SLO-Based Alerting in OpenObserve

Simran Kumari
August 20, 2025
11 min read
Don’t forget to share!
Try OpenObserve Cloud today for more efficient and performant observability.

For SREs and Developers, What You’ll Learn:
Monitoring tools often throw hundreds of alerts like high CPU, slow responses, disk usage. But most of these don’t answer the real question: “Is the user experience impacted?”
That’s what Service Level Objectives (SLOs) are for.
SLOs let you focus on reliability goals tied to real user expectations, not just infrastructure signals. Instead of reacting to everything that could go wrong, you set targets for what must go right, based on your business and real user expectations.
A service is anything your users rely on, like your website, login system, billing API, or background jobs. Each one is expected to function reliably.
To measure how reliably a service performs, we use Service Level Indicators (SLIs). These are metrics like:
A SLO is a target you set for an SLI over a time window. For example, "99.9% of requests should succeed over 7 days."
SLOs are reliability targets that guide operational focus. Instead of chasing infrastructure metrics like CPU or memory usage, SLOs help you focus on what matters: whether the service is available, responsive, and not throwing errors.
For example, your database service might show high CPU usage. That alone doesn’t matter to the service owner unless users are seeing slow queries or failed transactions. SLOs let you ignore noisy alerts and focus only when actual user impact is at risk.
Understanding Error Budgets
Every SLO implies an error budget i.e. the small, acceptable margin for failure. Example: If your SLO is 99.9%, you have an error budget of 0.1% failures in a given time window.
This error budget isn’t just for alerts. It’s a decision-making tool:
You alert not because the SLO is breached, but when you’re burning through the error budget too fast.
Note: A SLO is not an alert by itself,it’s a long-term reliability target. Alerts are derived from how fast or how often you're deviating from that SLO.
Let’s see how SLOs play out with a real-world example.
Before we dive into the demo, make sure you have the following set up:
The scenario: Your users are complaining about slow login experiences. Let's build a complete SLO monitoring system in OpenObserve that tracks, alerts, and helps debug latency issues.
We'll walk through the entire workflow:
Define SLO → Build Dashboard → Create Alerts → Debug Issues when at risk.
Where to Define SLOs in OpenObserve?
OpenObserve doesn’t have a built-in SLO object. You define an SLO by writing a SQL query that evaluates whether your service is meeting the target. You can then:
In short, the SLO lives in the query and the alert logic you create , giving you full control over how it's defined and enforced.
Business Context: Users expect login to feel responsive. Research shows anything above 500ms feels sluggish.
Sample trace data (already flowing into OpenObserve):
Note: OpenTelemetry collects traces in a nested JSON structure (e.g., resource.attributes, scopeSpans.spans). OpenObserve automatically flattens these fields during ingestion for easier querying. The flattening depth is controlled by the environment variable ZO_FLATTEN_LEVEL (default: 3). That’s why in the example below you see simple keys like service_name instead of deeply nested.
{
"trace_id": "abc123abc123abc123abc123abc123ab",
"span_id": "def456def456def4",
"operation_name": "POST /login",
"start_time": 1754664691403452700,
"end_time": 1754664691409971500,
"duration": 518600,
"http_method": "POST",
"http_status_code": 200,
"http_url": "http://authservice.local/login",
"service_name": "auth-service",
"span_kind": 3,
"span_status":"UNSET",
"status_code":0,
"status_message":"",
}
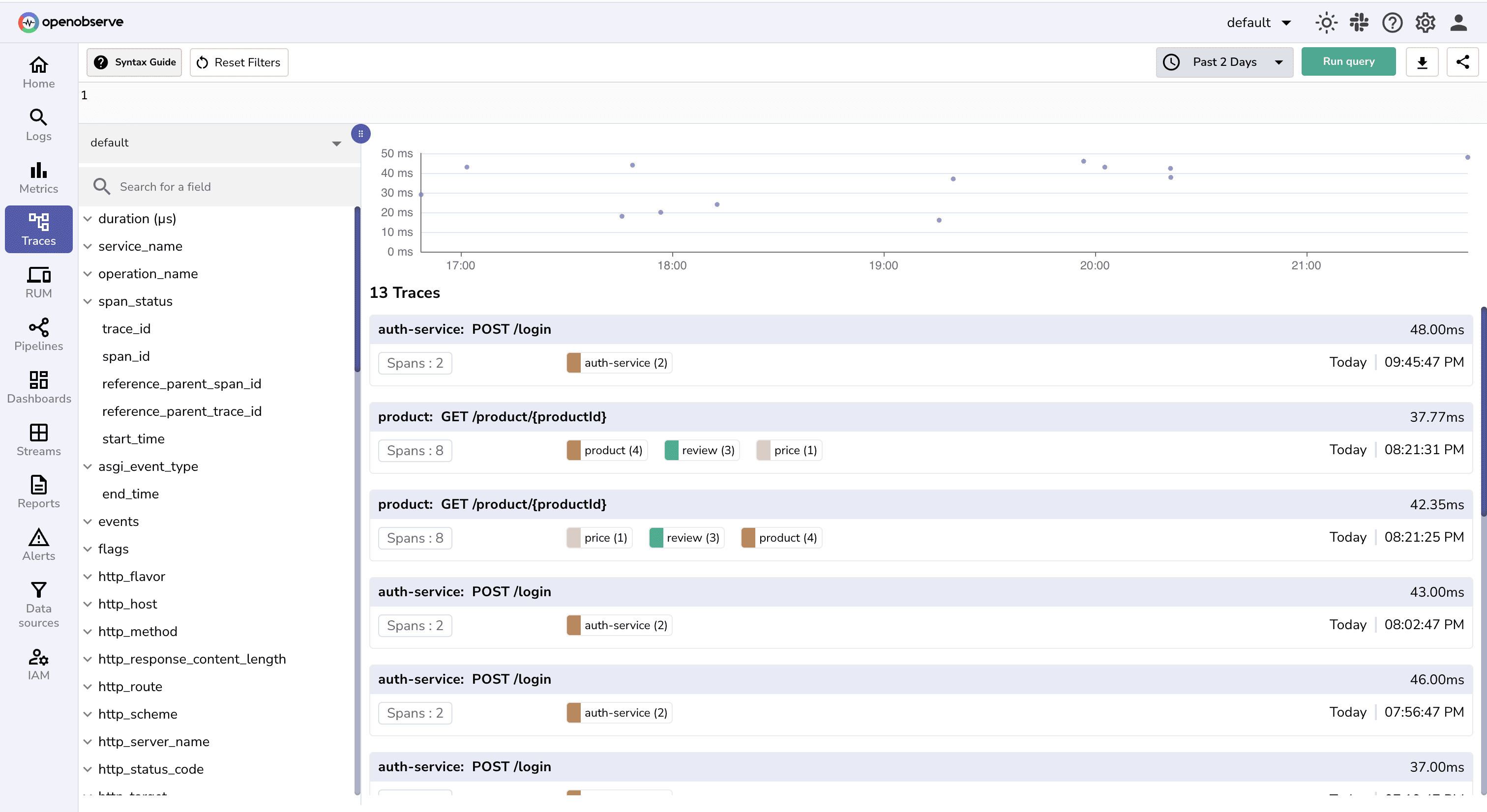
SLO: "95th percentile login response time should stay under 500ms over any 7-day rolling window"
(Note: This threshold is just an example. SLOs vary based on business impact, user expectations, and service risk tolerance.)
