Top Observability Tools & Platforms in 2026: The Complete Guide

Simran Kumari
March 16, 2026
19 min read
Don’t forget to share!
Try OpenObserve Cloud today for more efficient and performant observability.

Observability is the ability to infer the internal state and health of a complex system by analyzing the data it produces, without needing to know in advance what questions you'd need to ask. The term originates from control theory, where a system is considered "observable" if its current state can be determined entirely from its external outputs.
In the context of software and infrastructure, observability means your team can answer questions like:
Unlike traditional monitoring, which tells you that something is wrong, observability tells you why it's wrong and helps you pinpoint the root cause across distributed, cloud-native systems.
As modern architectures grow more complex, microservices, serverless functions, Kubernetes clusters, multi-cloud deployments, traditional monitoring approaches can no longer keep up. Observability fills that gap.
Further reading: Observability vs Monitoring Explained, OpenObserve's vendor-neutral guide to understanding the difference and why modern teams make the switch.
Observability rests on three core data signals, collectively called the three pillars:
Metrics are numeric, time-series measurements that track the health and performance of systems, things like CPU usage, memory consumption, request rates, error rates, and latency. They're lightweight, easy to store, and great for alerting and dashboards. Examples: Prometheus metrics, StatsD counters, CloudWatch custom metrics.
Logs are immutable, timestamped records of discrete events. When something goes wrong, logs are usually the first place engineers look. They provide rich contextual detail, stack traces, user IDs, request payloads, that metrics simply can't capture. See: Top 10 Log Monitoring Tools and Best Log Management Tools in 2026.
Distributed traces track a single request as it travels through multiple services in a microservices architecture. A trace is made up of individual "spans," each representing a unit of work, a database call, an HTTP request, a function execution. Traces let you visualize the entire request lifecycle and identify exactly where latency or failures originate. Examples: Jaeger traces, Zipkin, OpenTelemetry traces.
Some modern platforms add a fourth pillar, profiles, which track CPU and memory usage at the code level to help optimize performance over time. OpenObserve, for instance, supports logs, metrics, traces, and frontend monitoring all in one unified platform.
This is one of the most commonly misunderstood distinctions in DevOps and SRE.
| Monitoring | Observability | |
|---|---|---|
| Focus | Known failure states | Unknown and unexpected states |
| Approach | Predefined alerts and dashboards | Exploratory, ad-hoc analysis |
| Data | Metrics (primarily) | Metrics + Logs + Traces |
| Question answered | "Is it broken?" | "Why is it broken?" |
| Best for | Static, predictable systems | Dynamic, distributed systems |
| Limitation | Only catches anticipated problems | Requires more data ingestion |
In practice, monitoring is a subset of observability. A mature observability strategy includes monitoring but extends well beyond it, enabling teams to ask novel questions about system behavior at any point in time.
These terms are often used interchangeably, but they mean different things:
An observability tool handles one specific part of the observability process. Grafana is a visualization tool. Prometheus is a metrics collection tool. Jaeger is a tracing tool. They're powerful, but they require integration work to cover the full observability stack.
An observability platform is a holistic, integrated solution that handles the complete pipeline: telemetry data collection, storage, processing, analysis, correlation, alerting, and visualization, all in one place. Platforms like OpenObserve, Datadog, and Dynatrace are designed to replace a patchwork of individual tools with a single unified experience.
For most modern engineering teams, especially those running distributed systems at scale, a platform approach reduces tool sprawl, simplifies operations, and makes cross-signal correlation far easier. See the full breakdown: Top 10 Observability Platforms in 2026.
When evaluating observability platforms, keep these criteria in mind:
Website: openobserve.ai | GitHub: openobserve/openobserve | Cloud: cloud.openobserve.ai
Type: Open-source / Cloud SaaS | Best for: Teams seeking cost-effective, full-stack observability without vendor lock-in
OpenObserve (also known as O2) is a fast-growing, cloud-native observability platform built in Rust, which speaks directly to its performance ambitions. Written to solve the real-world pain points of existing tools, complex setup, high storage costs, opaque pricing, OpenObserve has quickly become a compelling alternative to Datadog, Splunk, and Elasticsearch.
