We Just Raised $10M and Launched a Set of New AI Capabilities. Here's What We're Building Toward.

Prabhat Sharma
April 28, 2026
6 min read
Don’t forget to share!
What Nobody Tells You About Running AI in Production
Try OpenObserve Cloud today for more efficient and performant observability.

Today is a milestone day for OpenObserve, and I want to take a moment to share not just what we're announcing, but why it matters and what the road ahead looks like from where I'm standing.
We're announcing two things simultaneously: a $10 million Series A led by Nexus Venture Partners and Dell Technologies Capital, and the launch of our platform's Observability 3.0 capabilities — our new generation of AI-native products and features that includes an autonomous AI SRE, anomaly detection, and LLM observability.
These aren't separate stories. They're the same story.
When I started OpenObserve in 2022, the observability market was dominated by tools built for a different era. Prometheus and Grafana were pieced together for static infrastructure. The ELK stack was architected before anyone knew what AI-scale telemetry volumes would look like. Commercial vendors had become expensive, bloated, and frankly, they were starting to solve the wrong problem — putting their customers on data diets instead of helping them make sense of the data they already had.
The hypothesis was simple: there had to be a better way to build this. A single, high-performance platform. S3-native architecture. Significantly lower storage costs. No database management overhead. We wanted to make world-class observability accessible to any engineering team, regardless of whether they had a Datadog-sized budget.
Four years later, more than 7,000 organizations are running OpenObserve, including companies that are ingesting petabytes of data every day. Our open-source project has crossed 19,000 GitHub stars. And two of our original seed investors believed strongly enough in what we're building to lead this Series A preemptively, before we even went to market.
That last part means a lot to me.
Here's what's changed in the last two years: AI has entered the infrastructure stack, and it's broken observability for most teams.
LLM workloads generate telemetry at volumes that legacy stacks simply weren't designed to handle. The data isn't just more voluminous — it's more complex, more interconnected, and more time-sensitive. And yet most engineering teams are still running 6 to 15 separate tools, stitching together their own Frankenstein observability stack, and manually triaging incidents by scrolling through logs at 2am.
That's not an observability problem. That's a fire department that doesn't have the budget for smoke detectors.
The industry's response from legacy commercial vendors has largely been to ingest less data, charge more for what you do ingest, and add another point tool on top of an already fragmented stack.
We think that's exactly backwards. Engineering teams don't need less context. They need better context, delivered autonomously, before the incident becomes a crisis.
That's what Observability 3.0 is.
Let me be concrete about what we've built, because I think the term "AI-native" gets thrown around in ways that obscure more than they reveal.
AI SRE is an autonomous layer that lives inside OpenObserve and analyzes your telemetry in real time. During an incident, modern systems generate more data than any team can review manually. AI SRE identifies root causes and recommends or takes corrective actions without requiring engineers to sort through the noise themselves. This is the shift from reactive to proactive operations that I've been working toward since day one. It looks at your logs, metrics, traces, GitHub, Kubernetes cluster, AWS, GCP, Azure, and more.
Anomaly detection allows predictions that give your team early warning before a system degrades into a full incident. Instead of getting paged when something is already broken, you get a signal while there's still time to act. It surfaces inside your existing OpenObserve workflow with no new interface to learn and no context switching required.
