AI-First, For Real: How We Turned Engineering Bottlenecks Into Agents at OpenObserve

Shrinath Rao
July 01, 2026
11 min read
Don’t forget to share!
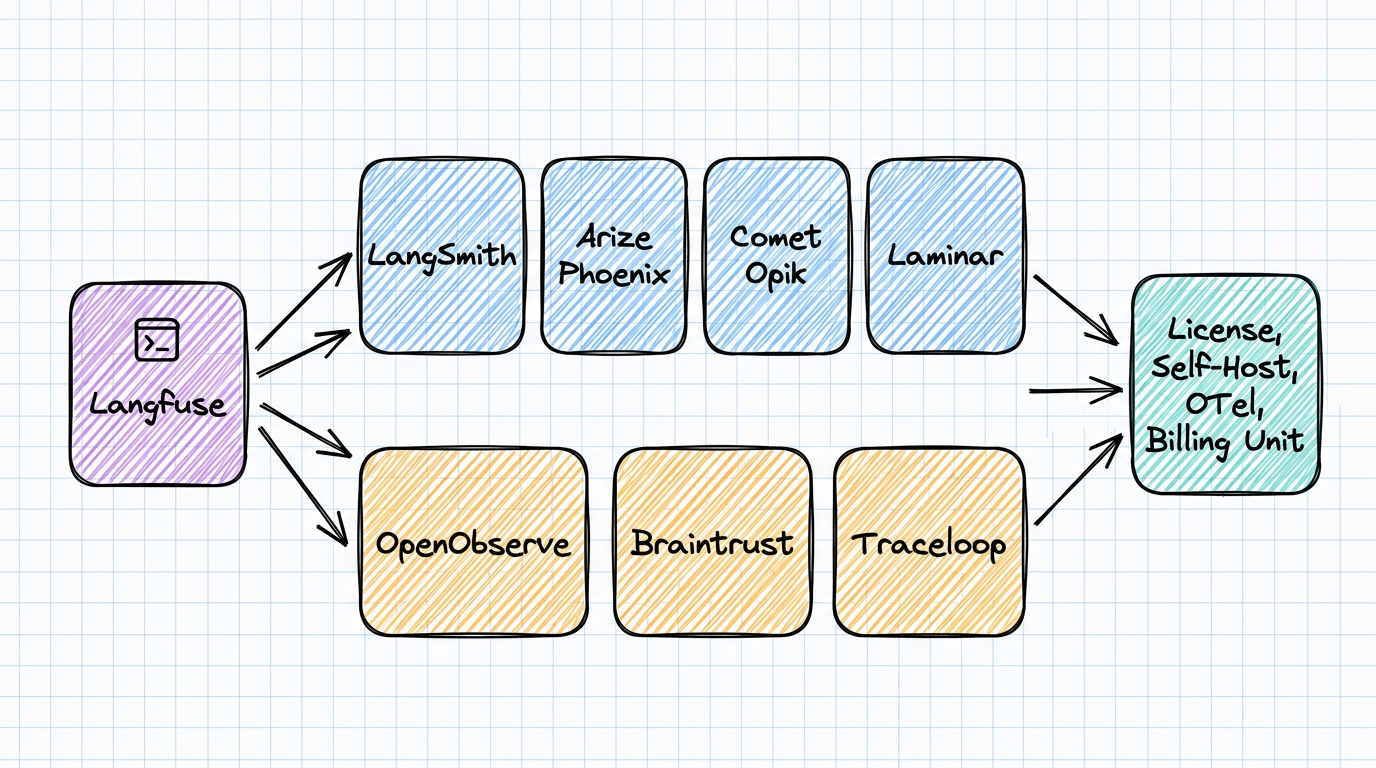