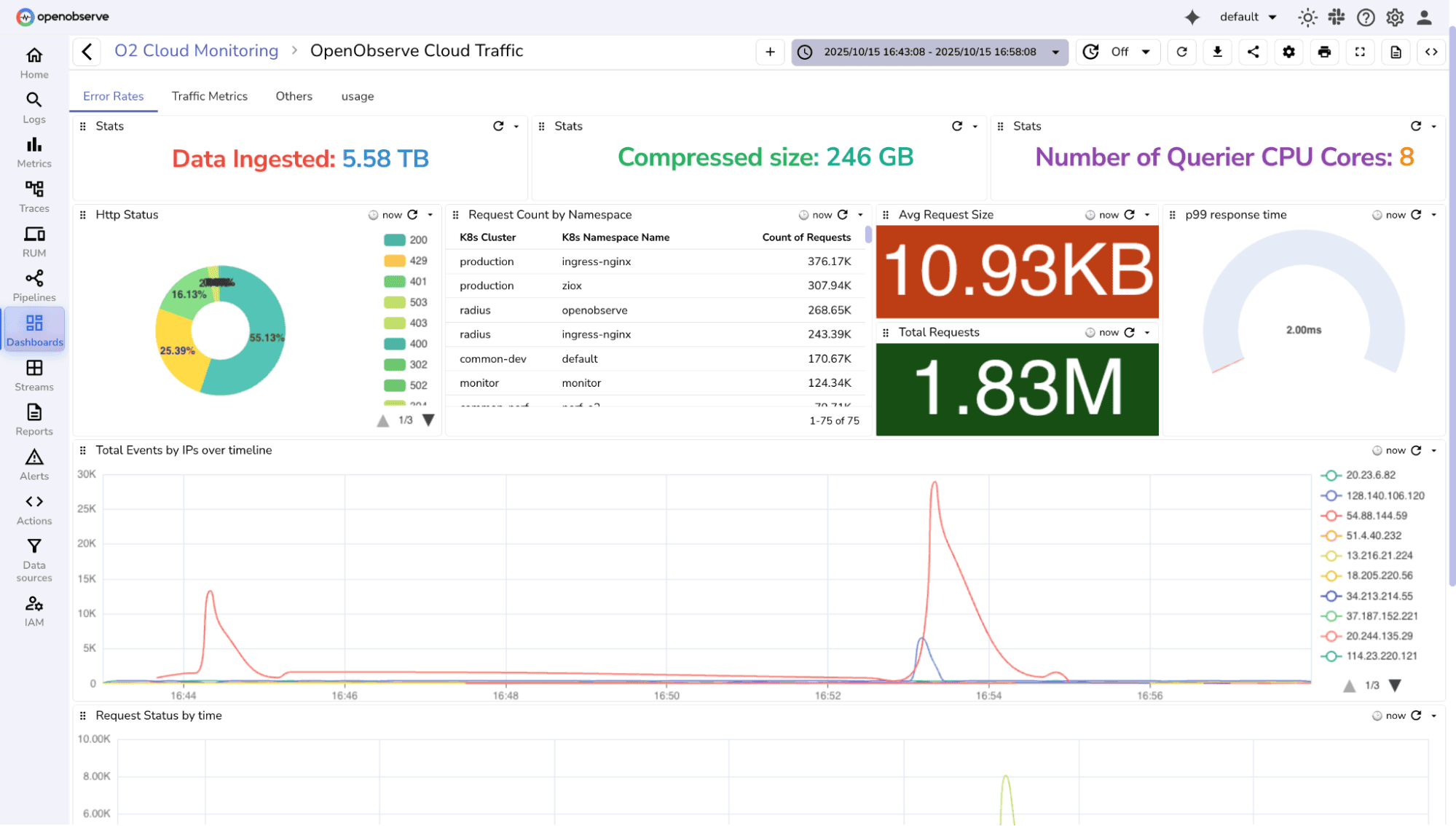
Key highlights:
OpenObserve's architecture uses stateless nodes, enabling rapid horizontal scaling and low RPO/RTO for disaster recovery. Enterprise features include SSO (OIDC, SAML, LDAP), advanced RBAC, federated search across multi-region clusters, and audit trails.
