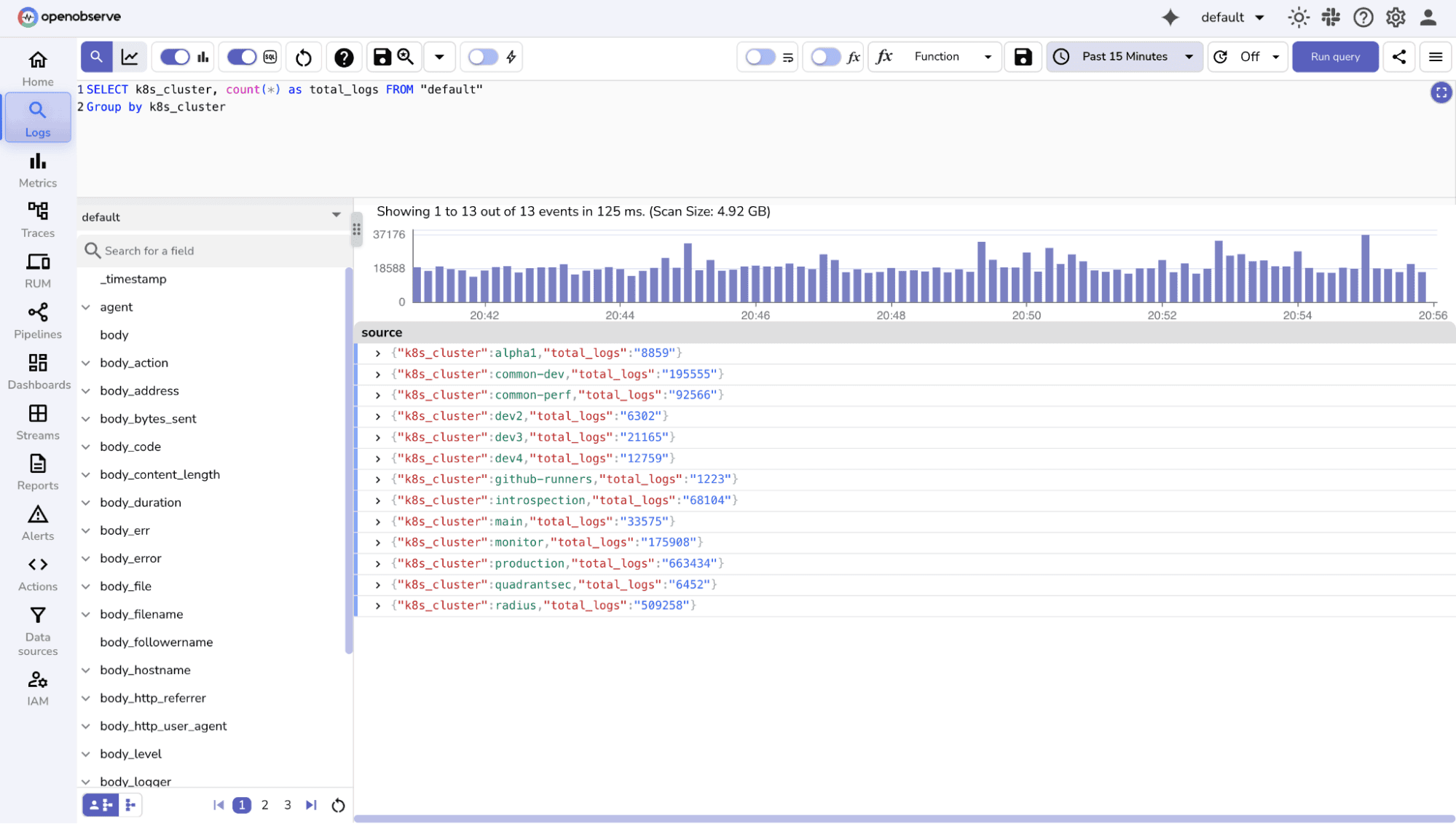
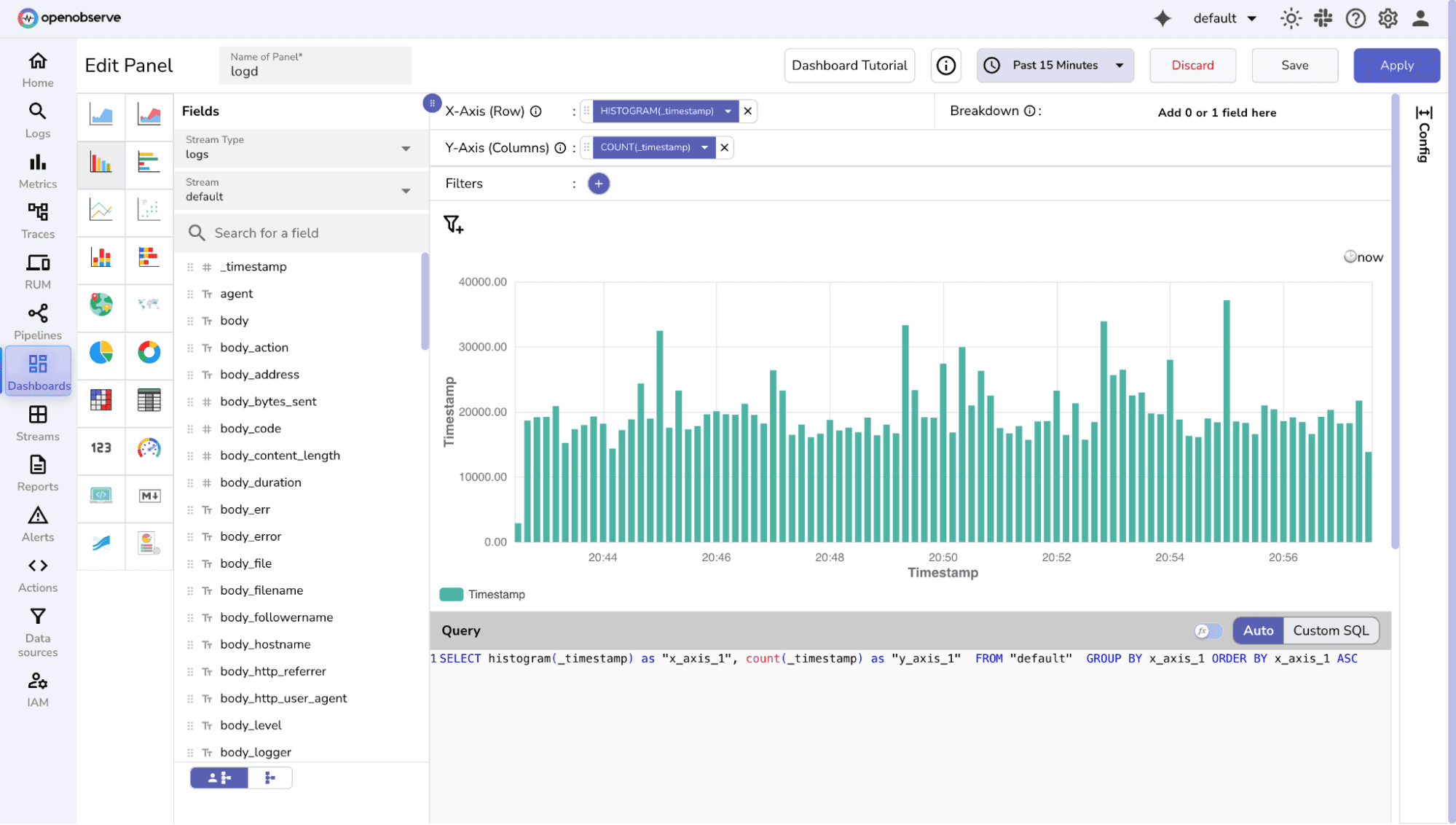
Time-Based Histograms
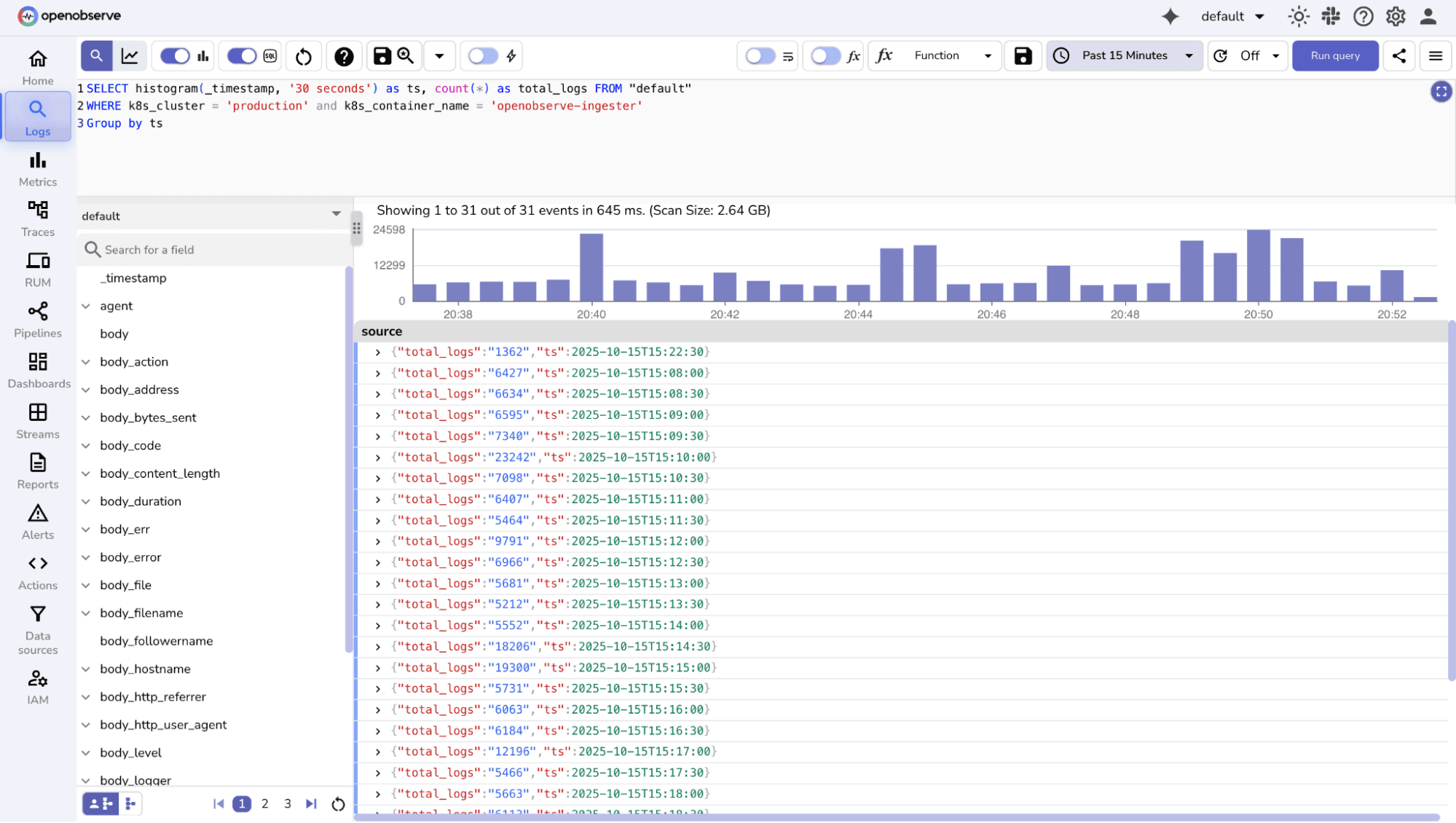
Top-N Analysis
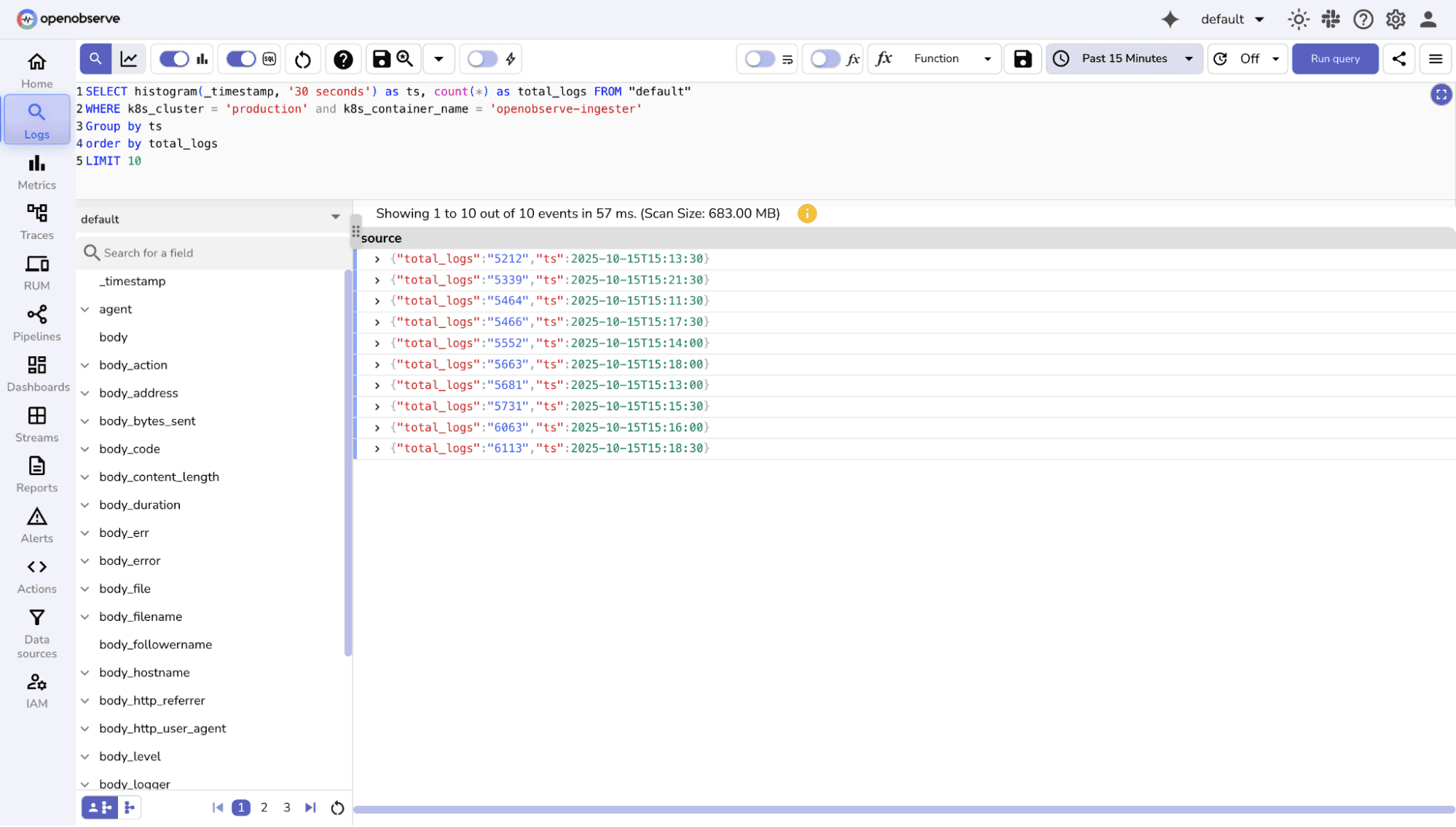
OpenObserve Approach
Best Practices