Why P95? Averages hide problems. P95 tells us 95% of users get a response faster than this threshold, catching tail latency issues that affect real users.
You need to verify if your service is meeting its defined performance targets.
In the OpenObserve UI , go to Stream section and select your traces stream and click on Explore icon.
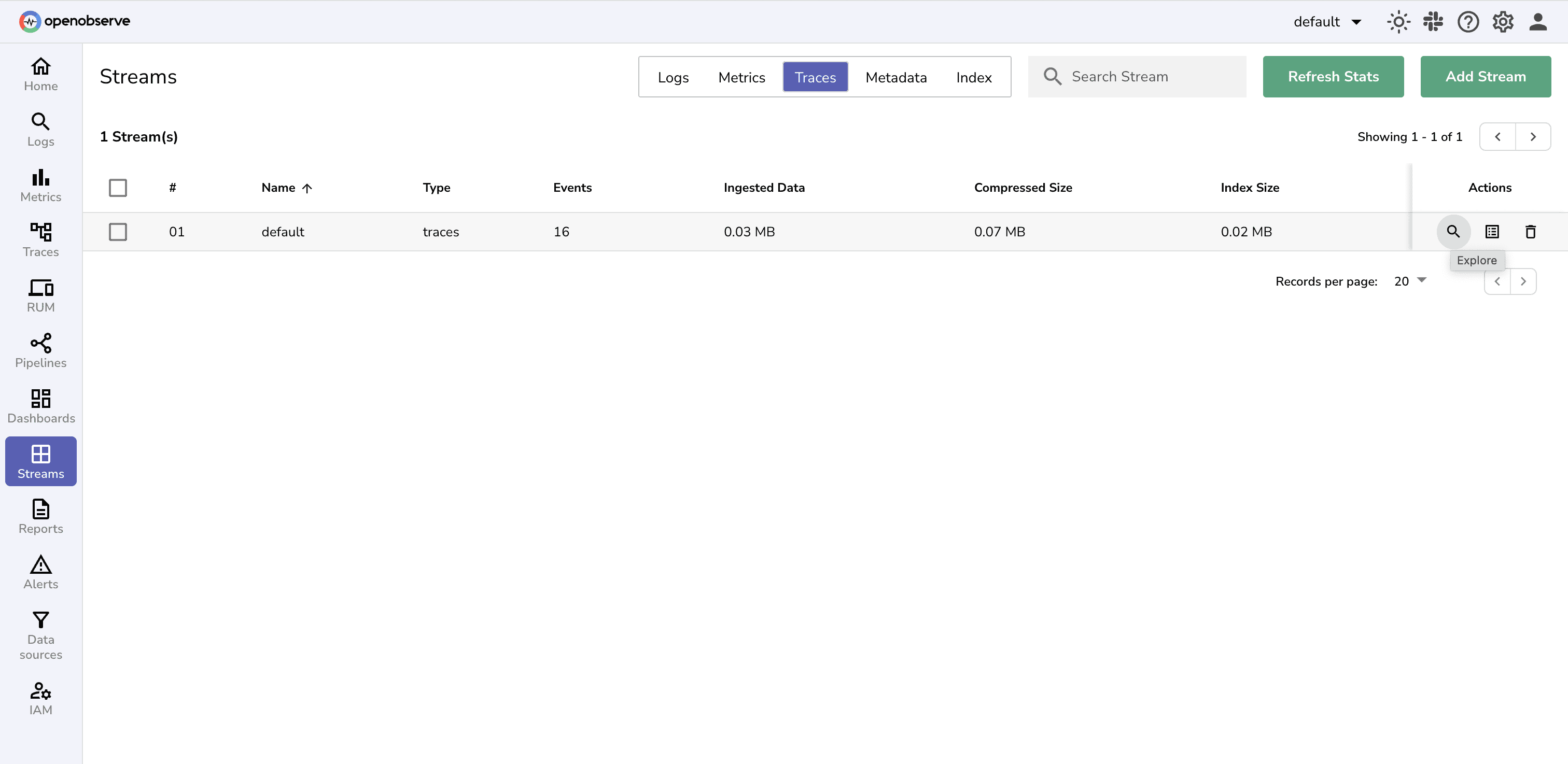
Use the Include term icon to filter for respective service, operation name and status code.
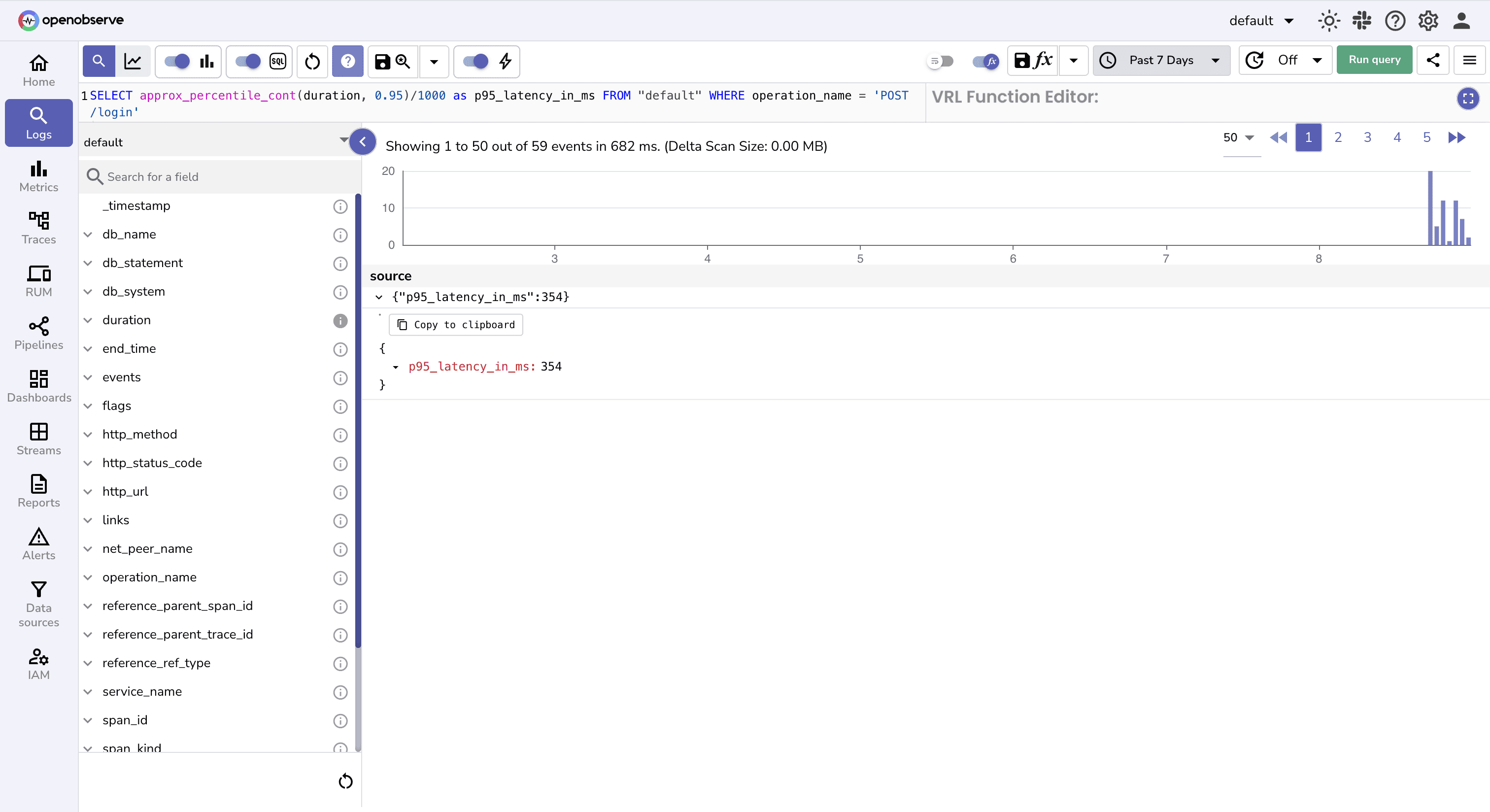
After filtering use SQL function to calculate 95th percentile for response time and check if the target is met.