Think of it as Prometheus + Elasticsearch + Jaeger + Grafana, all in one, at a fraction of the cost.
Pricing: Free (self-hosted open source), Enterprise tier with free ingestion up to 200 GB/day, pricing available.
Website: datadoghq.com
Type: SaaS | Best for: Large enterprises with complex, multi-cloud environments
Datadog is the dominant force in the commercial observability market, commanding roughly 51.82% market share in data center management. It offers an exceptionally broad feature set, APM, infrastructure monitoring, log management, synthetic monitoring, real user monitoring (RUM), security monitoring, and AI observability, all under one roof.
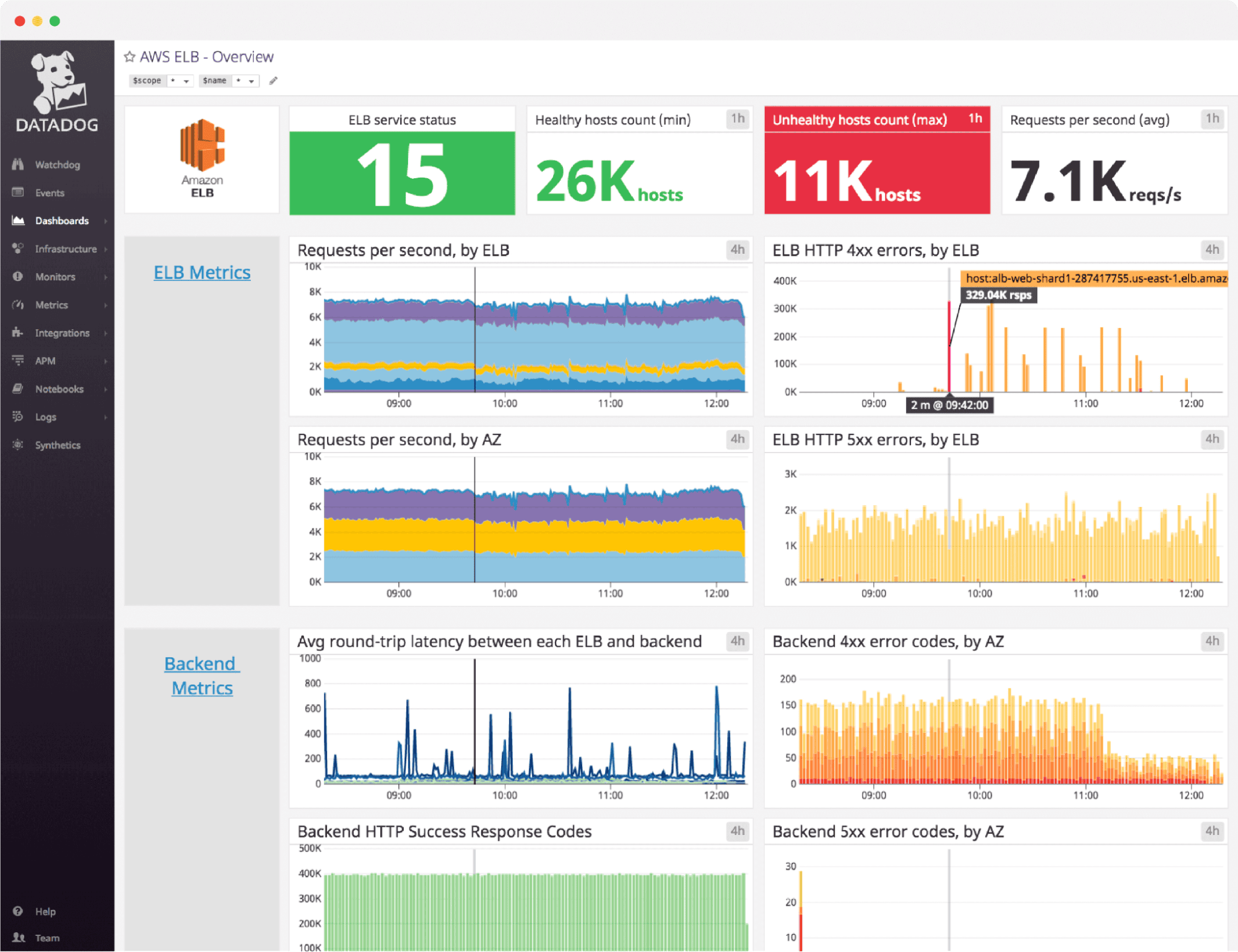
Strengths:
Considerations:
Pricing: $15–$23/host/month base; costs scale significantly with additional features and data volume.
