Observability vs. Monitoring: What's the Difference?

Simran Kumari
February 17, 2026
7 min read
Don’t forget to share!
Try OpenObserve Cloud today for more efficient and performant observability.
In today's complex distributed systems, keeping applications running smoothly requires more than just watching dashboards. The terms observability and monitoring often get used interchangeably, but they serve distinct purposes. Understanding how these approaches differ—and when to use each—is essential for building reliable software. This guide breaks down what each practice offers and how they work together.
Monitoring is the practice of collecting, analyzing, and alerting on predefined metrics to track the health of your systems. It answers the question: "Is my system working?"
Traditional monitoring focuses on known failure modes. You define thresholds, set up alerts, and get notified when something crosses a boundary you've established. Think CPU usage exceeding 90%, response times climbing above 500ms, or error rates spiking past 1%.
Observability goes beyond monitoring by enabling teams to understand why systems behave the way they do, even when facing problems they've never encountered before. It answers: "Why is my system broken?"
The term comes from control theory, where a system is considered observable if you can determine its internal state by examining its outputs. In software, observability means instrumenting applications so that any question about system behavior can be answered through the data it produces.
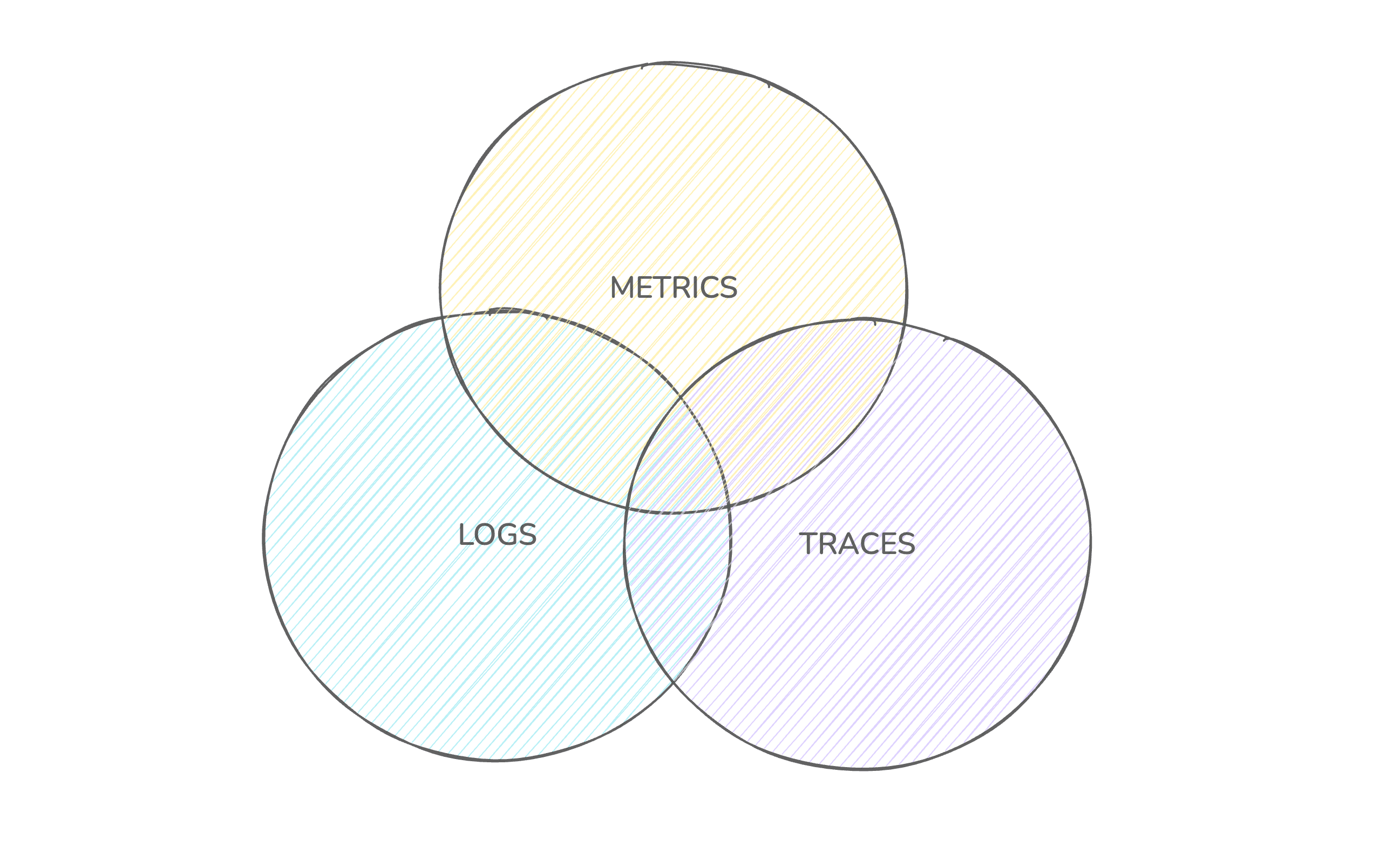
Microservices architectures, containerized deployments, and serverless functions create complexity that traditional monitoring struggles to handle. When a request passes through fifteen services before returning an error, you need more than a red alert on a dashboard.