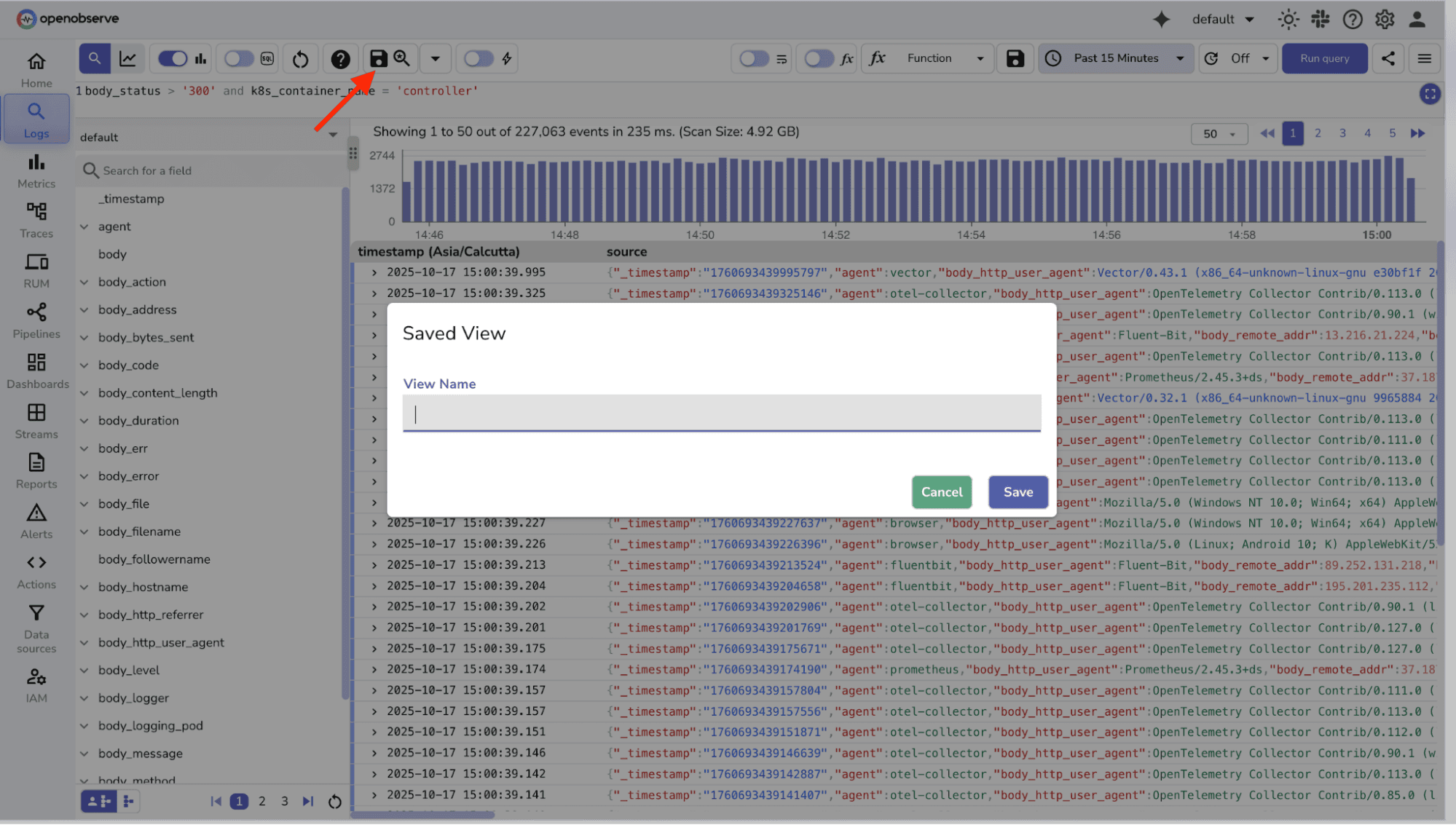
When you repeatedly search for similar patterns like login failures, 5xx errors, or latency spikes, Saved Views help you store and reuse those filters and queries.
With Saved Views, you can:
Example: Save the query: service='payments' AND code>=500 as “Payment Errors”.
Next time you need to debug API issues, you can simply open this Saved View without recreating the query.
Raw logs often need refinement before they can be effectively searched, filtered, or visualized. OpenObserve leverages VRL (Vector Remap Language), a flexible and powerful language designed to transform, enrich, and clean log data in real time during ingestion.
VRL is a lightweight scripting language specifically for observability pipelines. It allows you to manipulate logs: extracting fields, modifying values, redacting sensitive information, and adding contextual metadata without changing the original log source.