Note:
status_code < 400 because we want to consider only successful or redirected requests (i.e., not client or server errors) when evaluating latency SLOs.duration field is in microseconds in this case, so we divide by 1000 to convert the result to milliseconds for comparison with the 500ms SLO target.So, p95_latency is <500 ms, so our SLO target is not at risk. But do we need to rewrite the query every time to check compliance?
Well , no. Instead, we can create dashboards.
Creating a dashboard helps visualize and observe SLO compliance trends over time without repeating manual checks.
Navigate to OpenObserve → Dashboard and create a new dashboard.
Next, add Panels to your dashboard
## Login Latency SLO
- **Target**: P95 < 500ms over 7 day rolling window
- **Error Budget**: 5% of requests can exceed 500ms
- **Business Impact**: Latency >500ms correlates with 12% higher bounce rate
- **Owner**: Backend Team
- **Escalation**: #backend-oncall
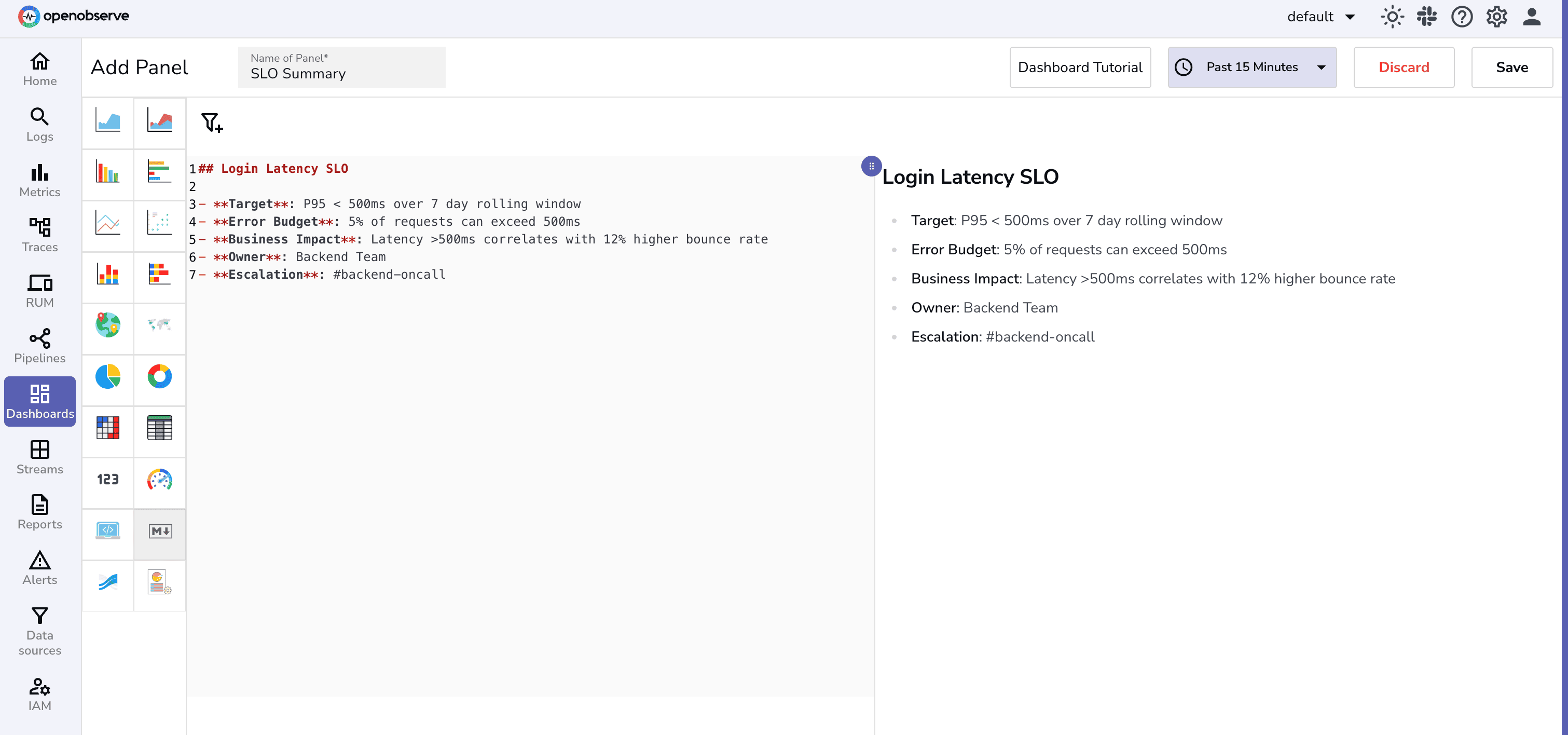
This provides a clear, at-a-glance summary of the SLO, helping teams align on objectives, impact, and ownership.
