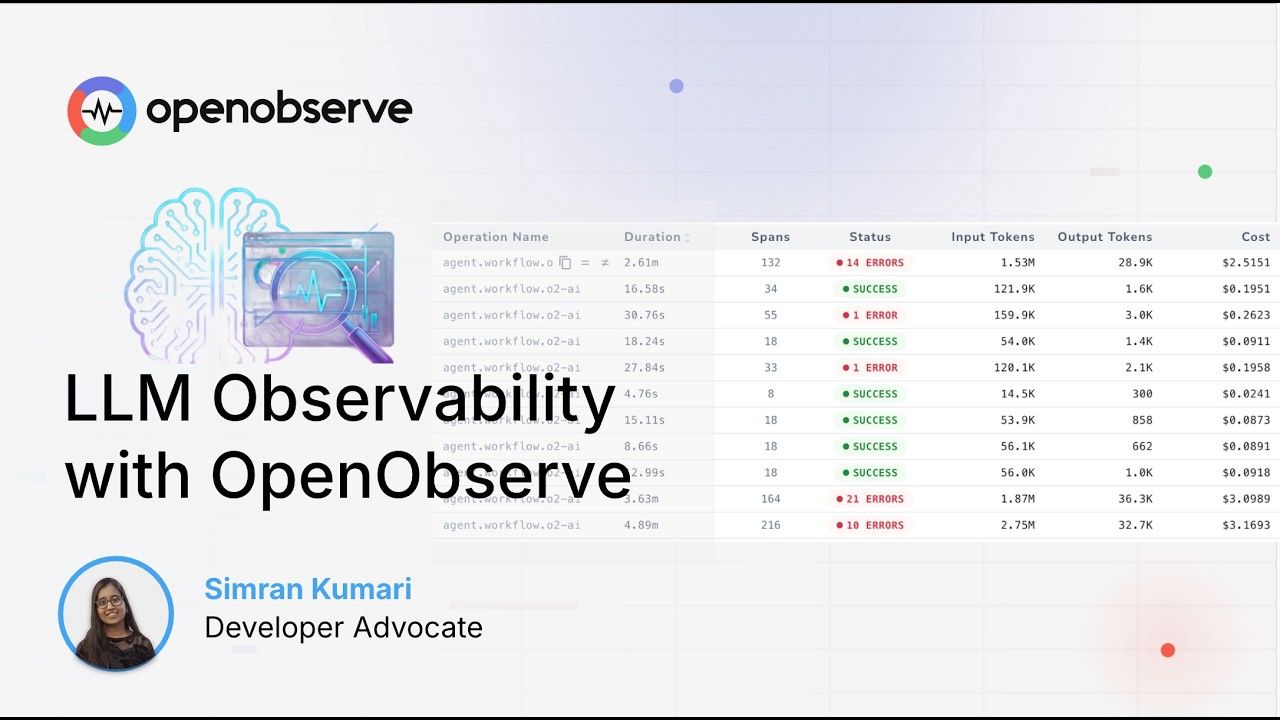
LLM Observability
End-to-end tracing across prompts, responses, and agent workflows.

Debug AI Faster
Pinpoint issues across every prompt, tool call, and model response within agent chains.
Eliminate Cost Surprises
Track token consumption and performance across every model.
Own Your Data
Self-host or run in your own cloud, ensuring sensitive prompts and responses never leave your infrastructure.
LLM Observability
Seamless Integration
Multi-Ecosystem Client Support