Evaluating alternatives? See Best Datadog Alternatives in 2026 and Top Datadog Competitors on OpenObserve's blog.
Website: newrelic.com
Type: SaaS | Best for: Growing companies needing scalable, unified observability with a simpler pricing model
New Relic offers a unified observability experience, logs, metrics, traces, and synthetics under a single consumption-based pricing model, which many teams find more predictable than Datadog's per-host billing.
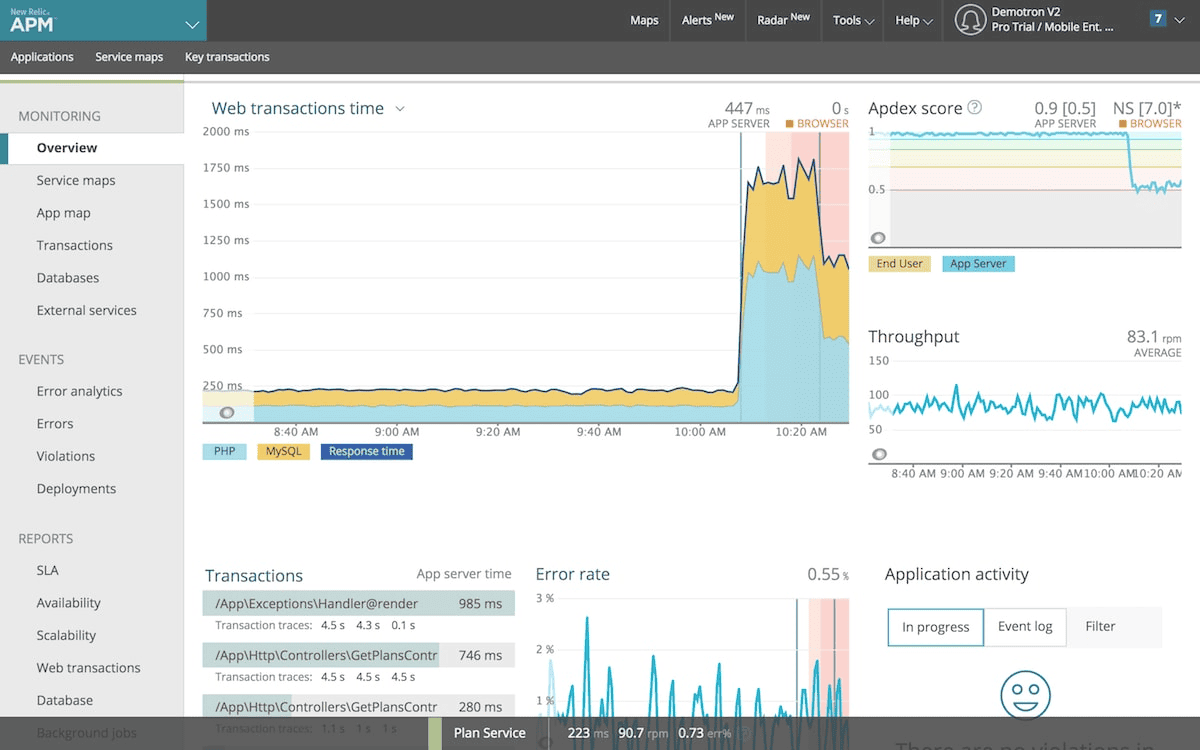
Strengths:
Considerations:
Pricing: Free tier available; paid plans start from approximately $99/month.
Looking for New Relic alternatives? Read Best New Relic Alternatives in 2026 for a full cost and feature comparison.