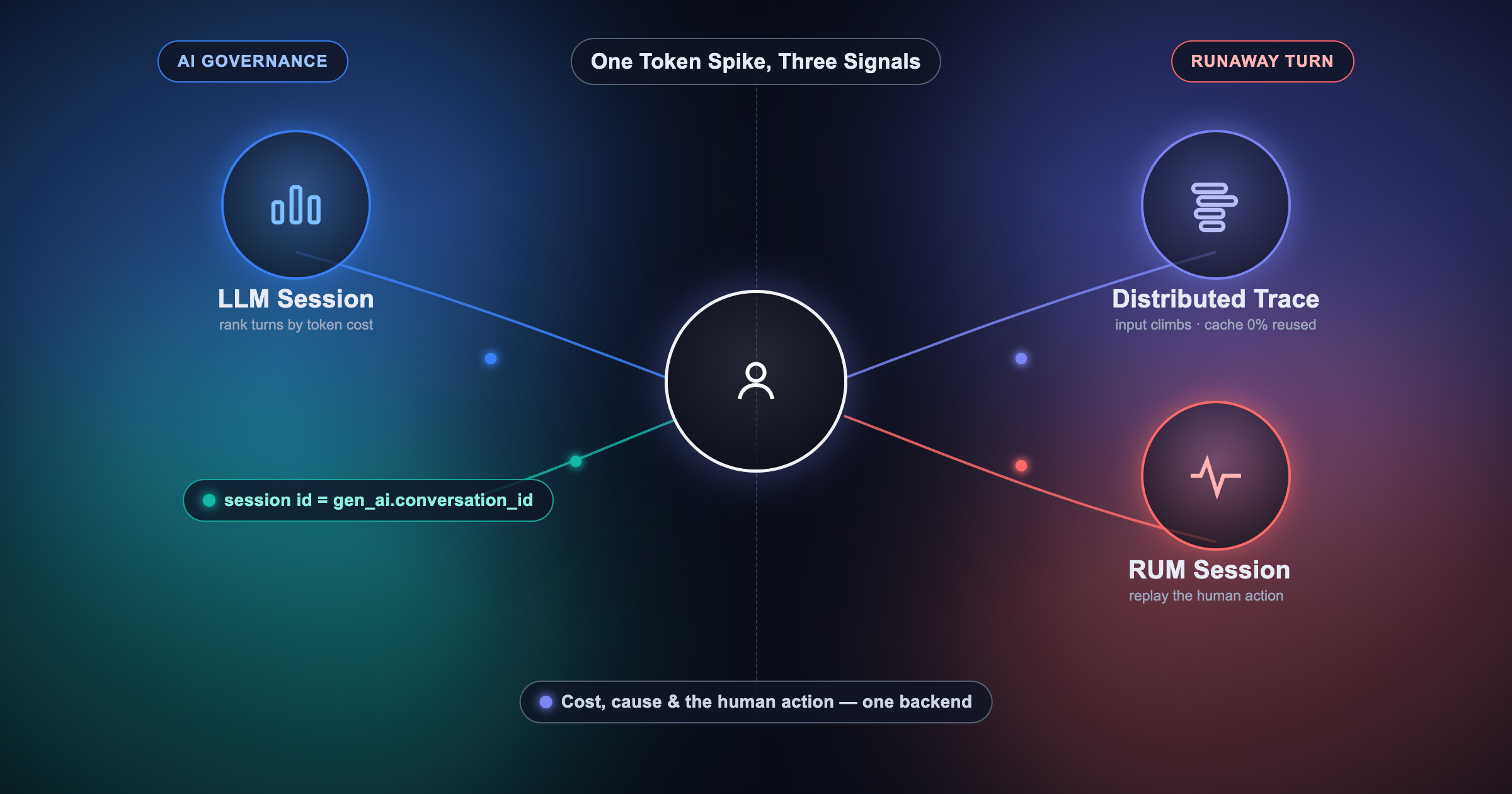
LLM Observability extends our telemetry pipeline to cover prompt monitoring, eval tracking, and generative AI application performance. If you're building AI-powered products — and increasingly, everyone is — you need the same level of visibility into your LLM layer that you've always had into your backend APIs, servers, and frontend. OpenObserve now gives you that in a single view.