Connect existing ecosystems like OpenTelemetry, LangChain, and LangFuse to OpenObserve. Ingest instrumentation data immediately, no pipeline re-architecting required.
Unified Schema Normalization
Unify your data schema across all frameworks and model providers. Format incoming telemetry instantly to stop fragmentation and simplify cross-model debugging.
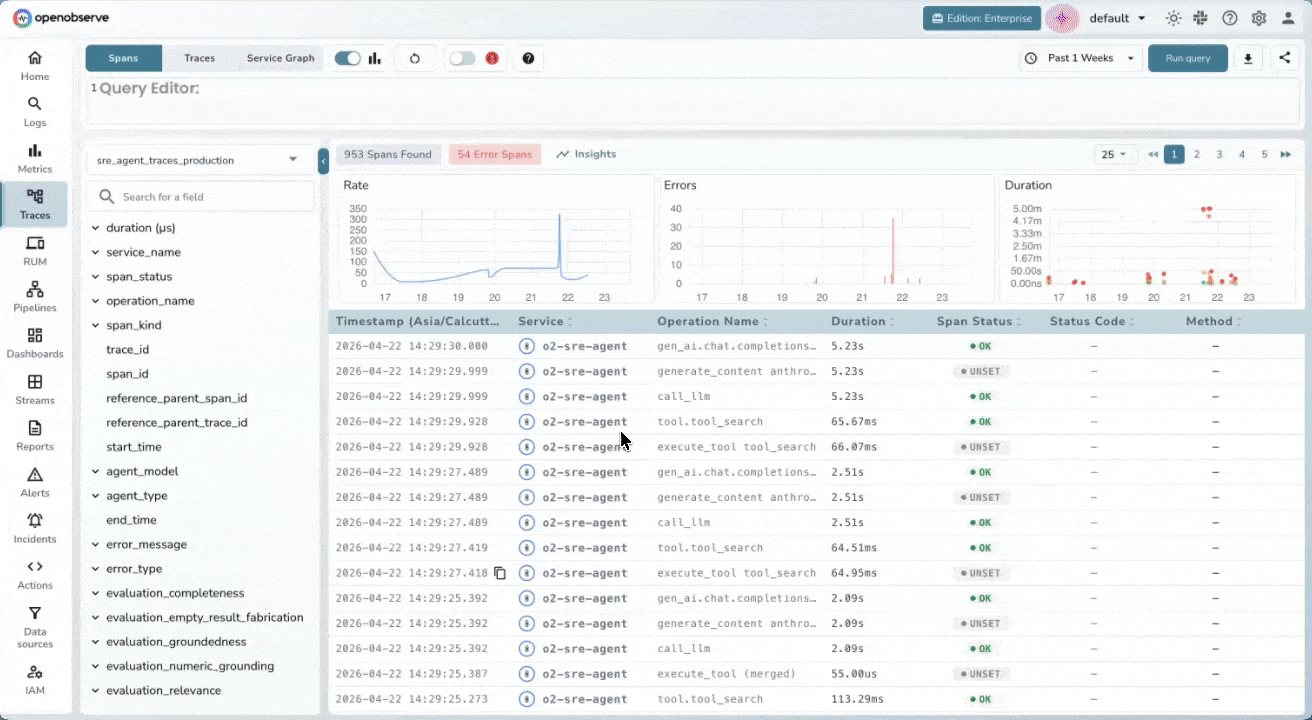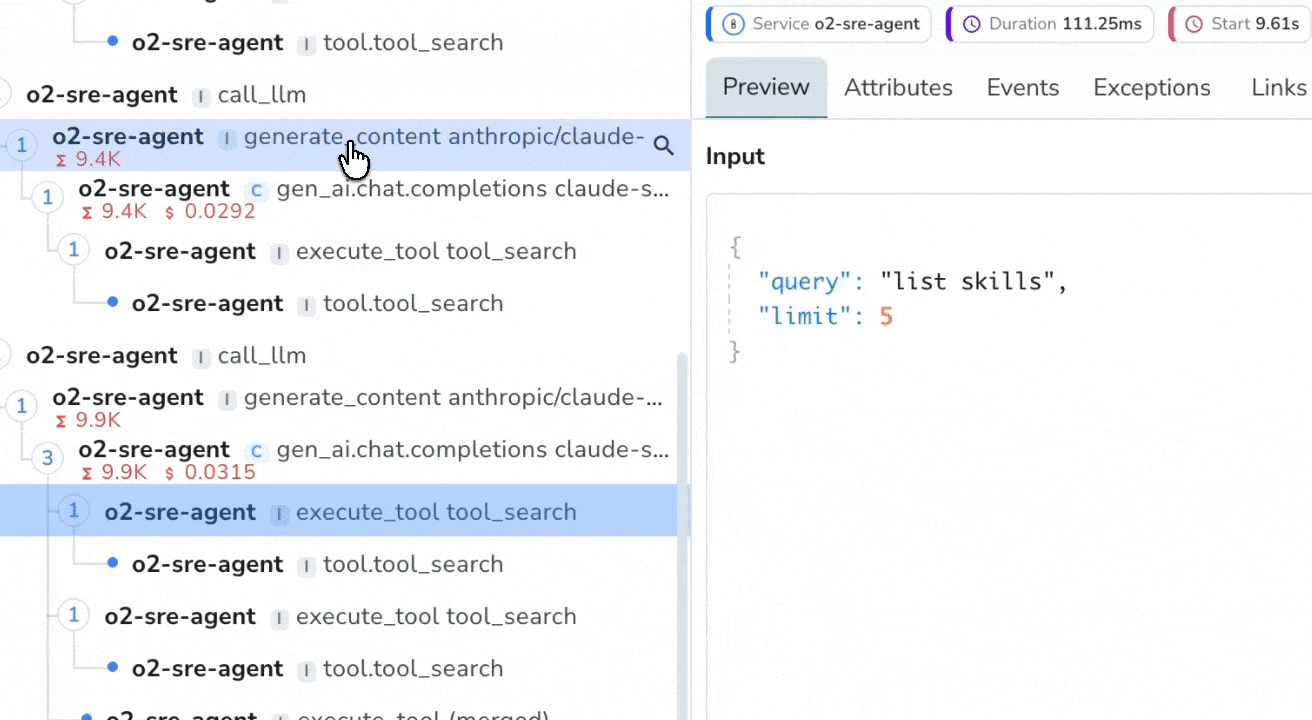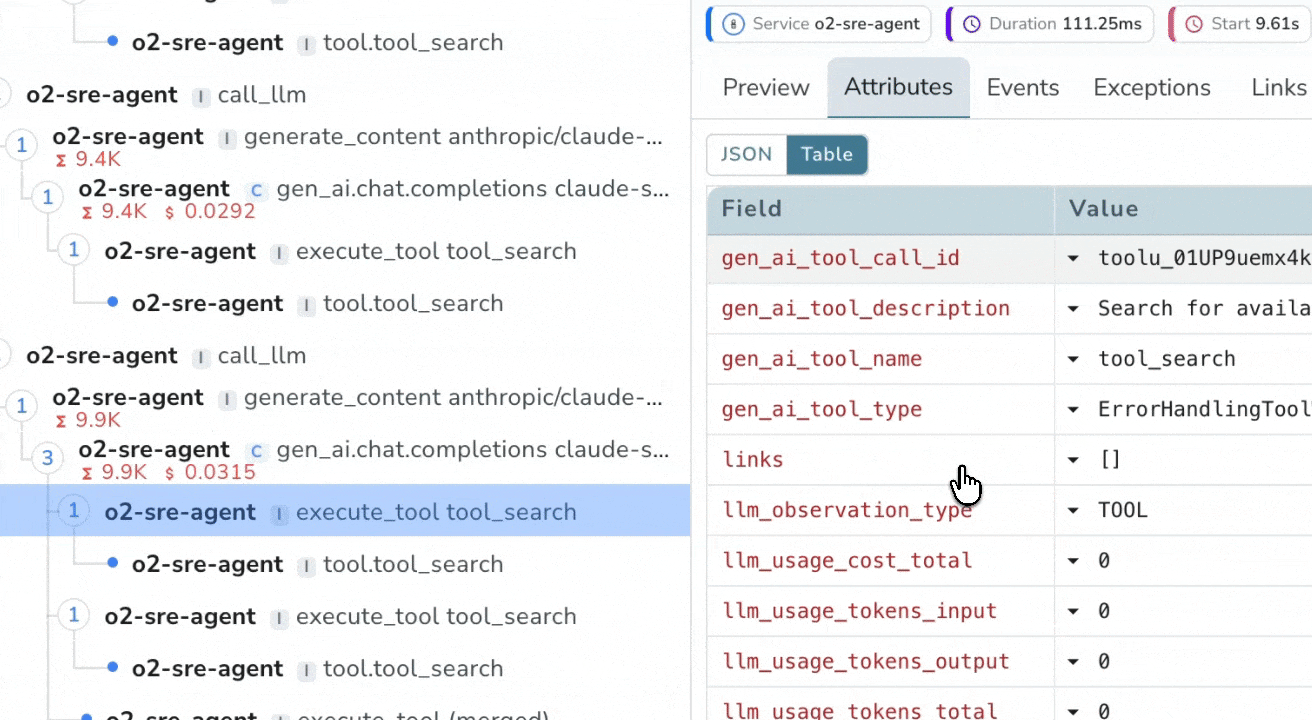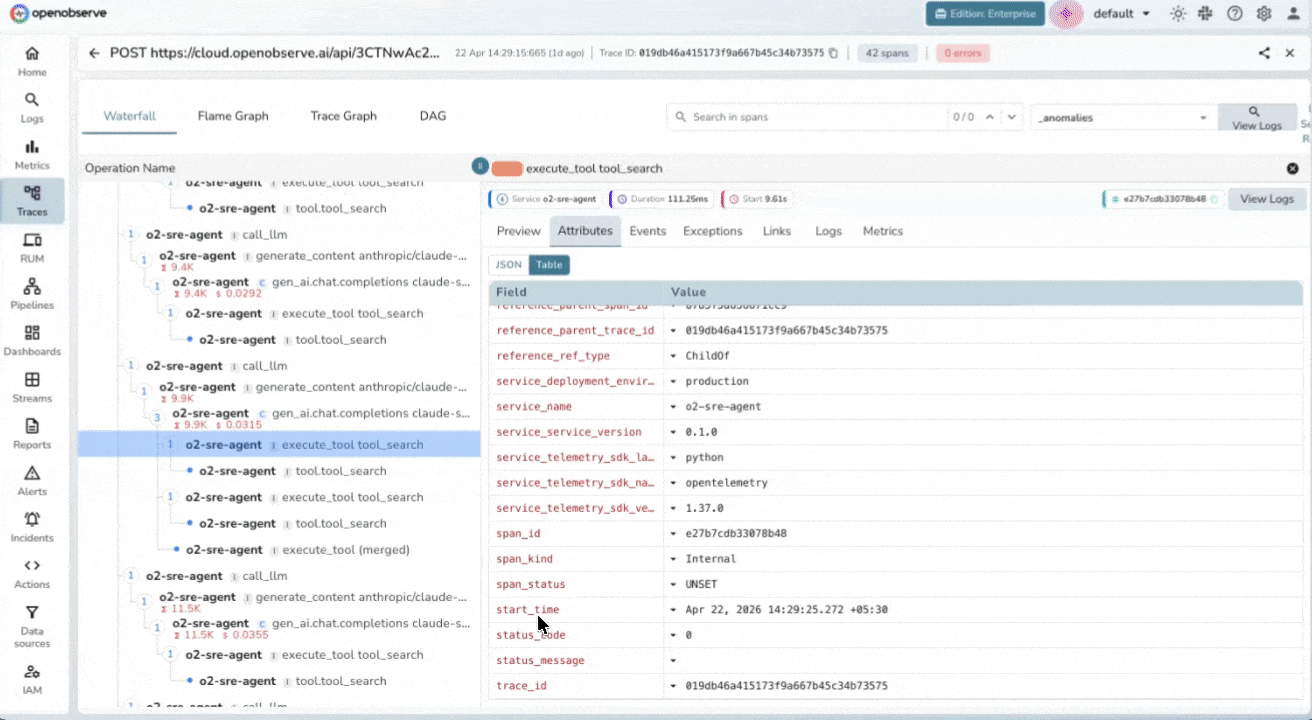
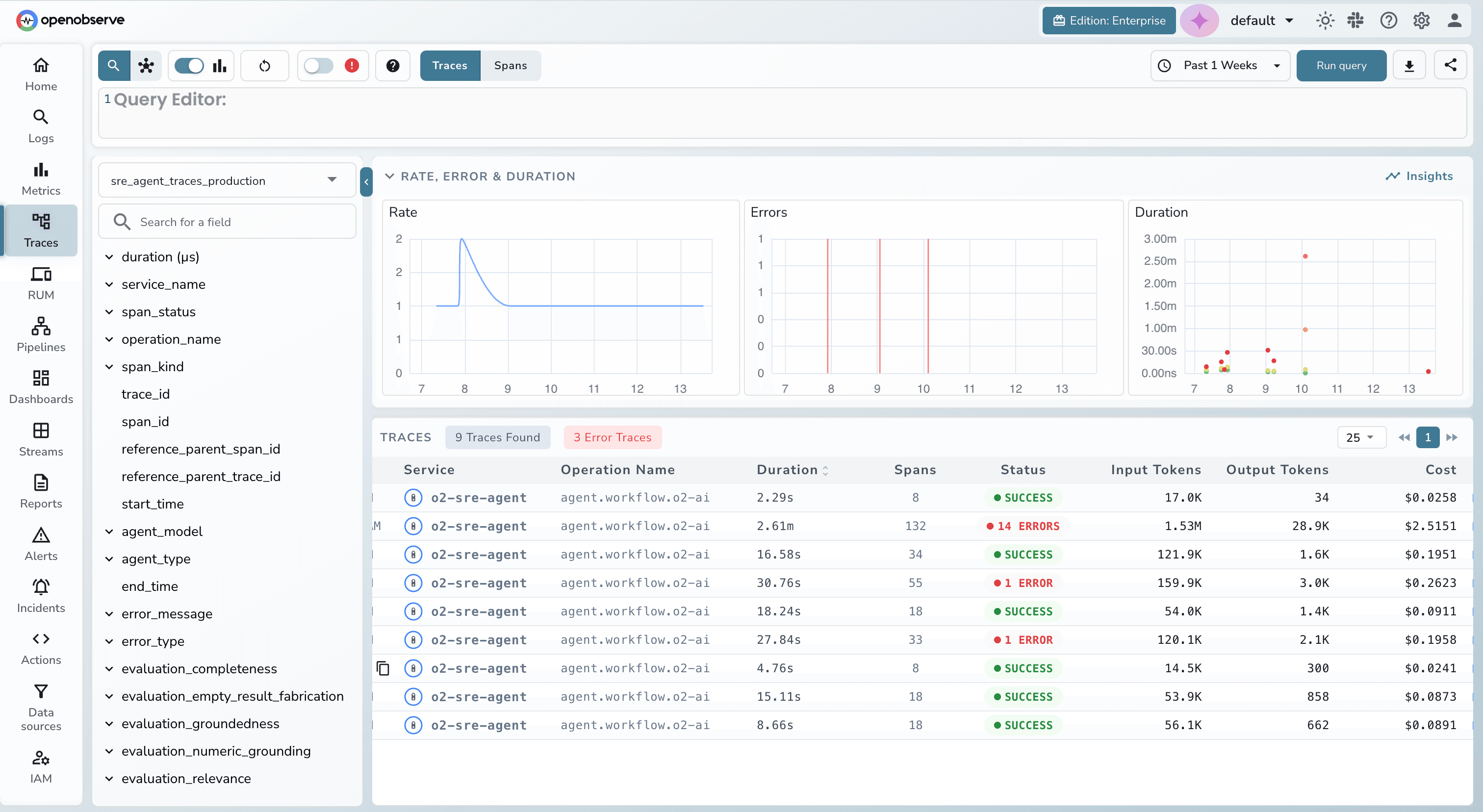
Distributed Tracing for LLM Pipelines
End-to-End Span Tracing
Visualize the full execution tree of every LLM call, from system prompt to final response. Record inputs, outputs, duration, and token counts across LangChain, LlamaIndex, OpenAI SDK or any OpenTelemetry-instrumented framework.
Multi-Agent Workflow Visibility
Stitch traces across process boundaries automatically using W3C context propagation. When agents hand off to sub-agents or call external tools, you’ll see exactly which step introduced a hallucination, timeout, or unexpected output.