Create a line chart to capture your latency trends over time.
timestamp in x-axis and P95 of response time / duration on y-axisoperation_name and status_code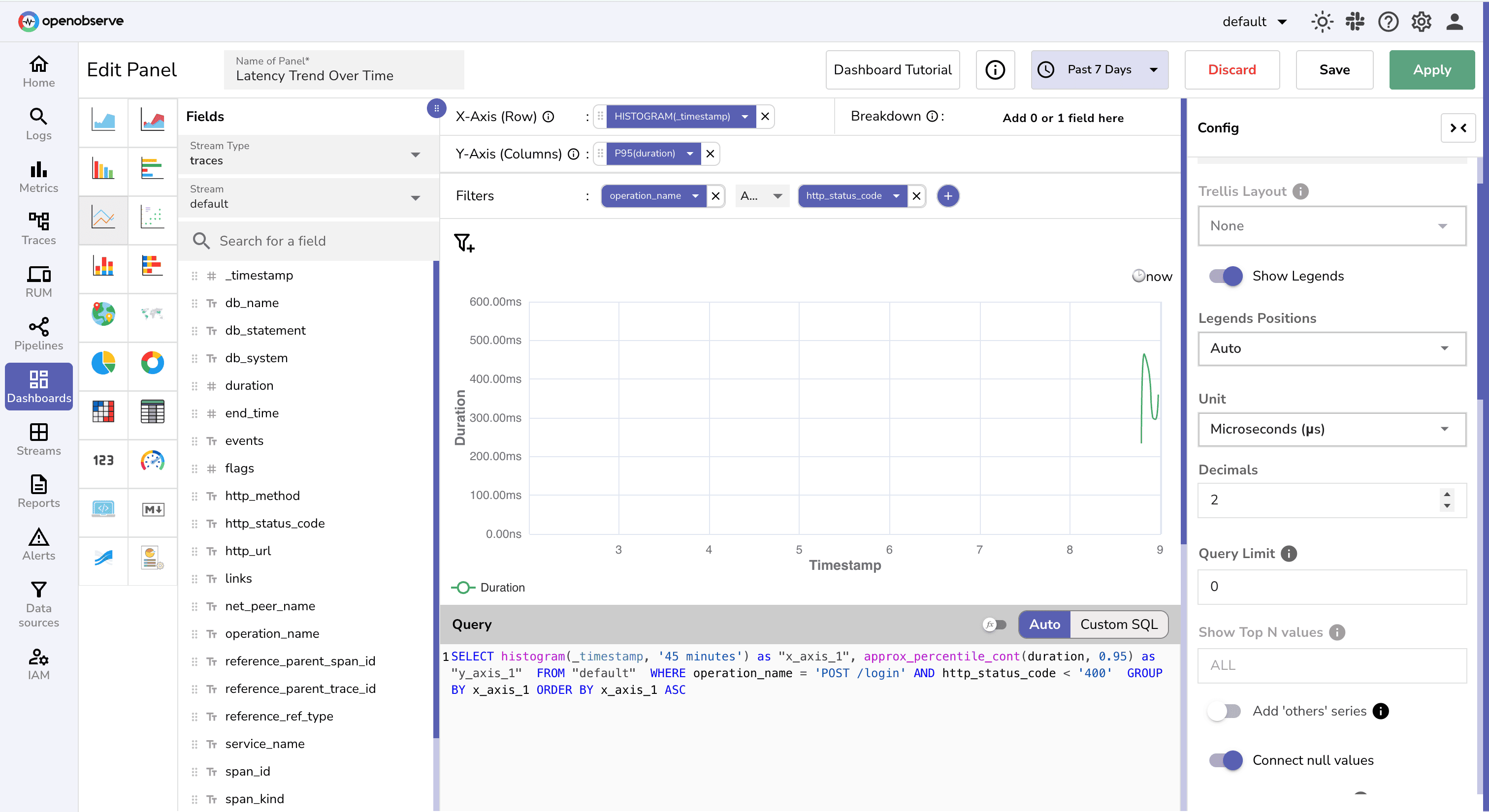
Create a gauge chart which shows real-time compliance with the