Applicable to open source & enterprise version
Architecture and deployment modes
OpenObserve can be run in single node or in HA mode in a cluster.
Single Node
Please refer to quickstart for single node deployments.
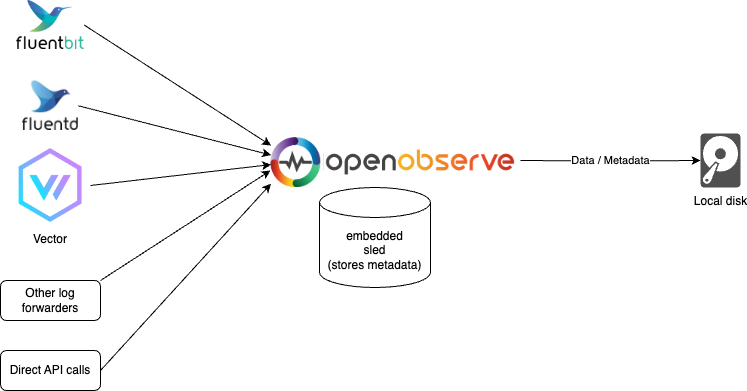
Sled and Local disk
Use this mode for light usage and testing or if HA is not a requirement for you. (You could still ingest and search over 2 TB on a single machine per day. On a mac M2 in our tests, you can ingest at ~31 MB/Second or 1.8 GB/Min or 2.6 TB/Day with default configuration). This is the default mode for running OpenObserve. Check Quickstart to find various ways to get this setup done.
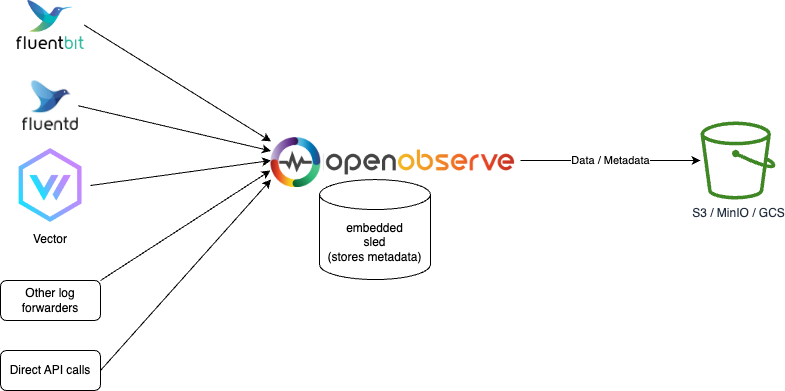
Sled and Object storage
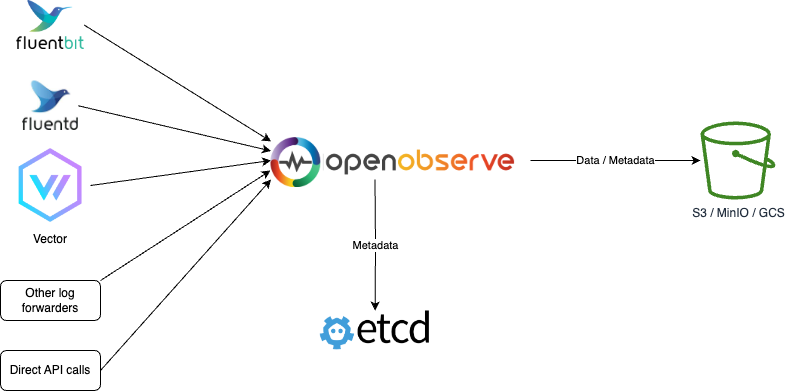
etcd and object storage
High Availability (HA) mode
Local disk storage is not supported in HA mode. Please refer to HA Deployment for cluster mode deployment.