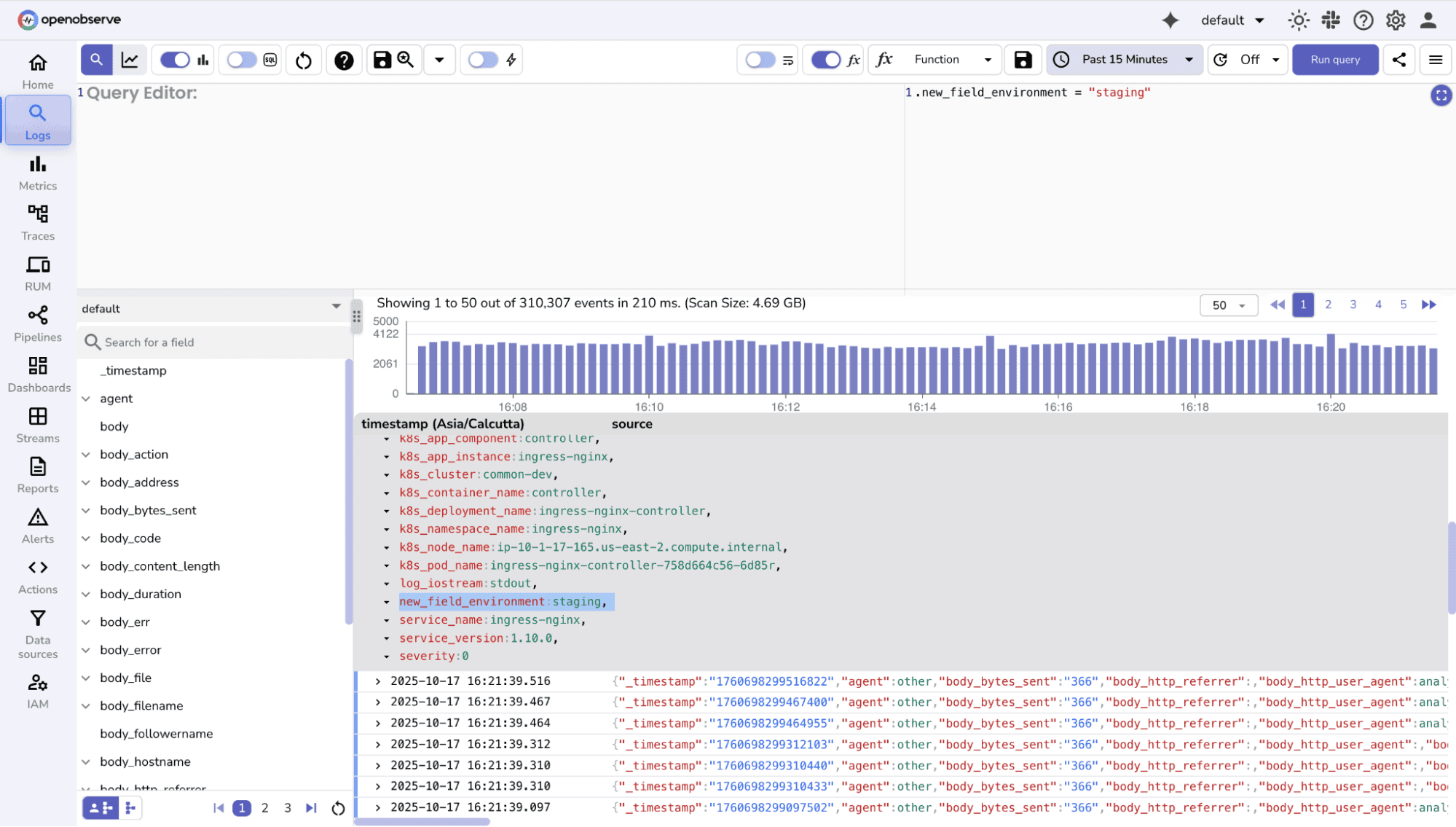
Enrichment : Add contextual information to logs to make them more actionable. For example:
.environment = "staging"
Redaction: Mask sensitive information like passwords, tokens, or PII before storing logs. This ensures compliance with privacy regulations.