latency SLO to quickly identify if the service is meeting performance targets.
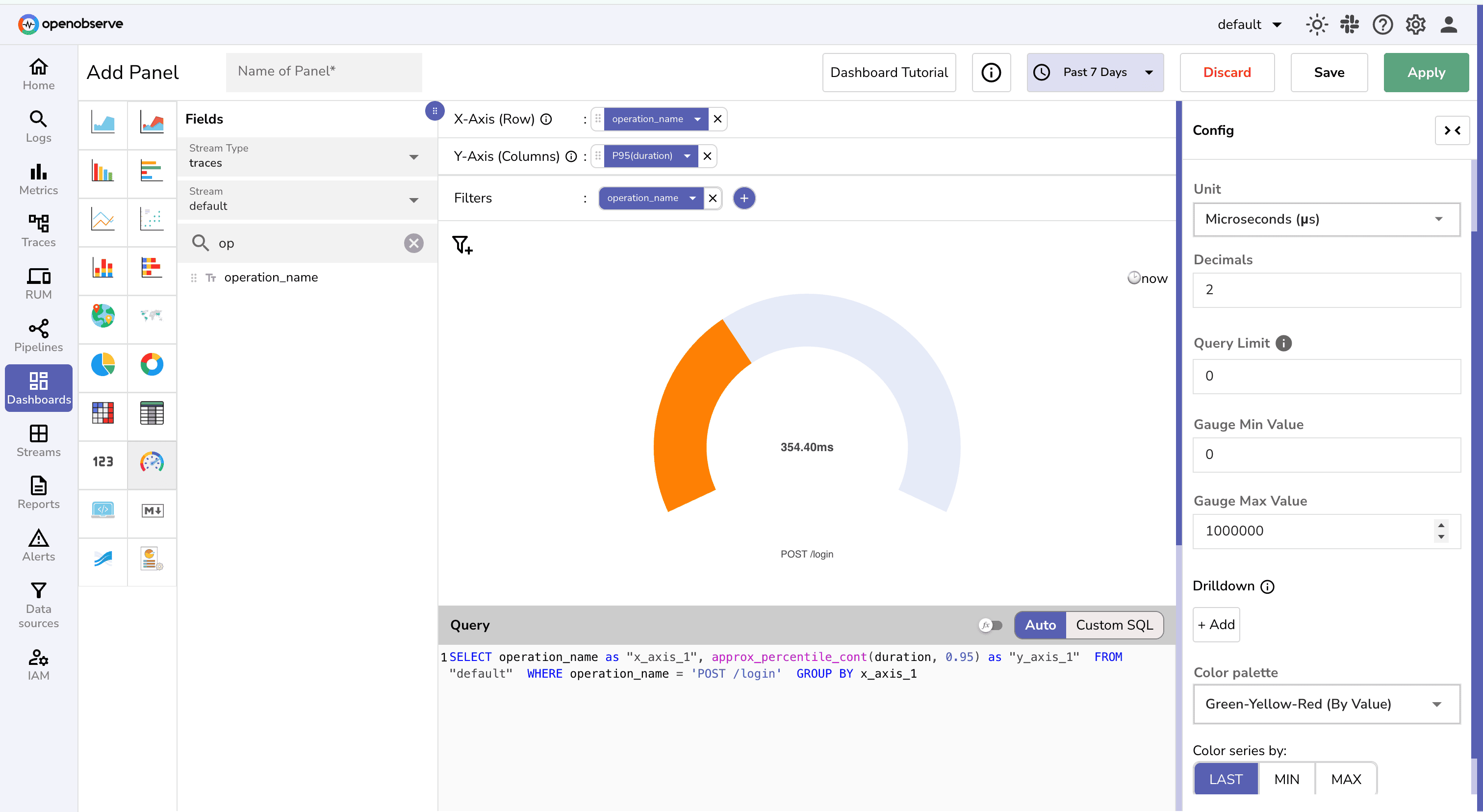
Your final dashboard may look something like this:
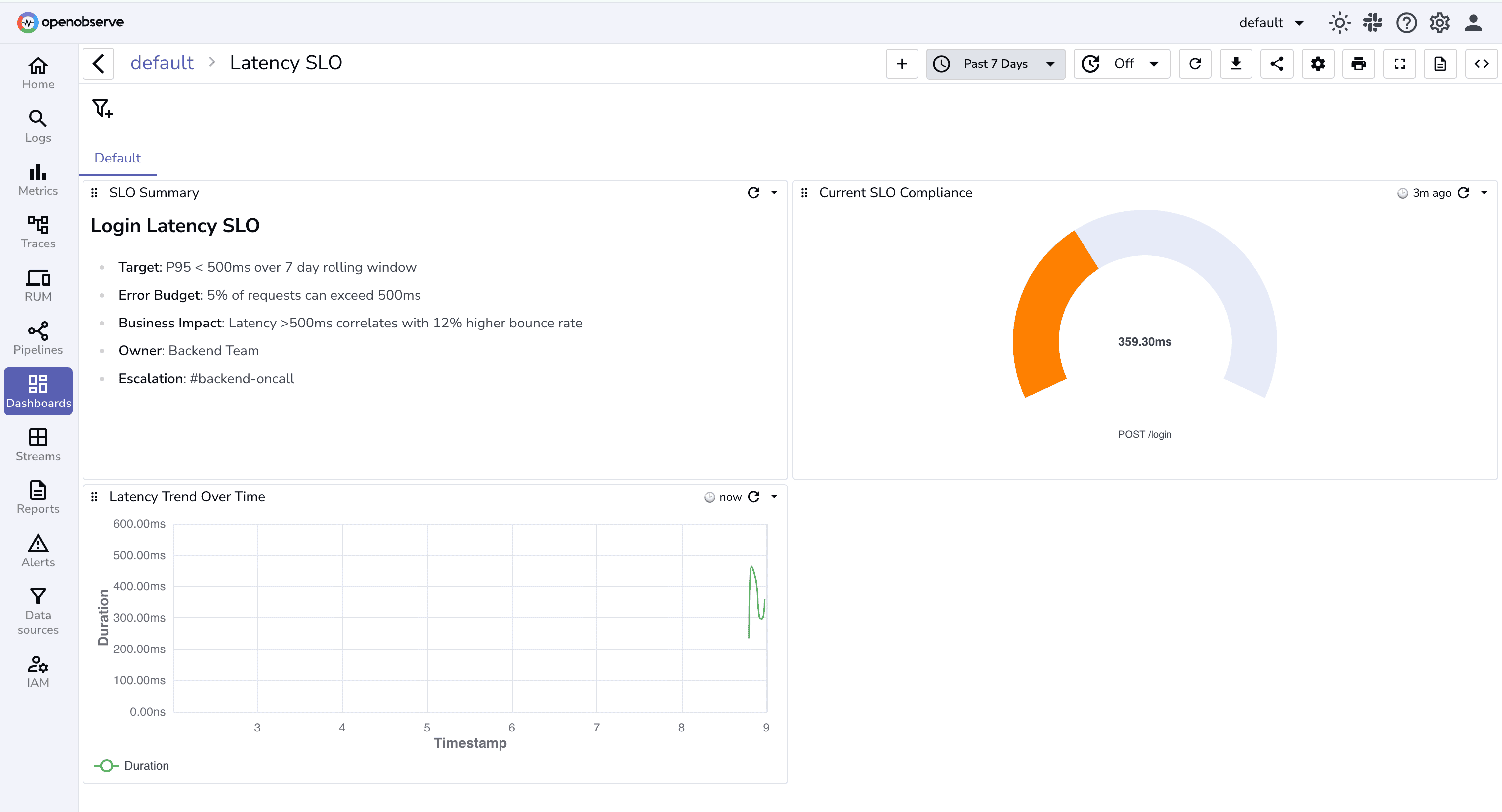
You can add more panels and charts based on your needs.