Website: dynatrace.com
Type: SaaS | Best for: Large enterprises prioritizing automation and AI-driven insights
Dynatrace markets itself as an AI-first observability platform, built around its proprietary AI engine called Davis. It automatically discovers, maps, and monitors your entire topology, from application code to infrastructure, with minimal manual configuration.
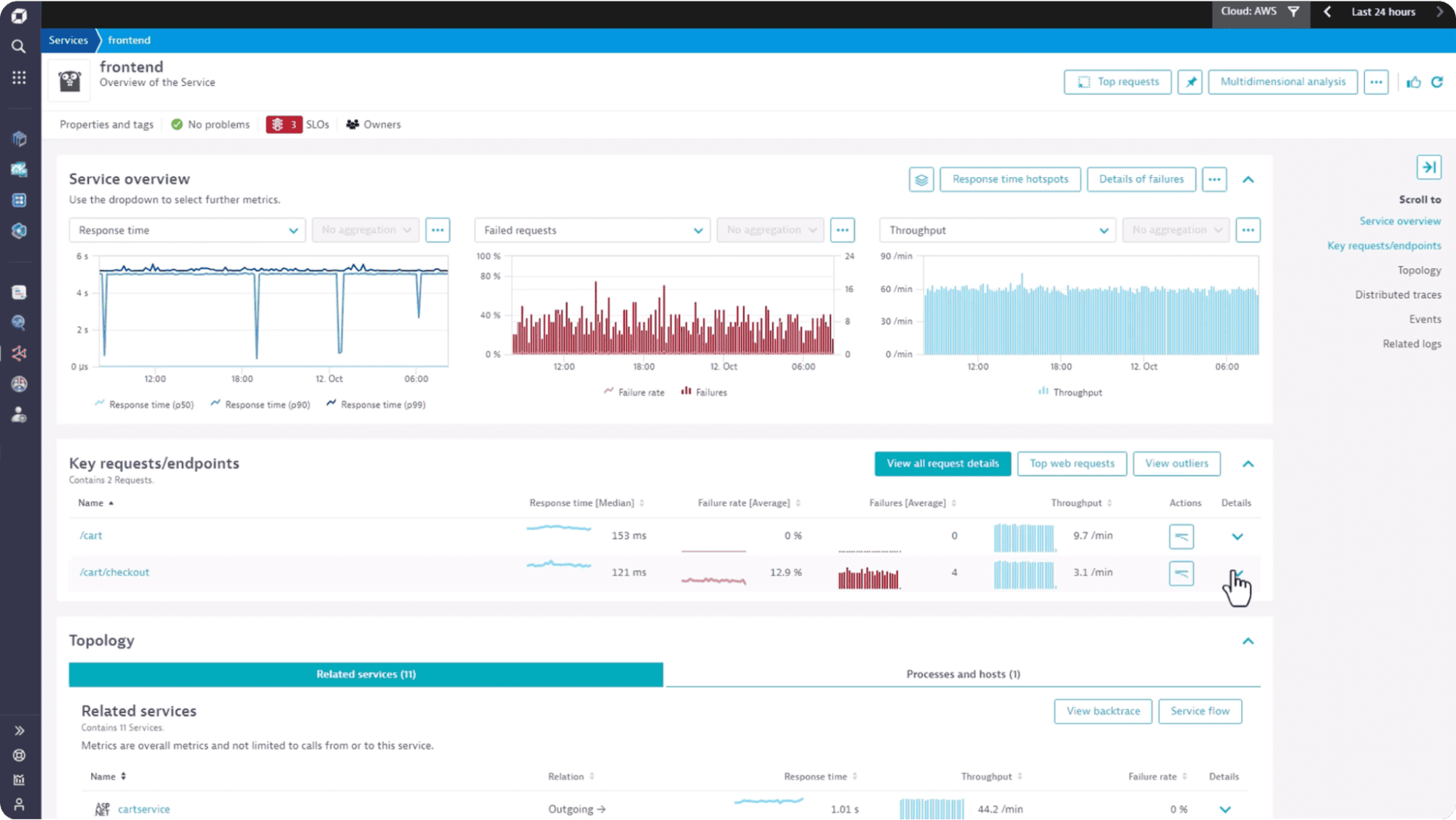
Strengths:
Considerations:
Pricing: Custom enterprise pricing; typically starts at ~$69/host/month.