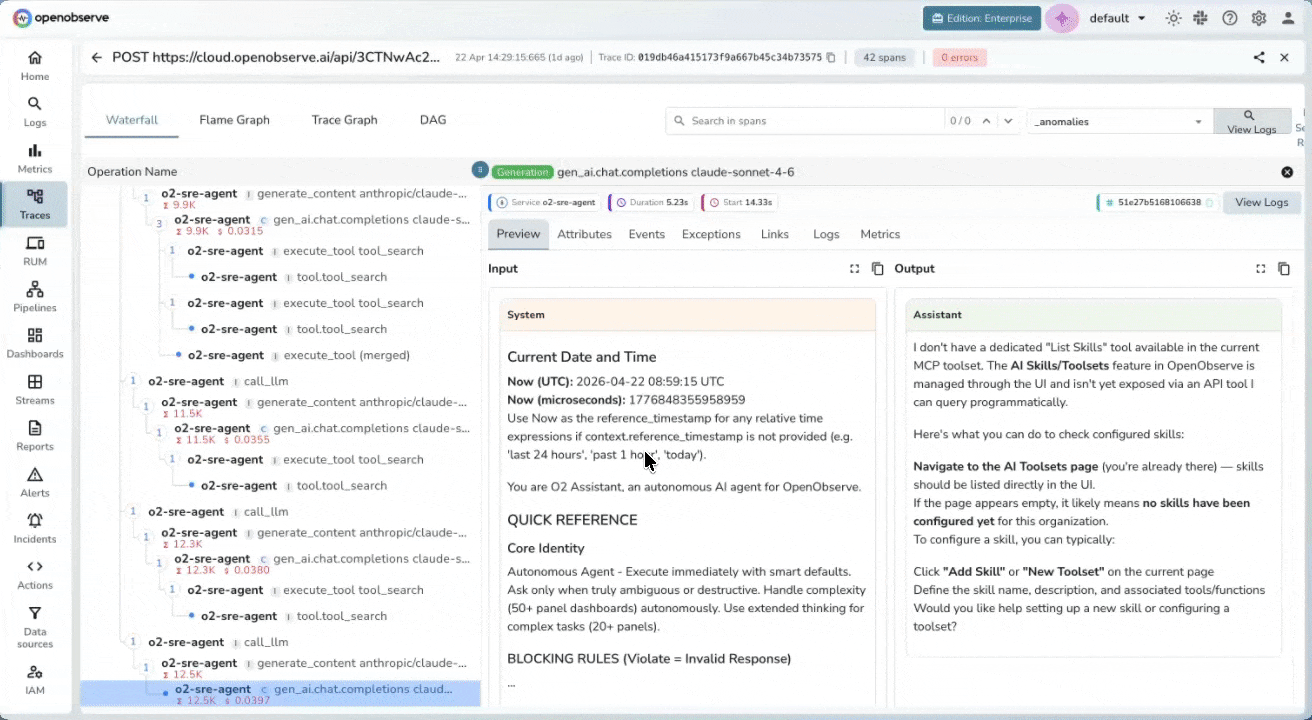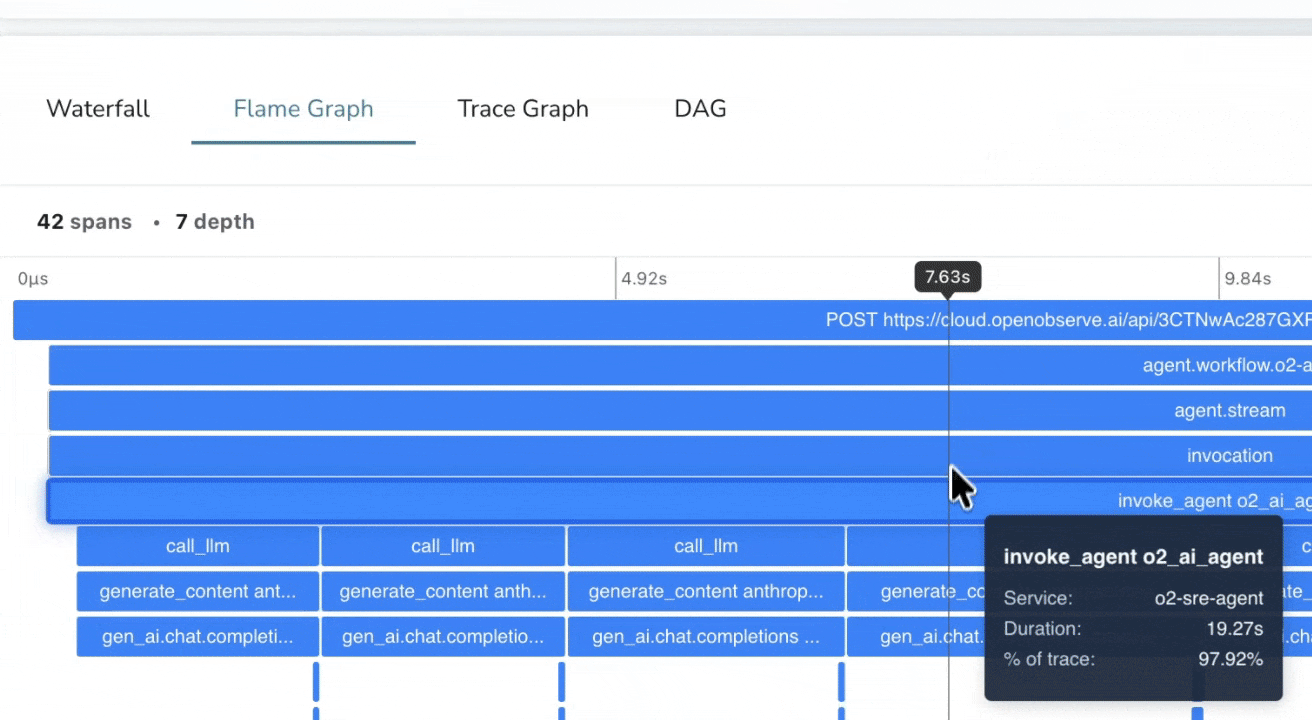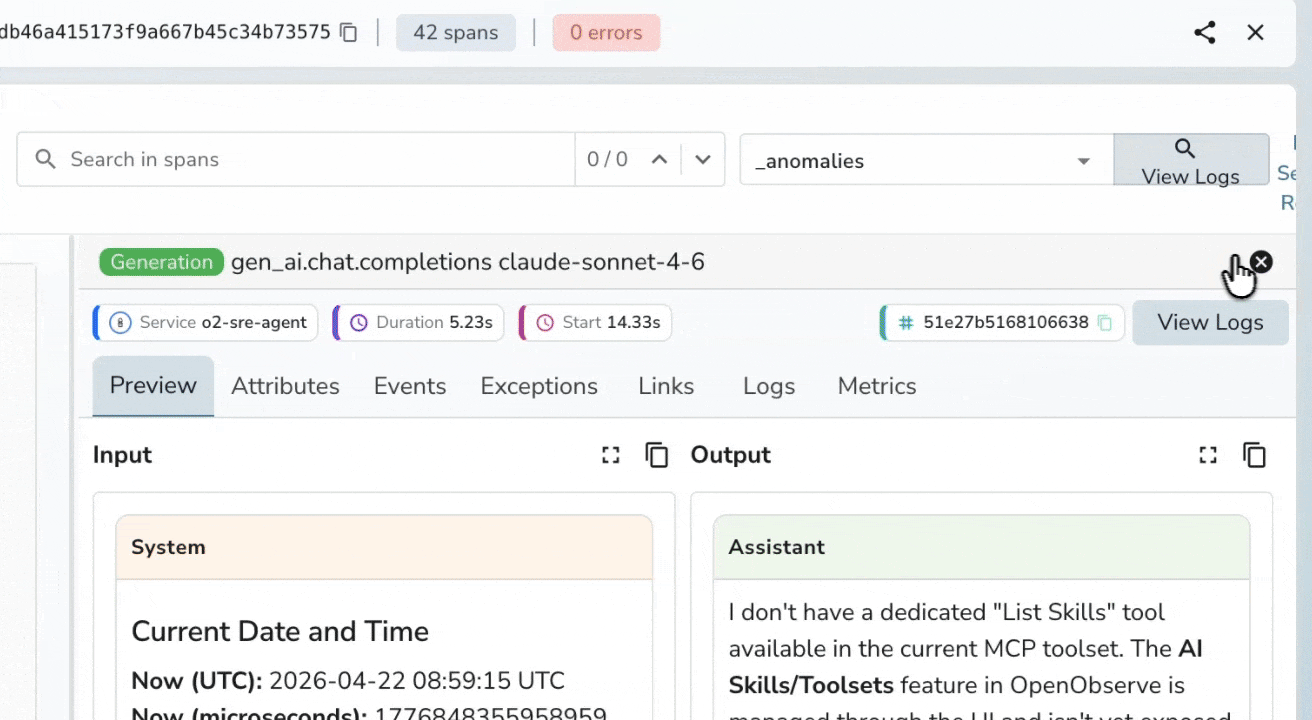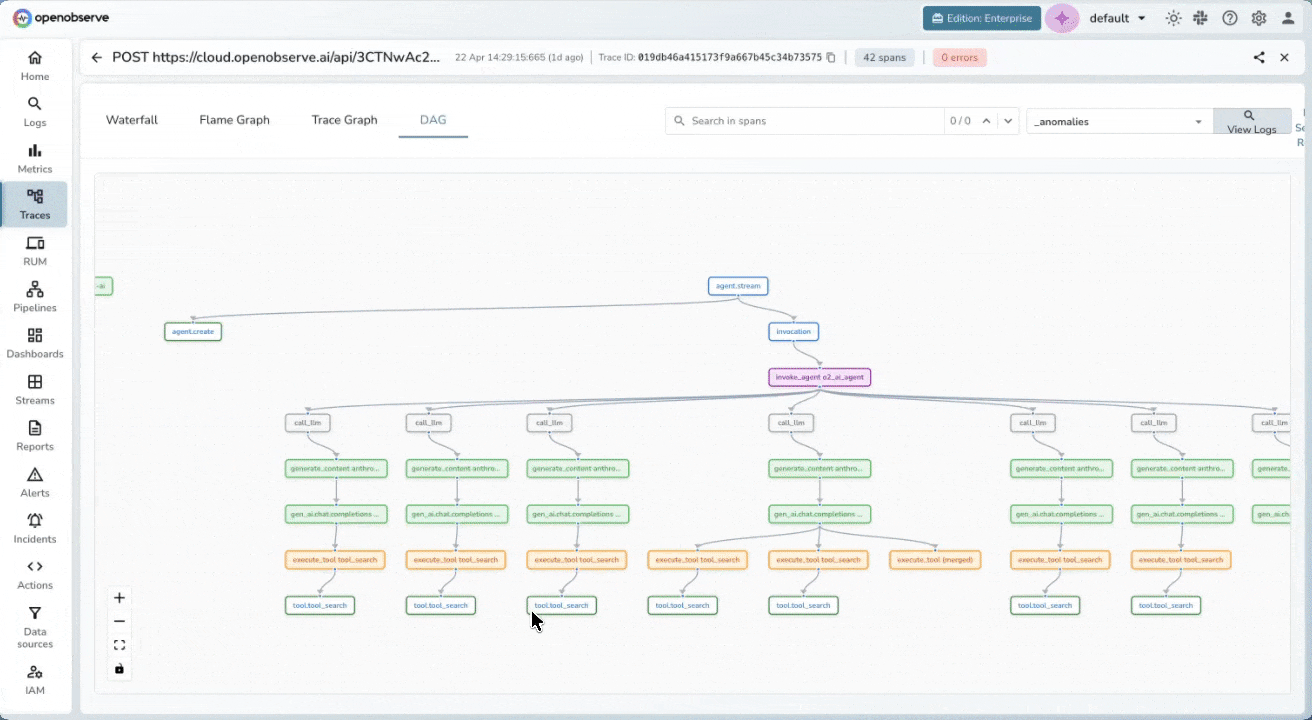
Trace-Level Cost Transparency