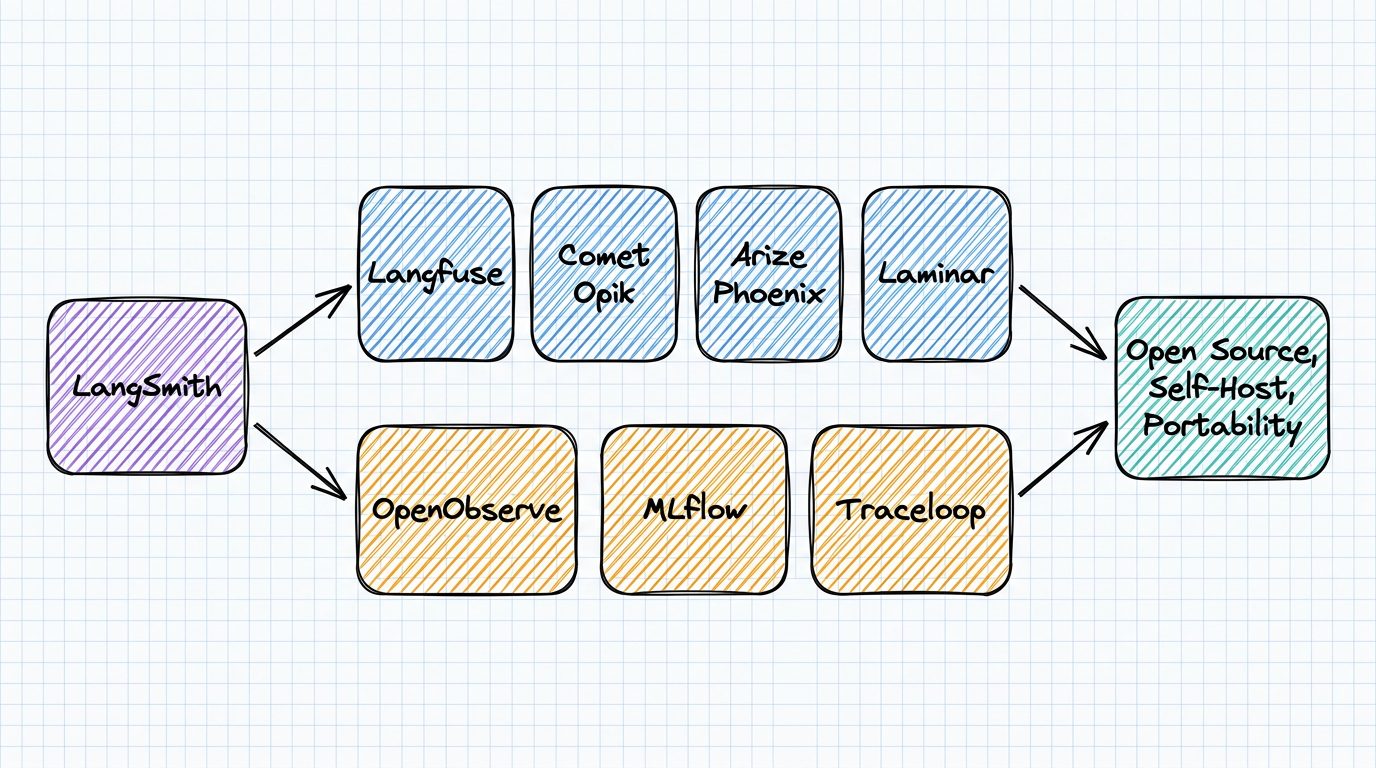
Getting Started with OpenObserve
Try OpenObserve Cloud today for more efficient and performant observability.