Frustrated by DDU pricing or vendor lock-in? See 10 Best Dynatrace Alternatives in 2026 for open-source and SaaS options that cost significantly less.
Website: grafana.com
Type: Open-source + SaaS | Best for: Teams with strong technical expertise who want maximum flexibility
Grafana is the world's most popular open-source visualization and dashboarding tool, used by millions of developers globally. The broader Grafana Stack, comprising Grafana, Loki (logs), Tempo (traces), Mimir (metrics), and Pyroscope (profiles), forms a complete open-source observability platform.
Strengths:
Considerations:
Pricing: Open-source (free), Grafana Cloud (free tier available), Grafana Enterprise (custom pricing).
Comparing Grafana to OpenObserve? Read OpenObserve vs Grafana for a detailed breakdown. Also see Top Grafana Alternatives in 2026 if you're looking for a simpler, unified alternative.
Website: splunk.com
Type: SaaS + Self-hosted | Best for: Enterprise security and compliance-heavy environments
Splunk is one of the most recognized names in log management and SIEM, now offering a full observability suite. It excels in security analytics, compliance logging, and large-scale log aggregation. Splunk's SPL (Search Processing Language) is extremely powerful, though it has a steep learning curve.
Strengths:
Considerations:
Pricing: Custom enterprise pricing; ingest-based billing that can become very expensive at scale.
Overpaying for Splunk? See Top 11 Splunk Alternatives and Best Log Management Tools in 2026 to find cost-effective options that cover the same use cases.
Website: elastic.co
Type: Open-source + SaaS | Best for: Teams needing powerful search across telemetry data, hybrid deployments
The Elastic Stack (Elasticsearch, Logstash, Kibana, Beats) has been a foundational component of observability stacks for over a decade. Elastic offers strong search capabilities across all telemetry types and excellent hybrid deployment flexibility, a key differentiator for organizations with strict data residency requirements.
Strengths:
Considerations:
Pricing: Elastic Cloud starts around $95/month; self-hosted incurs significant infrastructure costs.
Migrating away from Elasticsearch? Read From ELK to OpenObserve: Streamlining Log Management and Best Elasticsearch Alternatives 2026 for a detailed cost and feature comparison.
Website: aws.amazon.com/cloudwatch
Type: SaaS (AWS-native) | Best for: Teams running primarily on AWS
Amazon CloudWatch is the native observability service integrated within AWS, providing seamless monitoring for resources and applications in the AWS ecosystem. It collects metrics, logs, and traces from EC2, Lambda, RDS, and dozens of other AWS services automatically.
Strengths:
Considerations:
Pricing: Usage-based; costs vary significantly based on data volume and features used.
Website: prometheus.io
Type: Open-source | Best for: Kubernetes-native metrics collection and alerting
Prometheus is the de facto standard for metrics collection in cloud-native environments. Originally developed at SoundCloud and now a CNCF graduated project, it uses a pull-based model to scrape metrics from instrumented services and supports powerful alerting via Alertmanager.
Strengths:
Considerations:
Pricing: Free and open-source.
See Top 10 Open-Source Observability Tools in 2026 for how Prometheus fits into a complete open-source observability stack alongside OpenObserve.
Website: jaegertracing.io
Type: Open-source | Best for: Distributed tracing in microservices architectures
Jaeger is an open-source, end-to-end distributed tracing tool originally developed by Uber and now a CNCF graduated project. It collects timing data for requests as they flow through distributed systems, enabling teams to pinpoint latency bottlenecks and trace failures to their exact origin.
