Building Modern Observability: Why Rust Powers the Next Generation of Monitoring Platforms

Manas Sharma
November 28, 2025
11 min read
Don’t forget to share!
Try OpenObserve Cloud today for more efficient and performant observability.
Get Started For Free
Your observability platform has one job: stay up so you can see why everything else is down.
Yet across the industry, monitoring tools crash during the exact moments teams need them most. Memory leaks appear under load. Garbage collection pauses create metric gaps during traffic spikes. Race conditions corrupt telemetry data when multiple systems fail simultaneously.
The irony is brutal. The tools built to ensure system reliability often lack that reliability themselves.
This isn't a configuration problem or a deployment issue. It's an architectural problem rooted in the languages these platforms are built with. According to research from Microsoft and Google, approximately 70% of security vulnerabilities in systems software stem from memory safety issues. Your observability platform isn't immune to these problems.
For years, the industry accepted this trade-off. Java makes memory management easier but introduces garbage collection pauses. Go simplifies concurrency but can't eliminate data races at compile time. C++ delivers raw performance but makes memory safety your responsibility.
In 2025, that's changing. A new generation of observability platforms is emerging with Rust as their foundation. This isn't about following trends. It's about solving fundamental reliability problems that traditional languages can't address. Problems that become critical failures when your systems are already down and you need your monitoring tools to work flawlessly.
Traditional observability platforms suffer from a critical flaw. They're built with languages designed for developer productivity, not system reliability. The consequences show up exactly when you need your tools most.
Memory Management Failures
Consider what happens during a traffic spike. Your application starts generating more logs, metrics, and traces. Your Java-based observability tool tries to keep up, but garbage collection kicks in. Those GC pauses create gaps in your metrics. You're flying blind during the exact moment you need visibility.
Memory safety issues include buffer overflows, use-after-free bugs, and memory corruption. These account for over 60% of high severity security vulnerabilities in system codebases. Your observability platform faces the same risks as the applications it monitors.
The Resource Tax
Go-based tools promise better performance through lightweight goroutines. In practice, garbage collection overhead consumes roughly 10% of processing time. When you're ingesting millions of metrics per second, that 10% translates to real infrastructure costs. Worse, GC pauses cause periodic CPU spikes that impact your latency-sensitive applications.
Data Corruption Risks
C++ offers raw performance but requires manual memory management. Race conditions slip through code reviews. During peak usage, when multiple threads are writing metrics concurrently, these race conditions can corrupt your telemetry data. You end up making decisions based on incorrect metrics.
The pattern is clear: traditional observability tools trade reliability for development speed. When you're debugging a P0 incident, that trade-off doesn't work in your favor.
Rust brings a different philosophy to systems programming. It refuses to choose between performance and safety. Through compile-time guarantees, Rust eliminates entire classes of bugs before your code ever runs in production.
Memory Safety Without Garbage Collection
Rust's ownership model prevents memory leaks at compile time. The concept is straightforward: every piece of data has exactly one owner. When that owner goes out of scope, the memory is automatically freed. No garbage collector needed.
fn process_metrics(data: Vec<Metric>) {
// data is owned by this function
for metric in data {
store_metric(metric); // ownership moves to store_metric
}
// data is automatically cleaned up here
// no GC pause, no memory leak possible
}
When you need multiple parts of your code to access the same data without transferring ownership, Rust provides borrowing. You can have either multiple read-only references or a single mutable reference, but never both simultaneously. This rule eliminates data races at compile time.

The compiler enforces these rules before your code runs. If you try to create a data race, your code won't compile. This means memory safety bugs and race conditions literally cannot exist in compiled Rust code. For observability platforms handling millions of concurrent metric updates, this guarantee is transformative.
Zero Cost Abstractions
High-level code that compiles to efficient machine code. This isn't a theoretical benefit. Benchmarks show Rust performing comparably to C and C++ while maintaining memory safety guarantees. You write expressive, maintainable code that runs at bare-metal speeds.
Fearless Concurrency
Observability platforms must handle massive concurrent workloads. Millions of metrics flowing in simultaneously. Multiple queries executing in parallel. Traditional languages make concurrency dangerous. Data races lurk in code that looks correct during review.
Rust's type system prevents data races at compile time through Send and Sync traits. If your code compiles, it's thread-safe. The compiler won't let you accidentally share mutable state between threads. Lock-free data structures become safe to implement and deploy.