Use Dashboard settings to update the default duration as 7-days to avoid manual changes every-time you visit the dashboard:
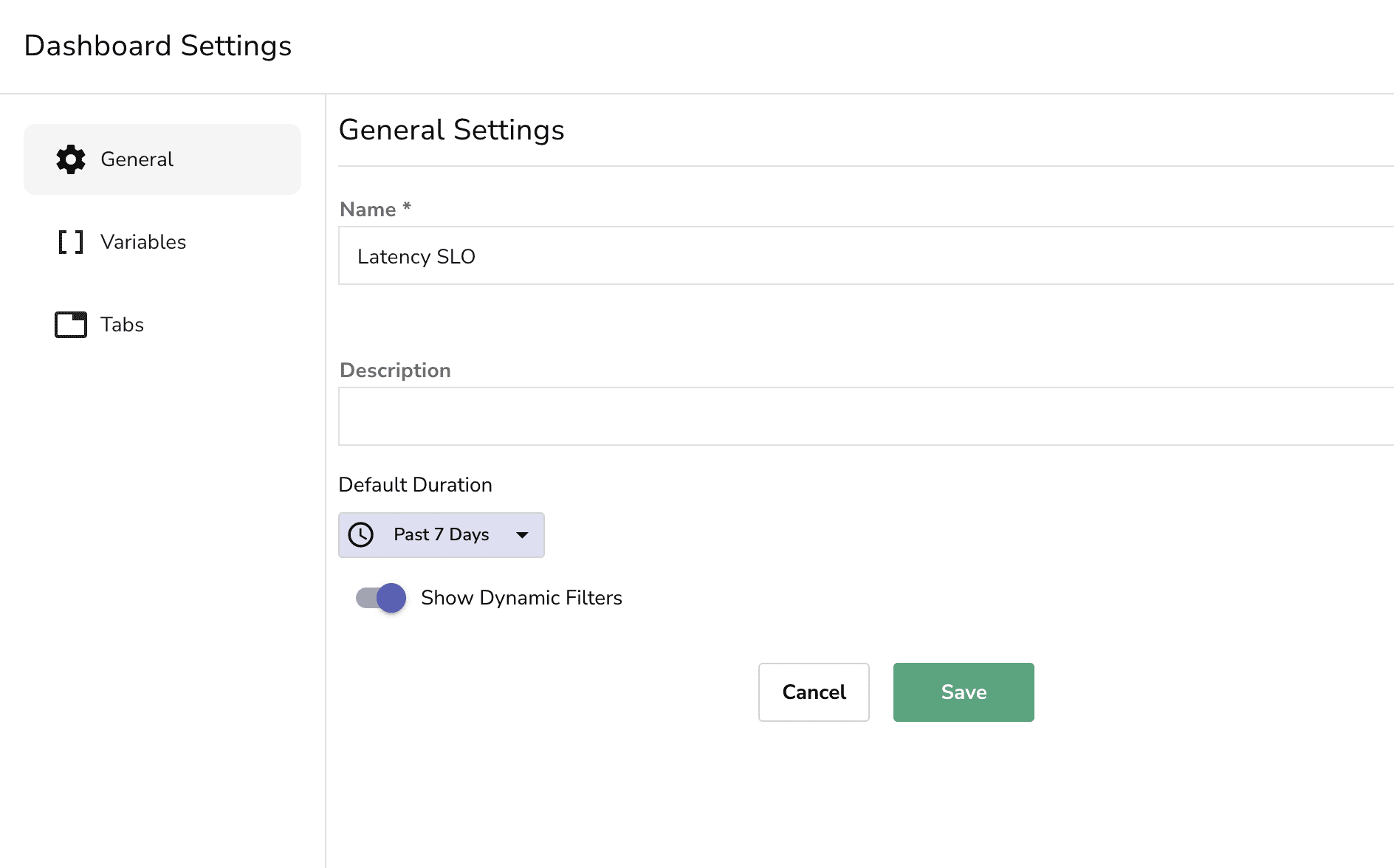
Pro tip: Set dashboard to auto-refresh every 5 minutes so it stays current. So far, the dashboard tells you what's happening, but someone still has to look at it. That doesn't scale.
To truly defend your SLO, you need to:
Alerts turn SLO breaches into immediate signals , so your team can act before SLAs (Service Level Agreements) or user experience are impacted.
Setting SLO Breach Alert
Navigate to OpenObserve → Alerts → Add Alert
Fill in Alert-Setup details:
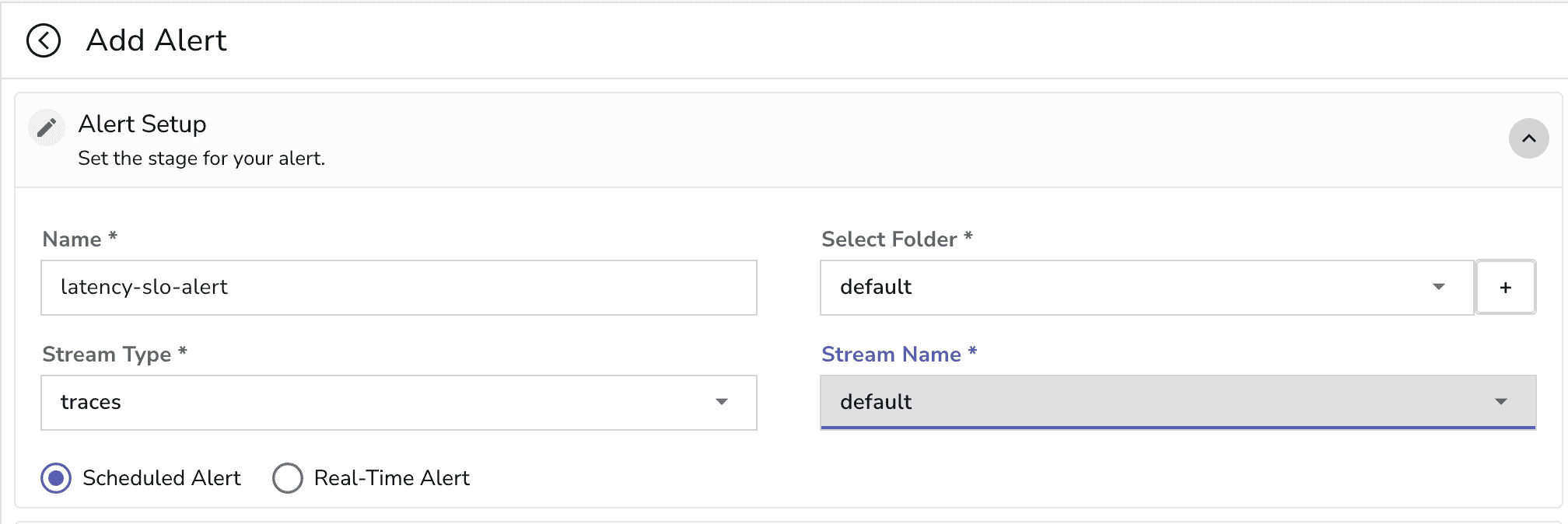
Configure alert Settings. Select the corresponding destination where you want to receive the alert notification.
 The Alerts in OpenObserve documentation provides details around Alerts parameters. Or you can click on the
The Alerts in OpenObserve documentation provides details around Alerts parameters. Or you can click on the i icon for summary details.