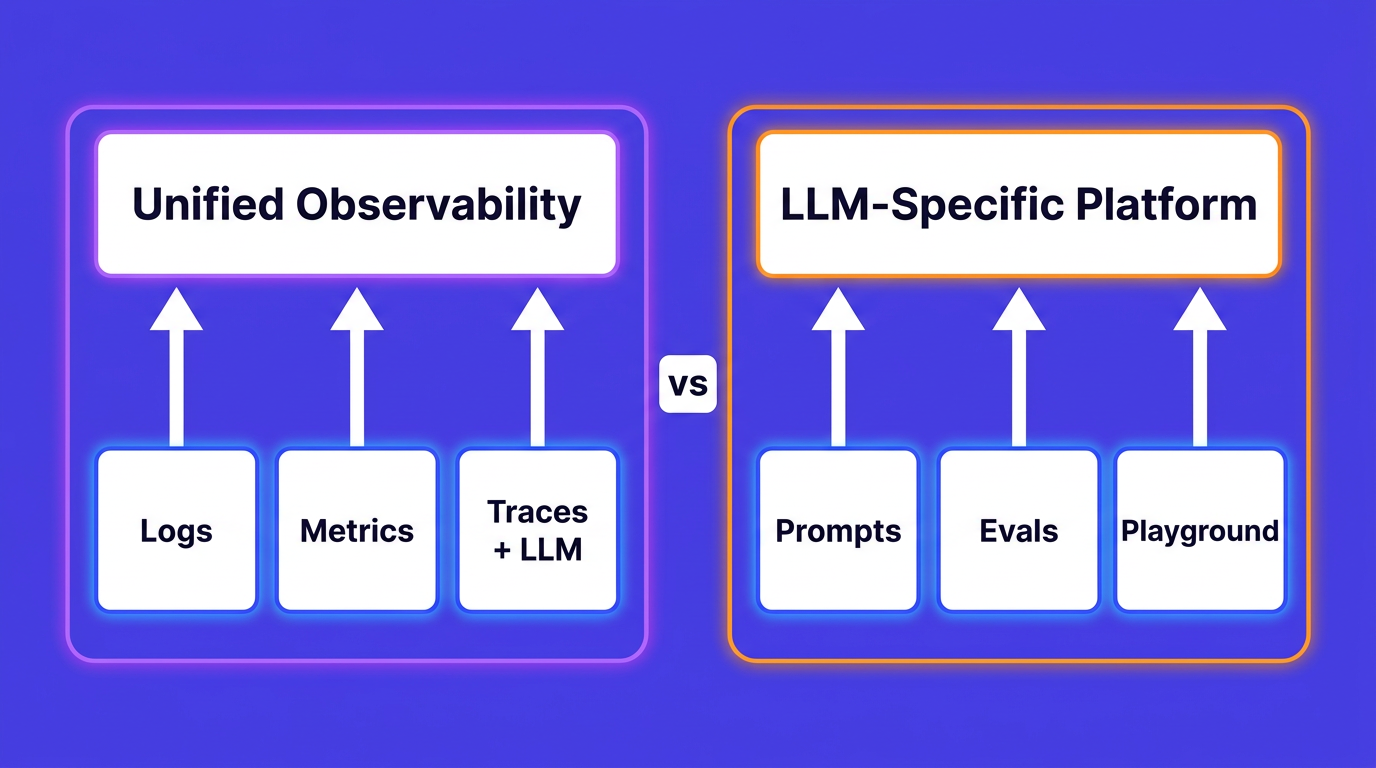
This is what I mean when I talk about replacing fragmentation with a single, high-performance platform. Logs, metrics, traces, RUM, pipelines, visualization, incident management, anomaly detection, AI SRE, and LLM observability: one interface, one data layer, one team that can actually understand what their systems are doing.
The $10M Series A gives us the resources to scale what's already working. We're expanding our go-to-market motion, building out our customer success team, and supporting a growing enterprise base that needs more than just great software. They need a partner.
We've also expanded our infrastructure footprint with new regional availability in the US West and the European Union, added Microsoft Azure as a hosting option, and welcomed Shani Shoham as our Chief Revenue Officer to lead our commercial expansion.
I'm grateful to Abhishek Sharma at Nexus Venture Partners and Deepak Jeevankumar at Dell Technologies Capital for their continued conviction. Both of them led our seed round. They've watched us build this from early architecture decisions to Fortune 10-scale deployments. Their decision to lead this round preemptively reflects what I hope we've earned: a reputation for building something real and shipping it.
The vision I've always had for OpenObserve is what I'm calling Observability 3.0: a world where engineering teams aren't firefighting, they're building.
Observability 1.0 was about collecting data. Observability 2.0 was about making that data queryable and visual. Observability 3.0 is about having the system understand that data on your behalf — identifying problems before they become incidents, routing signals to the right places, and taking action autonomously.
The companies that adopt this operating model first will ship faster. They'll sleep better. They'll have a compounding advantage over teams still manually triaging issues across a stack of disconnected tools.
We're not trying to be a better version of what exists. We're trying to make what exists irrelevant.
Today's announcements are a meaningful step toward that. But honestly, for us, this is still early.
To learn more about Observability 3.0 or request a demo, visit openobserve.ai/observability-3. Follow along at @OpenObserve.
Prabhat Sharma is the founder of OpenObserve, bringing extensive expertise in cloud computing, Kubernetes, and observability. His interests also encompass machine learning, liberal arts, economics, and systems architecture. Outside of work, Prabhat enjoys spending quality time playing with his children.