etcd and object storage
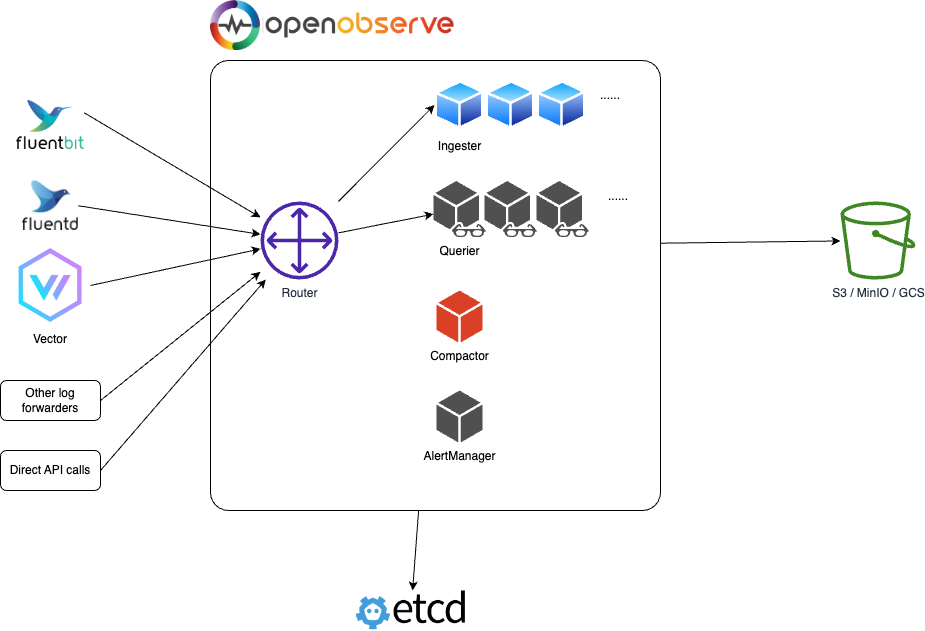
Router, Querier and Ingester nodes can be horizontally scaled to accomodate for higher traffic.
Etcd is used to store metadata like organization, users, functions, alert rules and cluster node information.
Object Storage (e.g. s3, minio, gcs, etc...) stores all the data of parquet files and file list index.
Components
Ingester
Ingester is used to receive ingest request and convert data into parquet format and store it in object storage. They store data temporarily in WAL before transferring it to object storage.
The data ingestion flow is:
- receive data from http API request.
- parse line by line.
- check if there are some functions (ingest time functions) used to transform data. will call each ingest function by the function order. like
func(row)and will expect to return a row. if empty row is returned then it will drop the record. - check timestamp field, convert timestamp, and set current timestamp if there is no time field.
- check stream schema to identify if schema needs to be evolved.
- write to WAL file by timestamp in hourly buckets.
- when max file size or the time is reached, it will convert WAL file to parquet file and move to storage(local or s3). e.g max_file_size=10MB, max_time=10 minutes, then if the file size reaches 10 MB or elapsed time is 10 minutes whichever occurs first, the file will be moved to object storage.
- Ingester also does the work of evaluating any real time alerts that have been defined.
Querier
Querier is used to query data. Queriers nodes are fully stateless.
The data query flow is:
- receive search request from http API. The node that receives the query request is called
LEADER querier for the query. Other queriers are calledWORKER queriers for that query. LEADERparses and verifies SQL.LEADERfinds the data time range and get file list from file list index.LEADERfetch querier nodes from cluster metadata.LEADERpartitions list of files to be queried by each querier. e.g. If 100 files need to be queried and there are 5 nodes, then each querier gets to query 20 filesLEADERworks on 20 files,WORKERSwork on 20 files each.LEADERcalls gRPC service running on eachWORKERquerier to dispatch search query to the querier node. Inter querier communication happens using gRPC.LEADERcollects, merges and sends the result back to the user.
Tips:
- The querier will cache parquet files in memory by default. You can configure the amount of memory used by querier for caching through environment variable
ZO_MEMORY_CACHE_MAX_SIZE. Default caching is done through 50% of the memory available to the particular querier. - In distributed environment each querier node will just cache a part of the data.
- We also have an option to enable caching latest parquet files in memory. The ingester will send a notice to queriers to cache the files when ingester generates a new parquet file and sends it to object storage.
Compactor
Compactor will merge small files into a big file to make the search more efficient. Compactor also handles the data retention policy, full stream deletion and update of file list index.
Router
Router dispatches requests to ingester or querier. It also responds with the GUI in the browser. Router is a super simple proxy to send appropriate requests between ingester and querier.
AlertManager
AlertManager runs the scheduled alert queries and sends notification.