Real-world impact: Rust's Actix Web framework is approximately 1.5 times faster than Go under identical conditions. Rust maintains consistent performance as concurrency increases, while garbage-collected languages show degradation at higher connection counts.
Theory matters less than production results. OpenObserve demonstrates what a Rust observability platform looks like at scale. The platform backend is built entirely in Rust, delivering a single binary that adapts its role based on configuration.
Core Components Working Together
The platform consists of five specialized components, each optimized for its specific task:
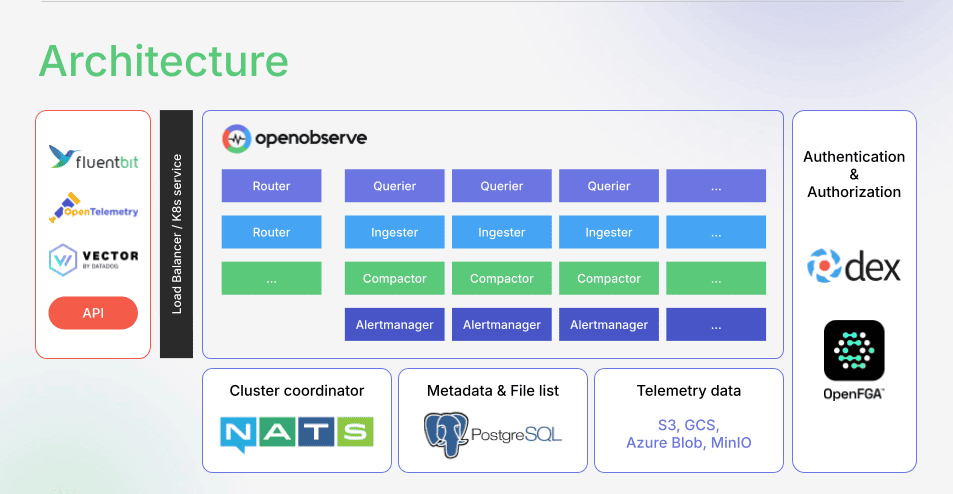
Ingester Receives data via HTTP and gRPC endpoints. Zero-copy parsing extracts fields without allocating new memory. Data flows through transformation pipelines, timestamp validation, and schema evolution before landing in a write-ahead log. The ingester handles up to 2.6 TB per day on a single node with standard hardware.
Querier Fully stateless nodes executing distributed queries. One node coordinates as a leader while others process file partitions as workers. The DataFusion query engine directly queries Parquet files stored in object storage. Internal benchmarks show 1 petabyte of data returning results in 2 seconds.
Compactor Merges small files into larger ones for query efficiency. Enforces retention policies. Maintains file list indices. Runs continuously in the background without impacting ingestion or query performance.
Alert Manager Executes alert queries on schedule. Manages report generation. Sends notifications when thresholds breach. All processing happens in memory with predictable latency.
Router Lightweight proxy dispatching requests between components. Serves the web interface. Handles authentication. Minimal overhead due to Rust's efficient networking stack.
Why This Architecture Works
Every component is stateless. You can scale horizontally by adding nodes. No complex data sharding. No coordinator bottlenecks. Storage lives in object storage (S3, MinIO, GCS, Azure Blob). This separation of compute and storage enables petabyte-scale operations without architectural complexity.
The single binary approach is only possible with Rust. Compiled binaries are small and fast to start. Deployment becomes straightforward. No JVM to tune. No runtime dependencies to manage. One binary, multiple roles, configured through environment variables.
You can learn more about the architecture at OpenObserve Architecture Documentation.
Numbers on slides mean nothing. Production performance under real workloads tells the truth.
Query Performance at Scale
Querying 1 petabyte of data in 2 seconds isn't a synthetic benchmark. It's the result of Rust's zero-cost abstractions combined with DataFusion's columnar query engine. The platform directly queries Parquet files without moving data into intermediate storage. Memory-mapped file access and SIMD operations happen naturally when your language doesn't add overhead.
Resource Utilization
On an M2 MacBook Pro, the platform ingests at approximately 31 MB per second. That's a laptop. Production servers with optimized storage handle significantly higher throughput. The lack of garbage collection means memory usage is predictable and consistent. No surprise spikes. No tuning required.