Strengths:
Considerations:
Pricing: Free and open-source.
| Platform | Type | Logs | Metrics | Traces | Open Source | Pricing Model | Best For |
|---|---|---|---|---|---|---|---|
| OpenObserve | Platform | ✅ | ✅ | ✅ | ✅ | Usage-based / Free tier | Cost-efficient full-stack |
| Datadog | Platform | ✅ | ✅ | ✅ | ❌ | Per-host + ingestion | Large enterprises |
| New Relic | Platform | ✅ | ✅ | ✅ | ❌ | Consumption-based | Mid-market / growing teams |
| Dynatrace | Platform | ✅ | ✅ | ✅ | ❌ | DDU-based | AI-driven automation |
| Grafana Stack | Platform | ✅ | ✅ | ✅ | ✅ | Free / Enterprise | Technical teams |
| Splunk | Platform | ✅ | ✅ | ✅ | ❌ | Ingest-based | Security / compliance |
| Elastic | Platform | ✅ | ✅ | ✅ | Partial | Ingest-based | Search-heavy use cases |
| AWS CloudWatch | Platform | ✅ | ✅ | ✅ | ❌ | Usage-based | AWS-native environments |
| Prometheus | Tool | ❌ | ✅ | ❌ | ✅ | Free | Kubernetes metrics |
| Jaeger | Tool | ❌ | ❌ | ✅ | ✅ | Free | Distributed tracing |
With so many options, decision paralysis is real. Use this framework to narrow down your choice:
For a side-by-side feature and pricing breakdown of every major platform, see Top 10 Observability Platforms in 2026 and Top 10 APM Tools.
The observability landscape is evolving rapidly. Key trends shaping the field in 2026 and beyond:
For a deep dive on full-stack observability strategy: Enterprise Observability Strategy Insights
An observability tool is software that collects and helps teams interpret telemetry data, logs, metrics, and/or traces, from their applications and infrastructure. It enables engineers to understand the internal state of a system by analyzing its external outputs, making it possible to debug issues, optimize performance, and prevent outages in complex distributed environments.
Monitoring tracks predefined metrics and alerts when known thresholds are crossed, it tells you that something is wrong. Observability goes further by allowing teams to ask arbitrary questions about system behavior and understand why something is wrong, even for issues that were never anticipated. Observability requires richer data (logs + metrics + traces) and more sophisticated tooling than traditional monitoring.
The three pillars are metrics (numeric performance measurements), logs (timestamped event records), and traces (request flows through distributed services). Together, they provide full-stack visibility into system behavior.
OpenTelemetry (OTel) is an open-source, vendor-neutral framework for generating and collecting telemetry data (logs, metrics, and traces). It is now the industry standard for instrumentation, supported by virtually all major observability platforms. Using OTel means you can change your back-end observability platform without re-instrumenting your code. Both OpenObserve and Grafana offer native OTel support.
An observability tool typically handles one piece of the observability puzzle, for example, Grafana handles visualization, Prometheus handles metrics, and Jaeger handles tracing. An observability platform integrates all of these capabilities (collection, storage, analysis, visualization, alerting) into a unified solution, eliminating the need to integrate and manage multiple tools. See: Top 10 Observability Platforms in 2026.
Costs vary widely. The median annual observability spend for enterprises is approximately $1.95 million. Commercial SaaS platforms like Datadog can run $15–$23/host/month plus data ingestion fees, which scale dramatically. Open-source and cost-optimized platforms like OpenObserve can reduce TCO by 60–90% through efficient storage architectures (columnar storage, S3-native) and usage-based pricing.
Grafana is primarily a visualization and dashboarding tool. While the broader Grafana Stack (Loki + Tempo + Mimir + Grafana) forms a complete observability platform, standalone Grafana only handles the visualization layer and needs to be paired with other tools for data collection and storage. See the detailed comparison: OpenObserve vs Grafana and Top Grafana Alternatives in 2026.
Yes, many organizations run multiple specialized tools. A common open-source stack might combine Prometheus (metrics) + Loki (logs) + Jaeger (traces) + Grafana (dashboards). However, unified platforms offer better cross-signal correlation, simpler operations, and often lower total cost.
For startups, OpenObserve offers the best value, a full-featured, open-source platform with a free cloud tier (up to 200 GB/day ingestion) and dramatically lower storage costs as you scale. New Relic is another strong option with a generous free tier. Both are significantly more cost-effective than Datadog or Dynatrace for smaller teams.
Passionate about observability, AI systems, and cloud-native tools. All in on DevOps and improving the developer experience.