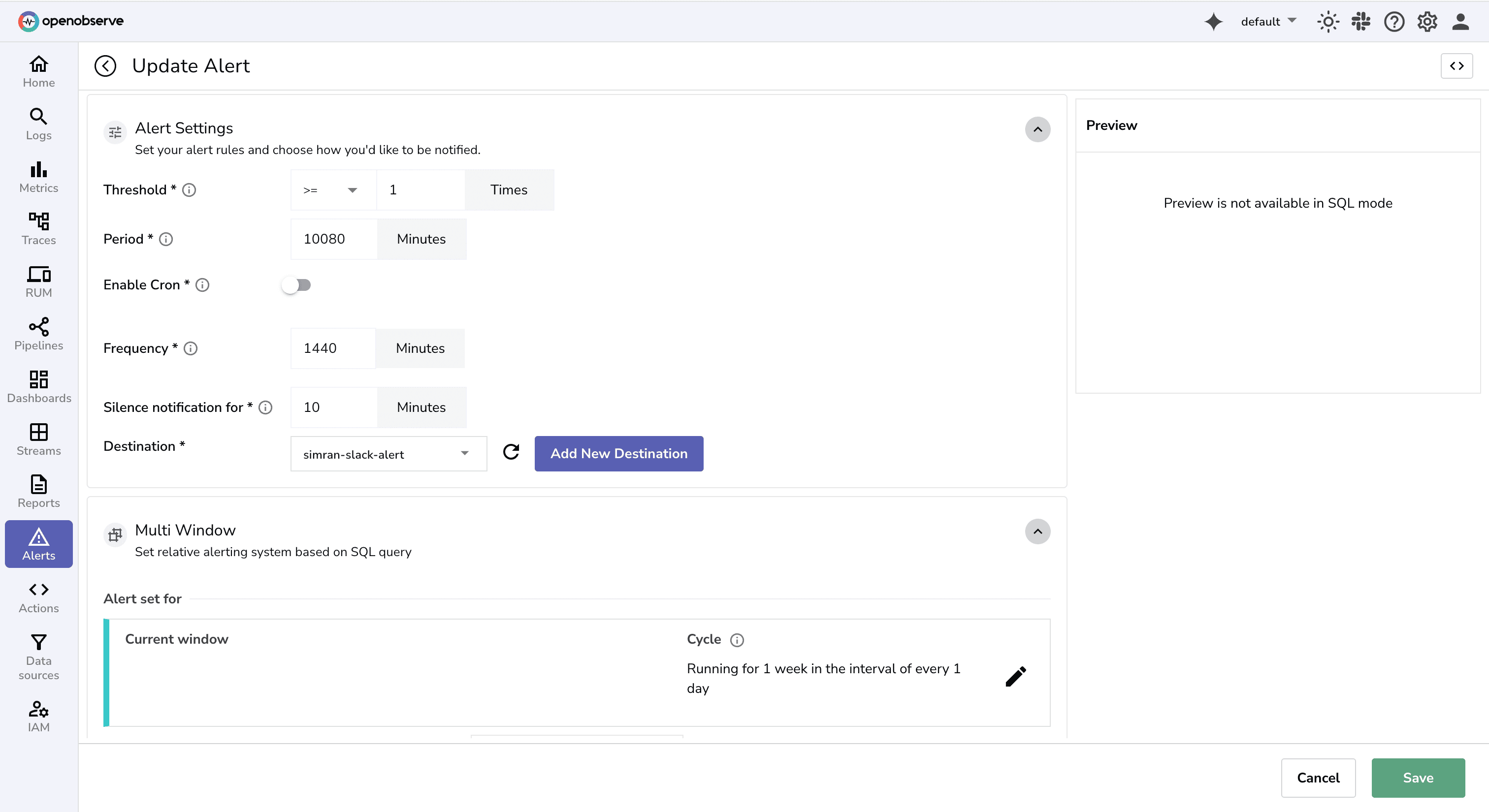
Next, we need to set conditions for alert.
View Editor to open the SQL query editor for defining alert conditions
SELECT
service_name,
APPROX_PERCENTILE_CONT(response_time_ms, 0.95) AS p95_latency_ms
FROM <STREAM_NAME>
WHERE
service_name = 'auth-service'
AND operation_name= 'POST /login'
AND status_code < 400
GROUP BY service
This query checks if the 95th percentile latency for the /login endpoint in the auth-service is exceeding the SLO threshold of 500 ms. (In case the duration is micro seconds don’t forget the conversion)
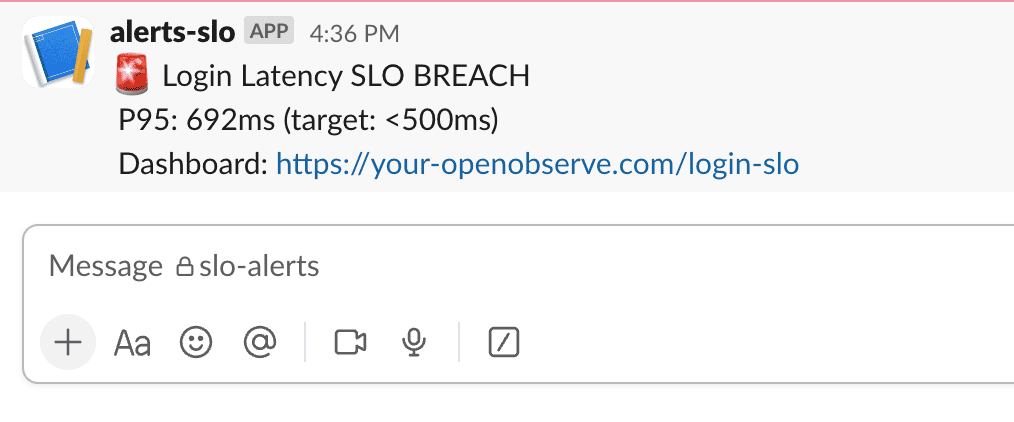
HAVING p95_latency_ms > 500: triggers logic only when the SLO is violated ,making it perfect for alerting.You can set the Message Template as :
🚨 Login Latency SLO BREACH
P95: {p95_latency_ms}ms (target: <500ms)
Dashboard: https://your-openobserve.com/login-slo
Note: While threshold-based alerts (like p95 latency > 500ms) work well, teams aiming for more resilient and user-centric alerting often use burn rate alerts. Burn rate is the speed at which you're consuming your SLO's error budget and alerts can be tuned for fast vs slow incidents.
For a deeper understanding, see Google's Site Reliability Workbook (Chapter 6: Alerting on SLOs)
Once an alert fires, you need to figure out why.
Focus on these four angles:
Pro tip: Use drilldown to link to dashboards/logs for quick triage when an alert hits.