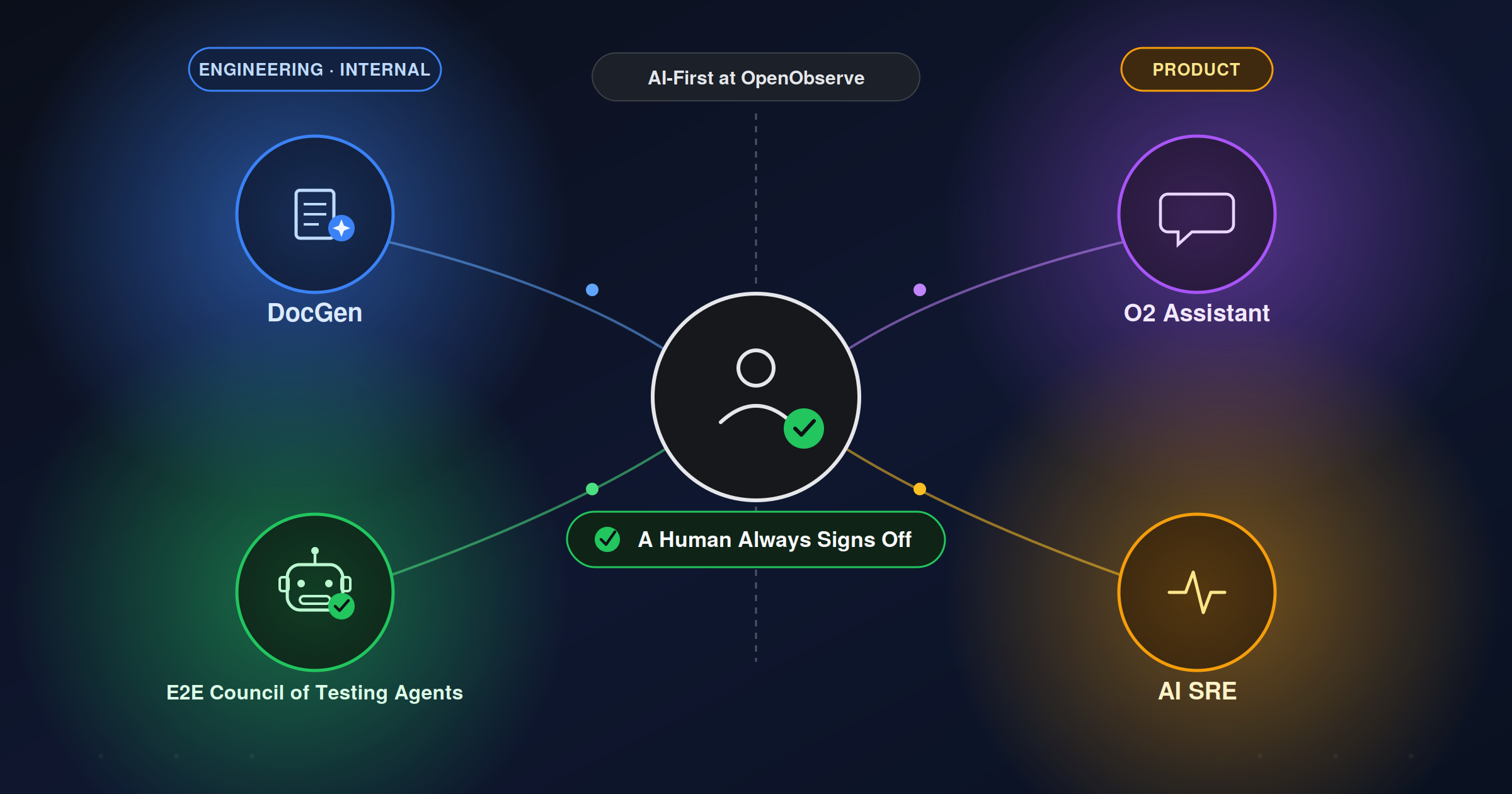
"AI-first" is easy to say on a landing page. We'd rather show it. OpenObserve already ships two AI features for our users, O2 Assistant (Beta) and the AI SRE (Beta), that hand off the tedious parts of running observability to an agent. We run our own engineering shop the same way. We built DocGen, which writes our documentation, and the Council of Agents, which writes and heals our end-to-end tests, a few months ago. What's new is the past couple of weeks: moving both out of "a human runs this locally" and into CI, where they now fire on their own. Same instinct, different side of the product: give an agent enough access to actually do the tedious work instead of asking a human to grind through it.
Every engineering team ships fast, and the two things that always fall behind feature velocity are documentation and test coverage. Not because nobody cares. Writing docs and writing tests are exactly the kind of work that's tedious and repetitive, the kind that quietly eats hours you'd rather spend on the feature itself, the next hard problem, or something you've been wanting to build for a while.
So instead of asking people to grind through that busywork by hand, we built agents that do it for us. We're hiring, and the team is growing, but the point isn't "we don't have enough people," it's that the tedious parts of the job don't have to be a person's job at all. Free that time up, and everyone gets to spend more of it on work that's actually meaningful: real feature work, real debugging, real product thinking.
That's the real meaning of "AI-first" for us. Not "we use an LLM somewhere," but handing the repetitive chores to agents so the humans on the team can focus on the parts of the job that actually need a human.
Every feature ships with a pull request. Almost none of them ship with a documentation page, because the person who best understands the feature (the developer) is also the person least likely to sit down and write end-user prose about it. Docs lag weeks behind, or never show up.