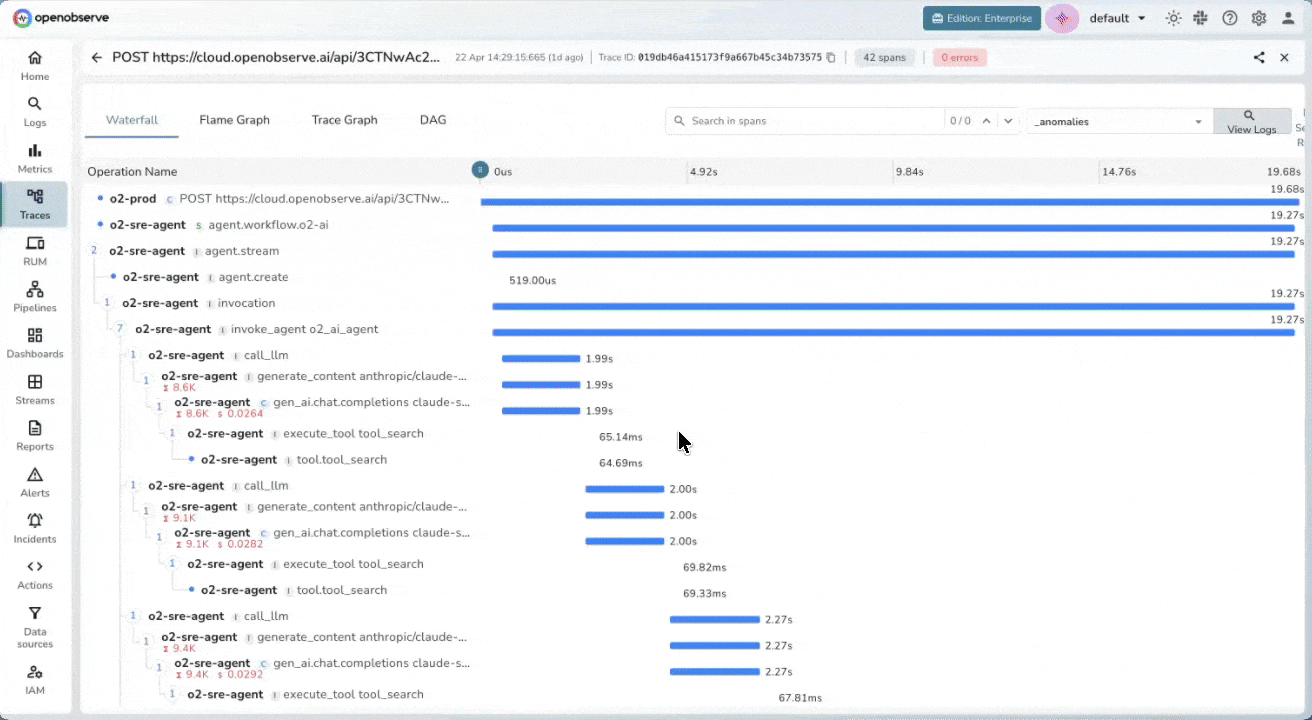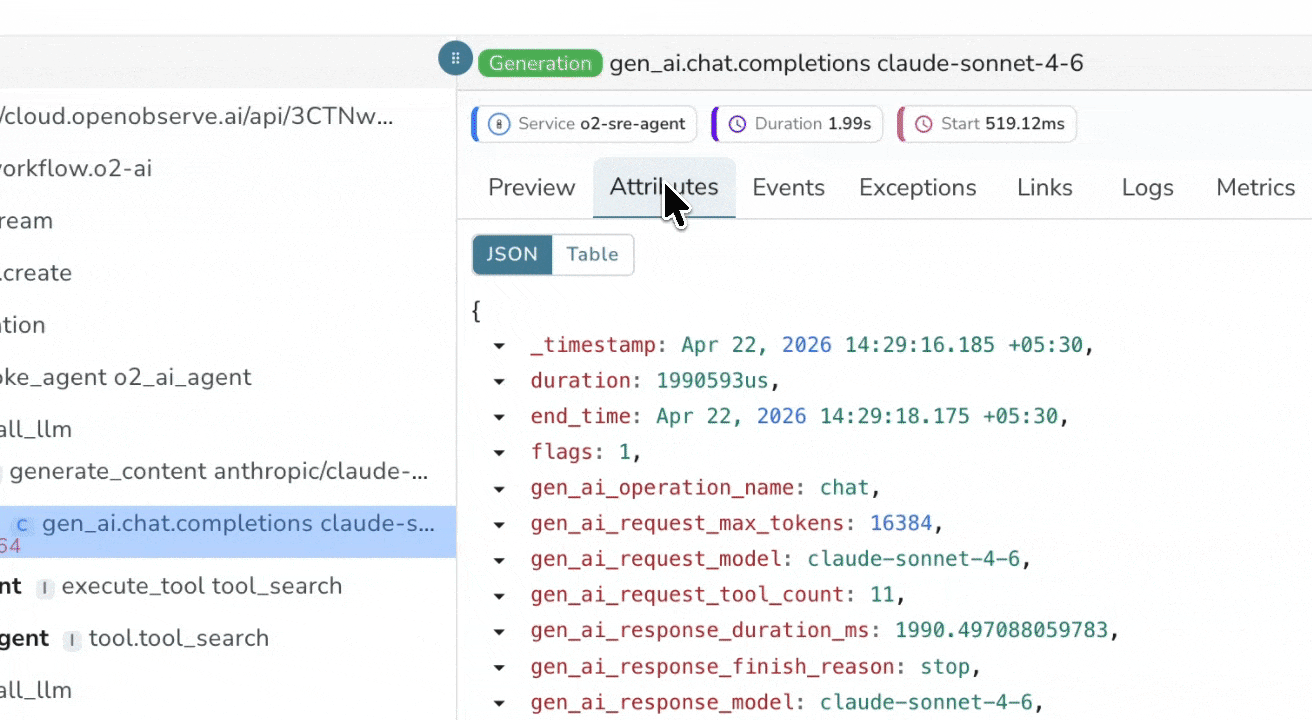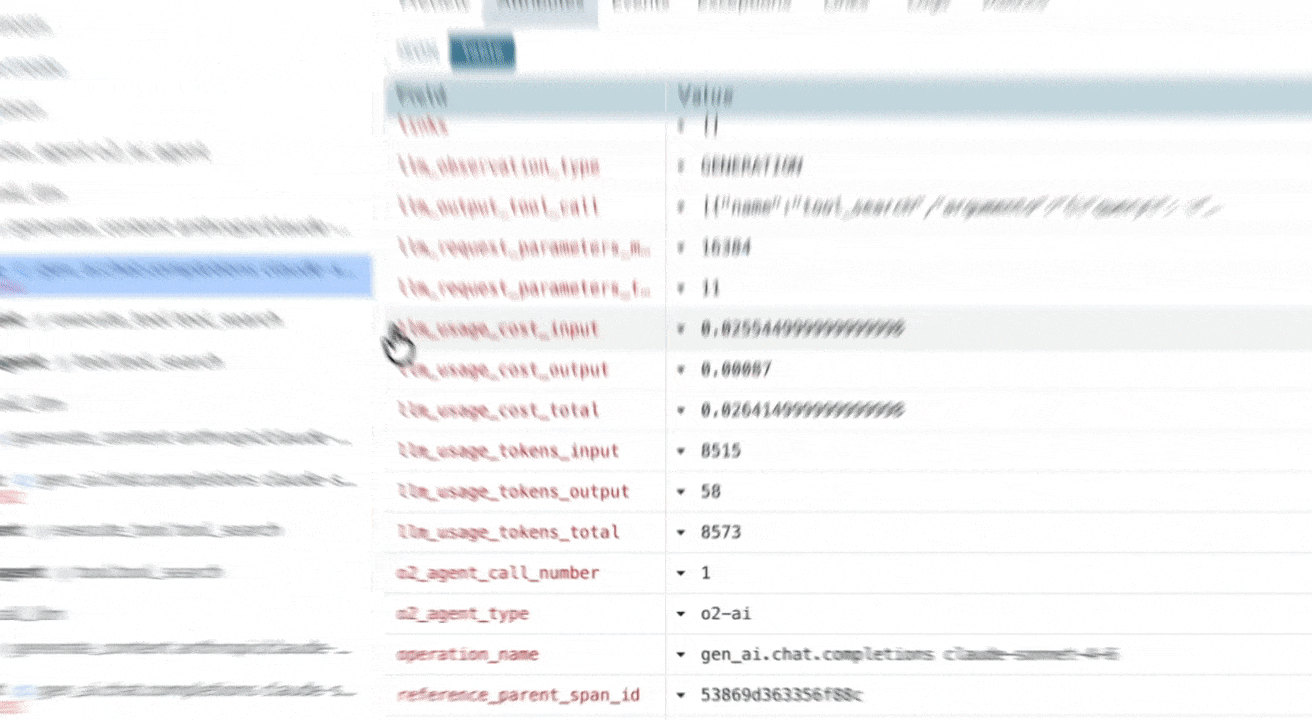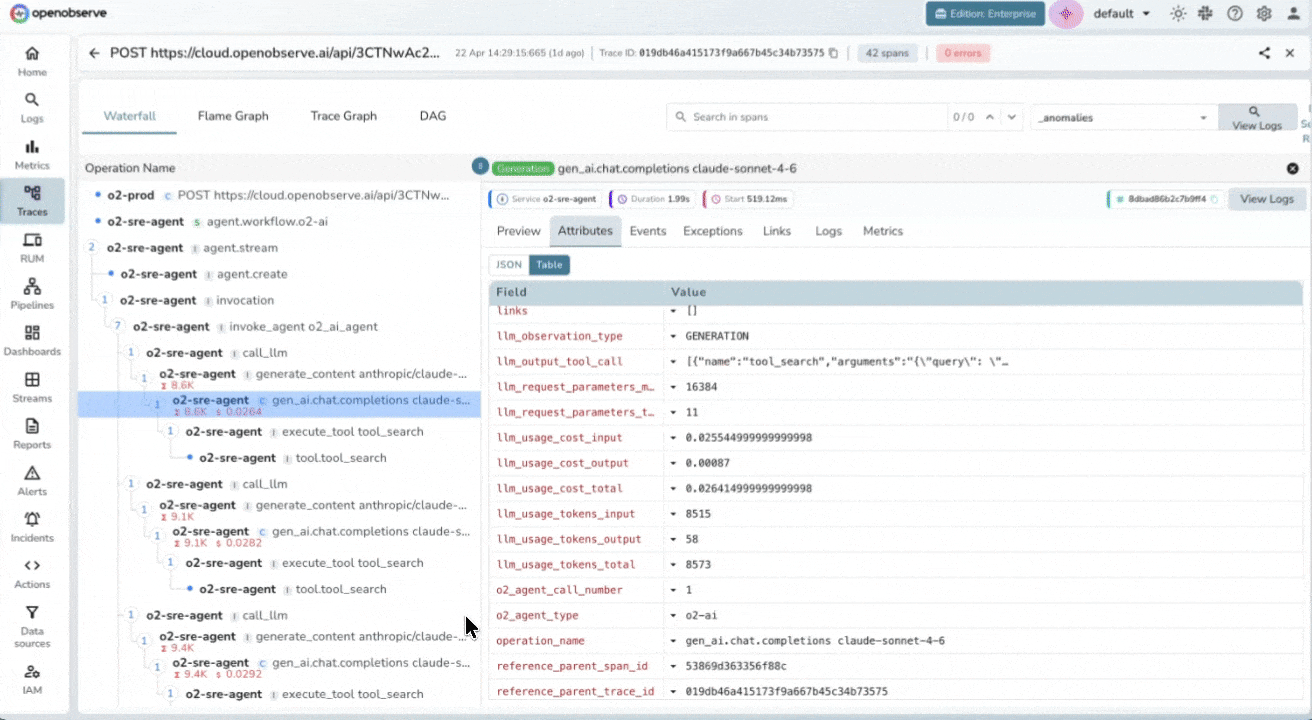
Token Usage & Cost Estimation
Analyze token usage and costs per request and per span. Identify the most expensive steps in your LLM workflows instantly with real-time estimates based on your custom model pricing.