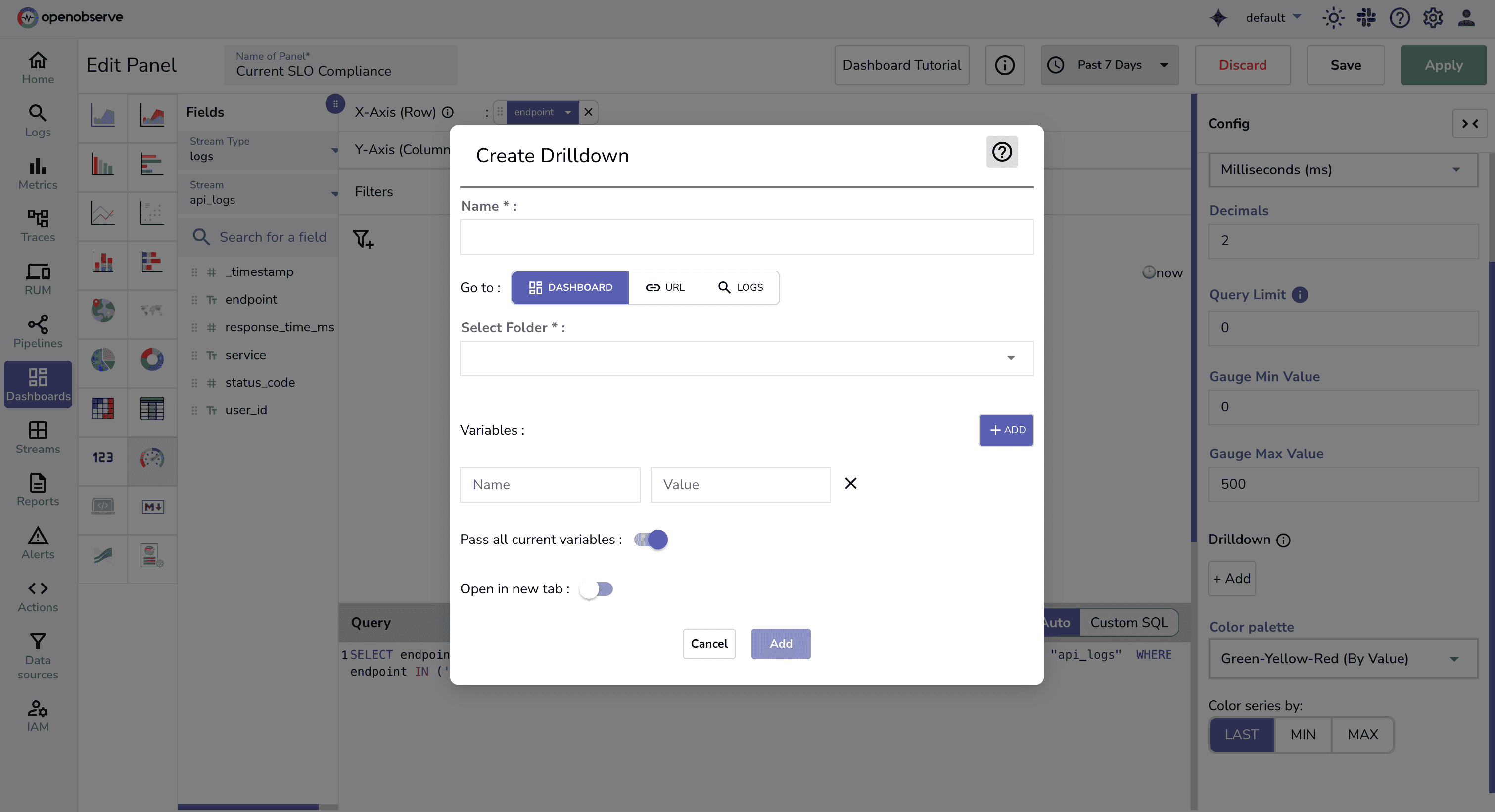
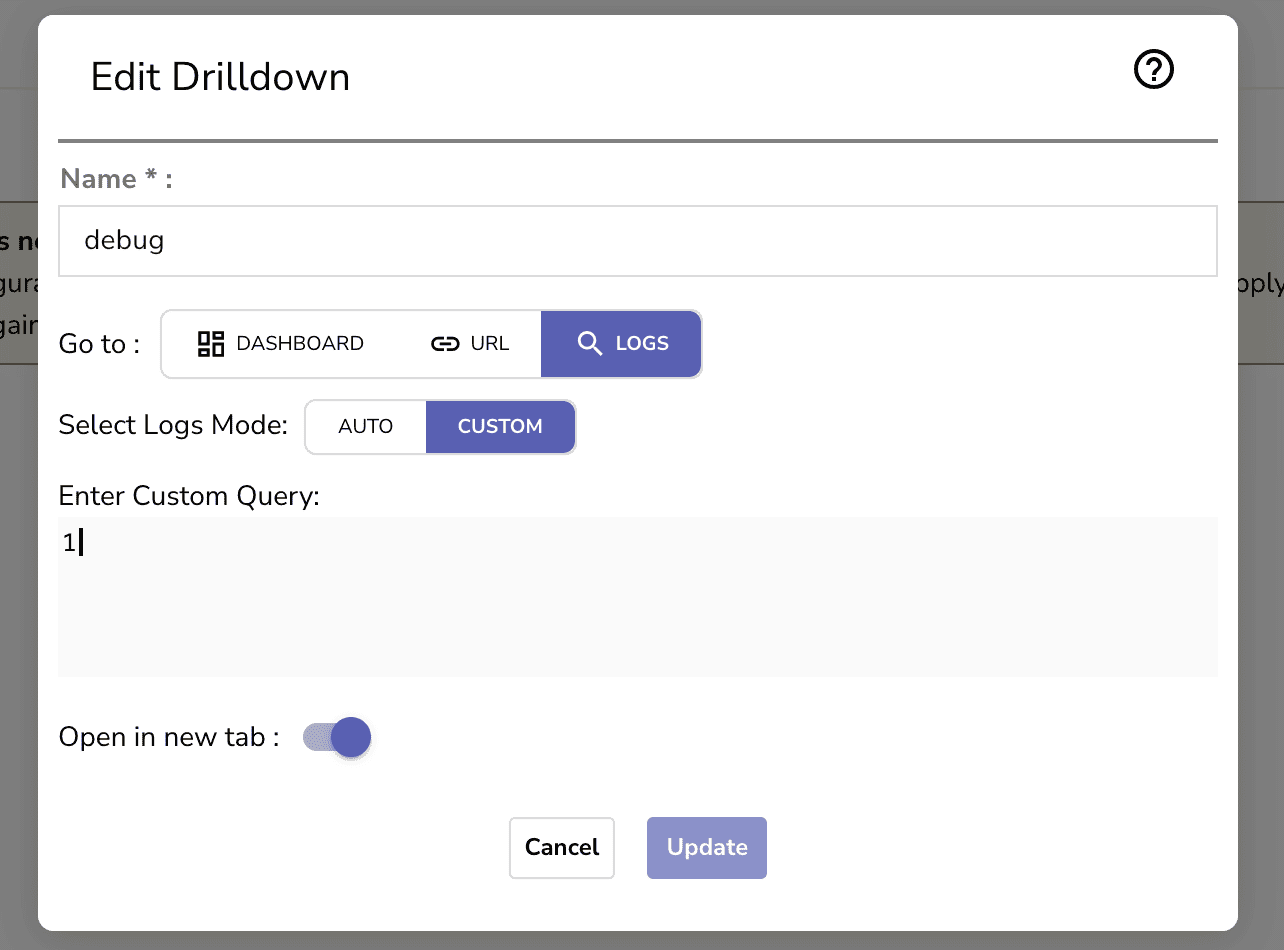
SLOs aren’t just theory, they’re your best defense against alert fatigue.
By focusing on what users actually care about, and combining that with OpenObserve’s SQL-powered alerting, you can:
OpenObserve gives you the flexibility to express these goals in code and turn them into actionable alerts.
Get Started with OpenObserve Today!
Sign up for a 14 day cloud trial. Check out our GitHub repository for self-hosting and contribution opportunities.
Passionate about observability, AI systems, and cloud-native tools. All in on DevOps and improving the developer experience.