Observability enables:
| Aspect | Monitoring | Observability |
|---|---|---|
| Primary question | Is it broken? | Why is it broken? |
| Approach | Predefined checks and thresholds | Exploratory investigation |
| Data model | Aggregated metrics | High-cardinality, correlated telemetry |
| Failure handling | Known failure modes | Unknown unknowns |
| Best suited for | Stable, well-understood systems | Complex, distributed architectures |
| Skill requirement | Configuration-focused | Analysis and investigation skills |
Monitoring is inherently reactive. You configure it based on past experience—the failures you've seen before become the alerts you set up. This works well for predictable systems but falls short when novel problems emerge.
Observability supports exploration. Engineers can ask arbitrary questions of their data, drilling down from symptoms to causes without needing predetermined queries. When a new deployment introduces subtle latency in edge cases, observability tools let you investigate without having anticipated that specific failure.
Traditional monitoring aggregates aggressively. Average response time across all endpoints, total error count per minute, median CPU usage. These summaries sacrifice detail for simplicity.
Observability preserves granularity. You can examine the exact sequence of events for a single problematic request, compare behavior between two customer cohorts, or identify that latency only affects users on a specific mobile carrier. High-cardinality data enables these investigations.
The choice isn't binary. Most organizations need both approaches, applied appropriately.
Rather than choosing one approach over the other, mature engineering organizations layer them together.
Many modern platforms blur the lines, offering both monitoring and observability capabilities in unified solutions.
The industry continues moving toward observability-first approaches. As systems grow more distributed and deployment velocity increases, the ability to investigate unknown problems becomes more valuable than detecting known ones.
OpenTelemetry is standardizing instrumentation, making it easier to collect traces, metrics, and logs consistently across languages and frameworks. This reduces vendor lock-in and simplifies adoption.
AIOps and machine learning are augmenting human analysis, helping surface anomalies and correlations that would take engineers hours to find manually. These tools work best when built on rich, observable data.
Monitoring and observability serve different but complementary purposes. Monitoring tells you something is wrong; observability helps you understand why. In simple systems, monitoring alone may suffice. In complex distributed architectures, observability becomes essential for maintaining reliability.
The most effective approach combines both: monitoring for baseline health and known issues, observability for investigation and understanding. By instrumenting systems thoughtfully and building skills in exploratory debugging, engineering teams can maintain reliability even as their architectures grow in complexity.
Start where you are. If you're monitoring-only today, identify your most critical user-facing flows and add tracing. If you have observability data but struggle to use it, invest in training and better dashboards. The goal isn't perfection—it's continuous improvement in your ability to understand and operate your systems.
Sign up for a 14 day cloud trial. Check out our GitHub repository for self-hosting and contribution opportunities.
Passionate about observability, AI systems, and cloud-native tools. All in on DevOps and improving the developer experience.