Compression ratios of 40x reduce storage costs by 140x compared to index-heavy solutions. Columnar Parquet storage and Rust's efficient memory layout make this possible without sacrificing query speed.
Cost Efficiency
Lower resource consumption translates directly to infrastructure savings. Estimates range from 60% to 90% reduction in observability costs compared to legacy solutions. These savings come from three sources:
Reliability Metrics That Matter
Zero memory leaks in production deployments running 6+ months. This isn't luck. It's the ownership model working as designed. Predictable performance during traffic spikes. No crashes. No data corruption. The compile-time guarantees that Rust enforces translate to runtime stability.
Concurrent metric ingestion handles millions of updates per second. Lock-free data structures maintain performance without contention. When incidents occur, your observability platform remains stable.
Rust isn't perfect. Choosing it for your observability platform comes with real costs.
Learning Curve
The ownership and borrowing model takes time to internalize. Developers comfortable with garbage-collected languages will fight the borrow checker initially. Code that seems obviously correct gets rejected by the compiler. This friction is intentional. The compiler catches bugs that would surface as production incidents.
Time investment: expect 3 to 6 months for developers to become proficient. The upside is that once code compiles, it typically works correctly. Less time debugging production issues means more time building features.
Compile Times
Rust compilation is slower than Go or interpreted languages. During development, this adds friction. Teams mitigate this through incremental compilation and splitting code into smaller crates. In production, compilation happens once during deployment, making this less impactful.
Smaller Ecosystem
Compared to Java or Go, Rust's ecosystem is younger. Finding libraries for specific tasks sometimes requires building them yourself. For observability platforms, this matters less. The core libraries (Tokio for async runtime, DataFusion for query processing, Arrow for columnar data) are mature and production-ready.
Why The Trade-offs Are Worth It
Compile-time error catching prevents an entire class of production incidents. The bugs that Rust prevents are exactly the bugs that cause critical outages. Buffer overflows, use-after-free errors, data races. These don't happen in Rust code that compiles.
Performance gains and lower resource consumption translate to real cost savings. Infrastructure costs are recurring. The upfront investment in learning Rust pays dividends through reduced operational costs.
Most importantly, reliability during incidents is non-negotiable. Your observability platform must stay up when everything else is failing. Rust's compile-time guarantees make this reliability achievable.
The industry is shifting. Multiple observability platforms are choosing Rust as their foundation. This isn't coincidence. It's recognition that the old trade-offs no longer work.
Memory safety vulnerabilities are declining in 2025 according to the FIRST Vulnerability Forecast, even as overall CVE numbers reach record highs of 41,000 to 50,000 new vulnerabilities. The adoption of memory-safe languages is driving this improvement. Government agencies and industry standards are recommending memory-safe languages for critical infrastructure.
OpenTelemetry standardization means observability data formats are becoming consistent across tools. The differentiation now comes from how efficiently you can ingest, store, and query that data. Rust provides the performance foundation needed to compete on these metrics.
Performance and cost efficiency are no longer nice-to-haves. With observability data volumes growing exponentially, infrastructure costs spiral quickly. Teams are evaluating tools based on their resource efficiency. Rust-based platforms offer a clear advantage here.
The future of observability isn't about adding more features. It's about building tools reliable enough to depend on during your worst incidents. Tools efficient enough to scale without breaking your budget. Tools built on foundations that eliminate entire classes of bugs.
Observability reliability is non-negotiable. When your systems are down, your monitoring tools must stay up. When traffic spikes, your metrics can't have gaps. When incidents cascade, your telemetry data must remain accurate.
Rust delivers on these requirements through compile-time guarantees that traditional languages can't match. Memory safety without garbage collection. Fearless concurrency without data races. Bare-metal performance without manual memory management.
OpenObserve demonstrates what's possible when you build observability platforms on this foundation. Single binary deployment. Petabyte-scale queries. Predictable resource usage. Production stability measured in months without issues.
The choice of programming language matters more than most architectural decisions. It determines what kinds of bugs are possible. It constrains your performance envelope. It impacts your operational costs.
For observability platforms, Rust isn't just a good choice. It's increasingly the only choice that makes sense.
Experience the next generation of observability. Sign up for a free cloud trial and see the difference Rust makes in production.
Manas is a passionate Dev and Cloud Advocate with a strong focus on cloud-native technologies, including observability, cloud, kubernetes, and opensource. building bridges between tech and community.