Per-Span Input & Output Inspection
Inspect the exact prompts, context, and model responses at every span level. Debug context contamination, prompt drift, or unexpected outputs without guesswork, directly from the trace view.
Search & Analytics
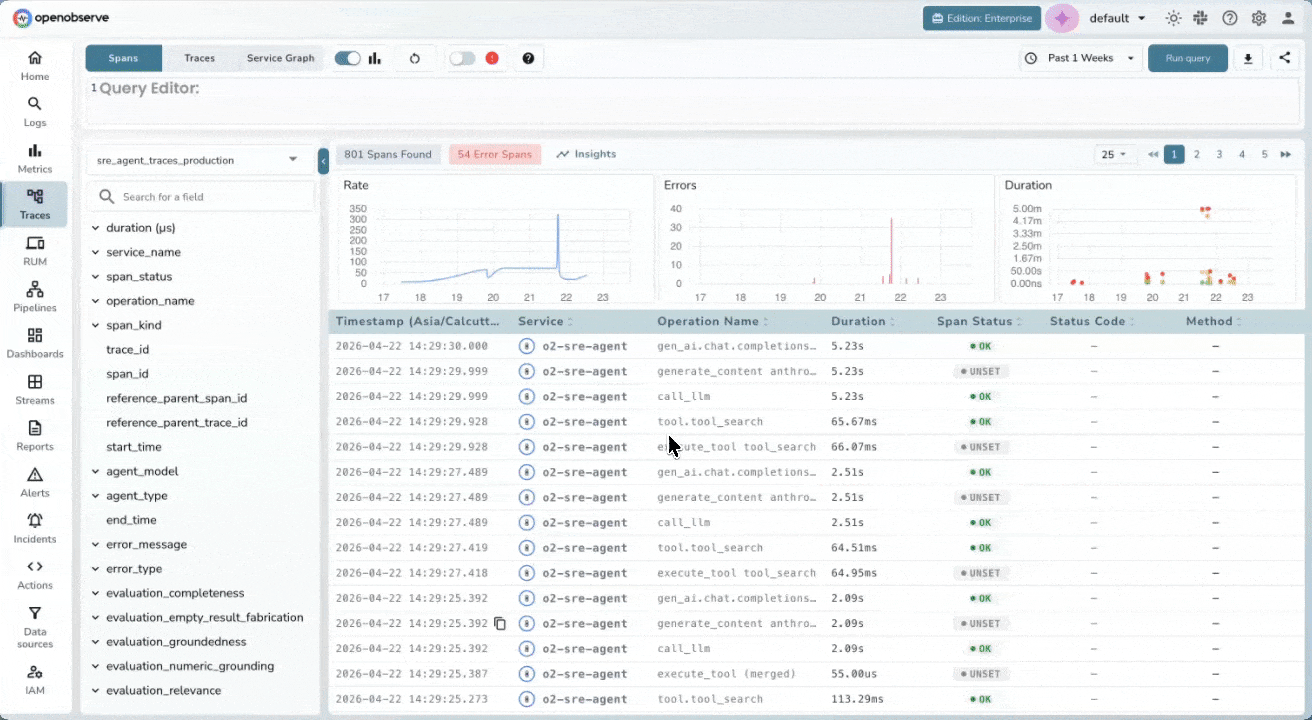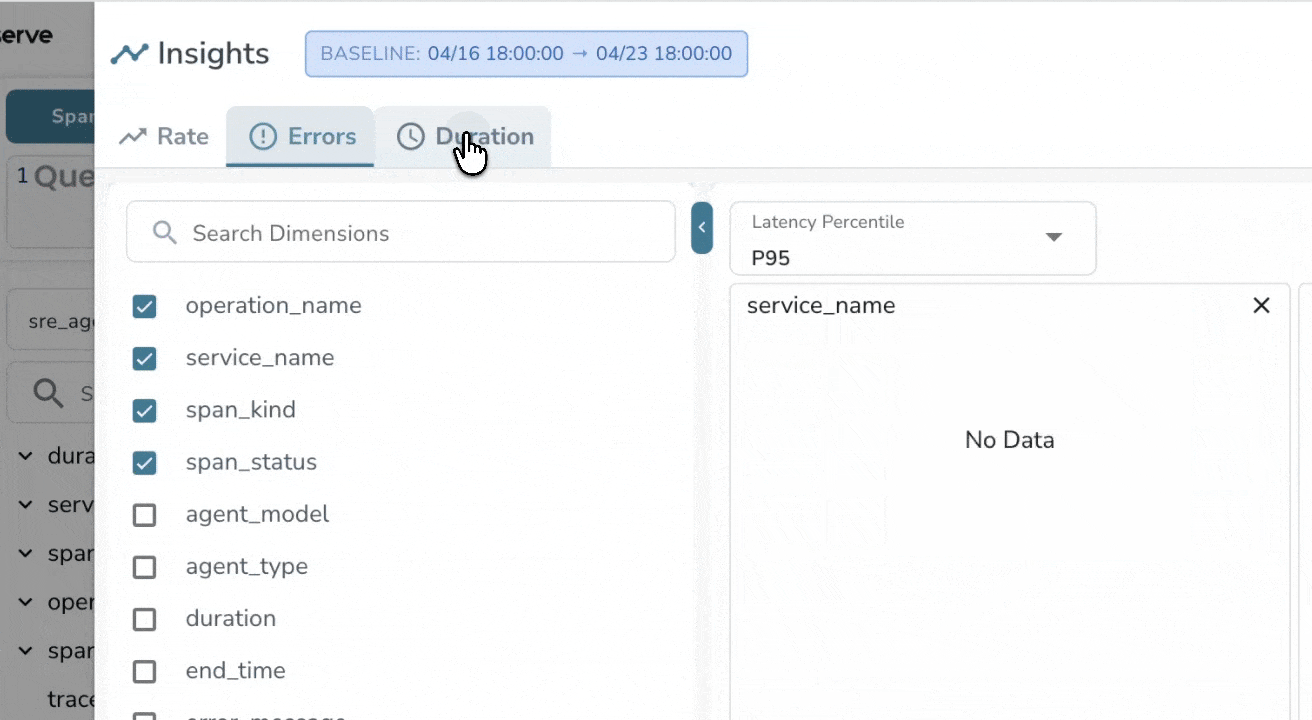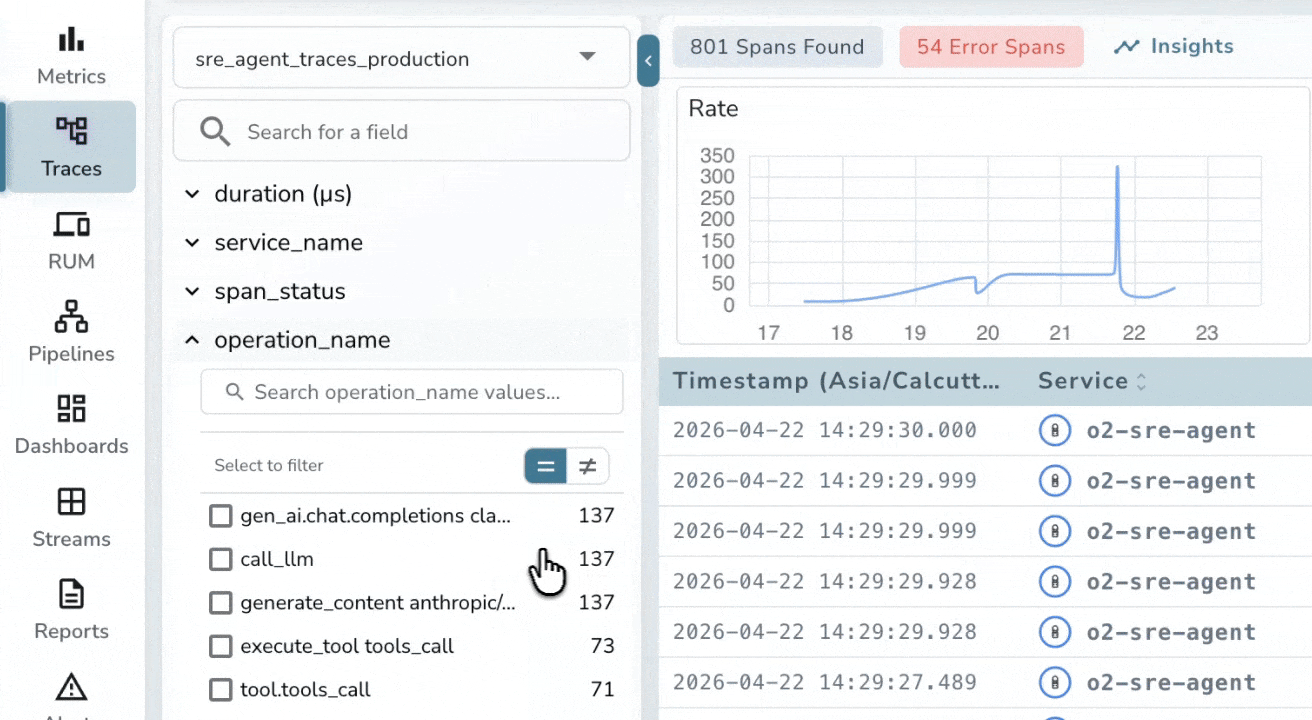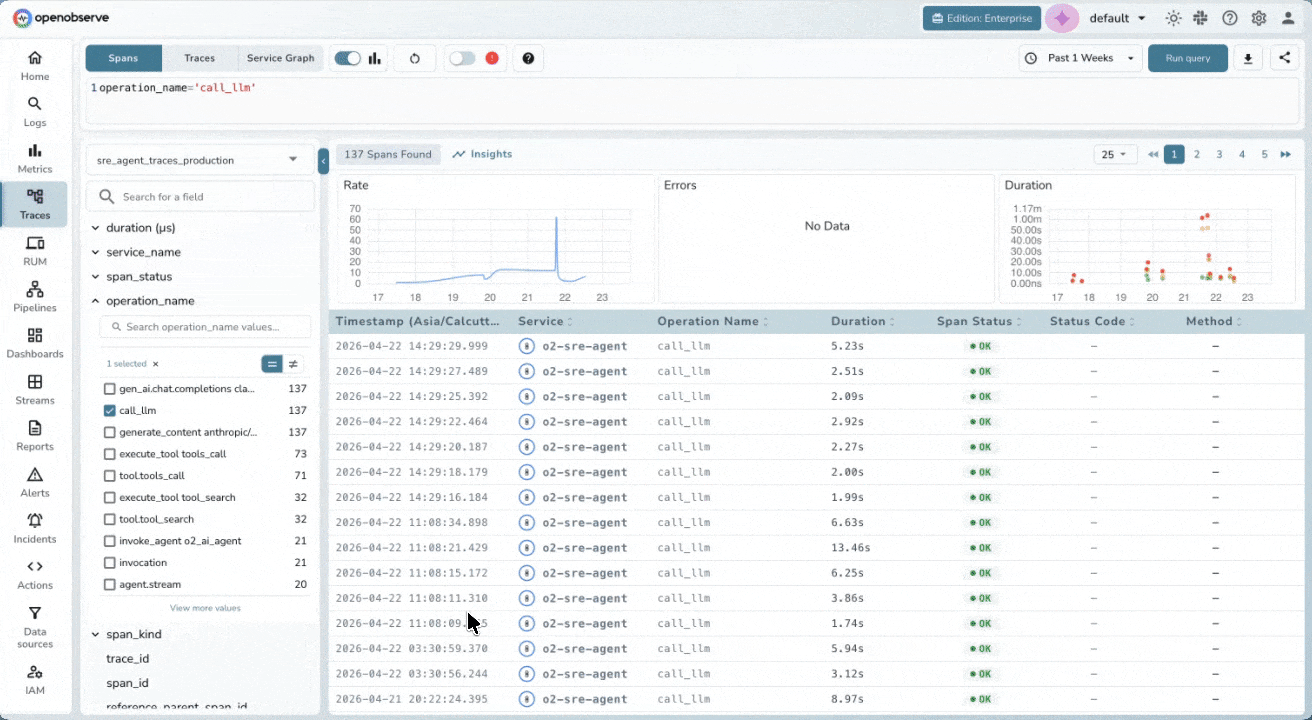
LLM-Native Trace Search
Configurable Model Pricing
Define and manage custom model pricing to match your real billing rates. This enables accurate cost calculation, forecasting, and internal chargeback/showback, without relying on generic published estimates.
LLM Observability FAQs
Resources
Explore guides, videos, and articles to help you get the most out of LLM Observability.