DocGen closes that gap. When a feature PR is opened, an engineer comments /docgen on it, and an agent:
Crucially, it never decides what becomes official documentation on its own. The draft lands in a holding folder and opens as a pull request, ready for reviewers to go through. From there it goes through multiple layers of human review, not just one glance: a docs reviewer reads it for accuracy and tone, and an engineer sanity-checks the technical claims, before anyone hits merge. The agent does the first 80% of the work; people still make every call after that.
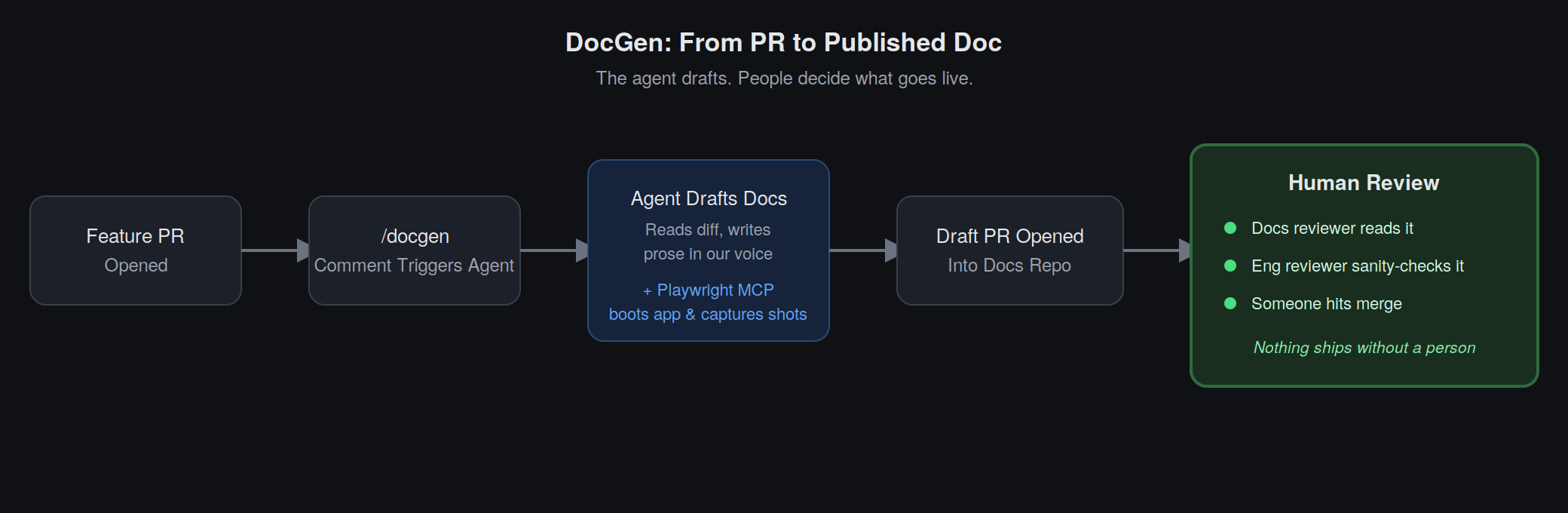
I started DocGen as a local tool, a Claude Code skill I'd run by hand on my own laptop. It worked well enough as a proof of concept that moving it into CI felt like the natural next step. Once it could run on its own, documentation stopped being something I had to personally sit through and turned into something I could hand off entirely. That freed up real time to explore other automation ideas and build things I'd otherwise never get to.
Here's what that looks like on an actual PR. The agent triages the change first, in plain language, before writing anything: what it thinks needs documenting, which edition it applies to, and why. Then it comes back once the docs PR is actually open, with a direct link for a human to review.