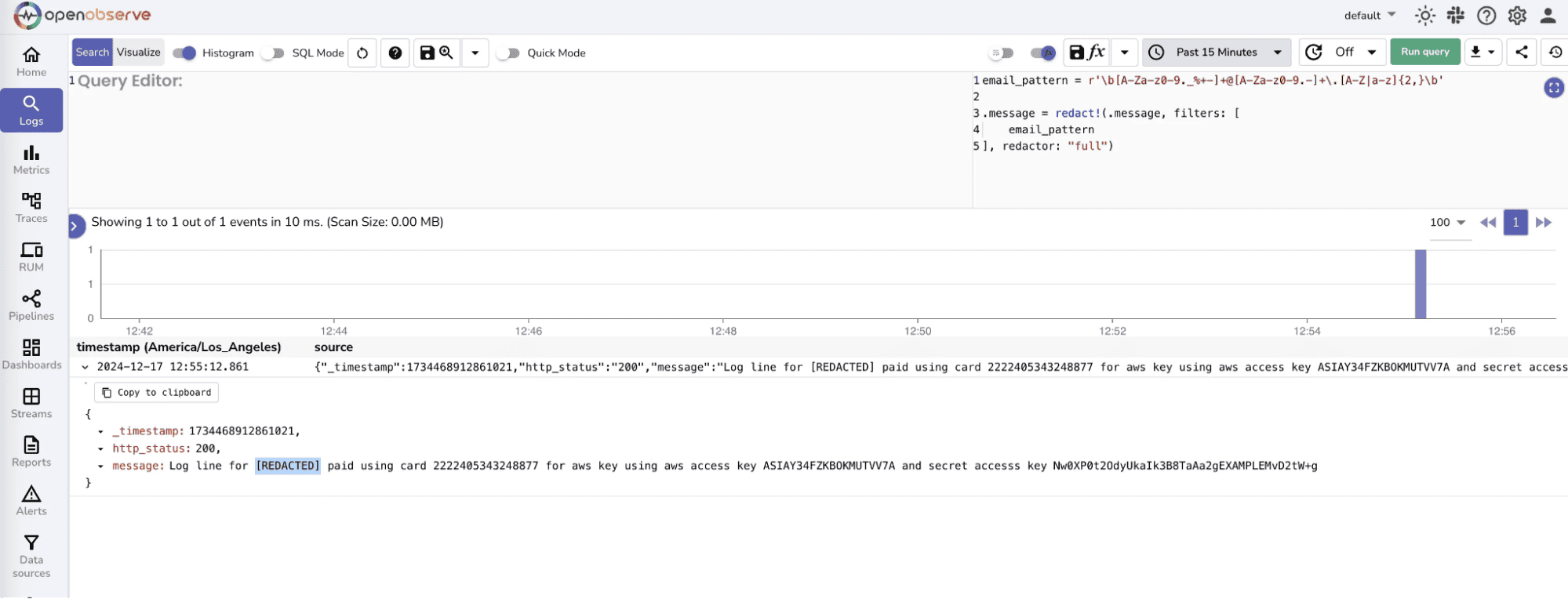 Learn more about How to redact sensitive / PII data in your logs in detail.
Learn more about How to redact sensitive / PII data in your logs in detail.
Field Transformation: Convert or normalize log fields for consistency across services: \
Read about VRL Functions and Expressions.
4. Conditional Routing: You can also use VRL to tag or route logs based on certain conditions, making downstream analysis easier:
if .level == "ERROR" {
.priority = "high"
} else if .level == "WARN" {
.priority = "medium"
} else {
.priority = "low"
}
Logs are the heartbeat of your applications, but finding what matters in a flood of data can be tricky. Understanding the difference between structured and unstructured logs helps you pick the right search and filter approach.
Time, field, and keyword-based filters let you zoom in on relevant events, and aggregation turns raw logs into insights you can act on. OpenObserve makes this easier by automatically extracting fields, supporting flexible searches, and letting you visualize trends all in one place.
By combining these techniques with good practices, you can investigate issues faster, reduce noise, and get a clearer picture of what’s happening in your systems.
Further Reads
Sign up for a 14 day cloud trial. Check out our GitHub repository for self-hosting and contribution opportunities.
Passionate about observability, AI systems, and cloud-native tools. All in on DevOps and improving the developer experience.