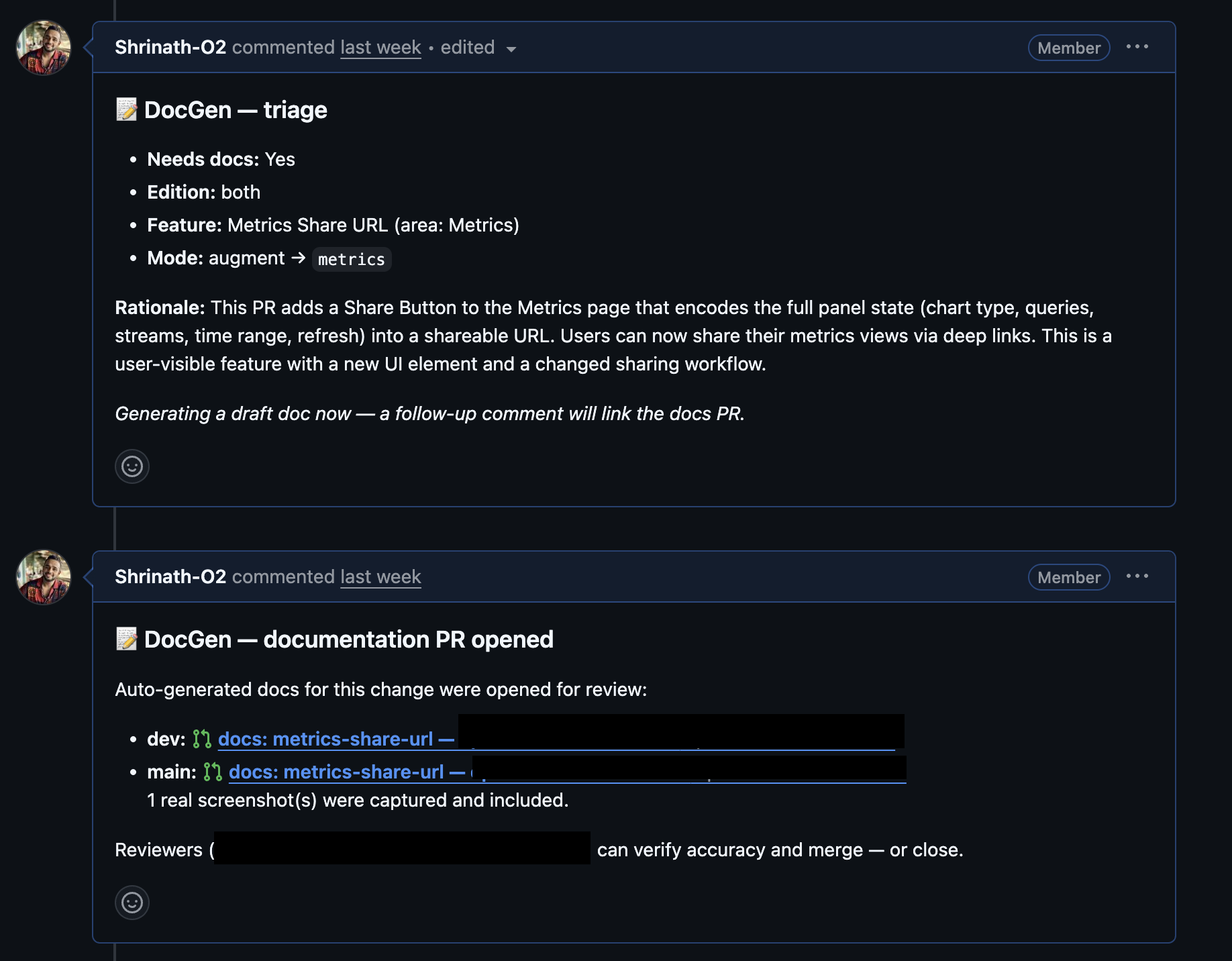
Here's where it got genuinely interesting. When DocGen was first built, screenshots in the draft doc were just placeholders, something like [TODO: screenshot of the service graph], and a human had to go take the real shot. Fine, but exactly the kind of manual handoff we were trying to eliminate.
The fix sounds almost impossible. To take a real screenshot of a feature, you need a running, populated copy of the product, and something that can click through it like a person would, from a cold start, inside a CI job.
Playwright MCP is what dissolves that problem. It's a small piece of tooling that hands an AI agent real browser control (navigate, click, type, screenshot) as tools it can call. Give an agent that, plus a shell, and it stops describing your software and starts using it.
So today, DocGen's screenshot step actually:
We proved this on the hardest case we had: a service-dependency graph that doesn't exist until the system has ingested correlated traces across several services and a background job has had time to build the map. The agent posted the trace data itself, waited for the graph to render, and photographed a real seven-node graph. The doc was born with real screenshots already in it.
I've written before about the Council of Agents, the pipeline of specialized agents that analyzes a new feature, plans tests for it, writes the Playwright code, audits that code, and then keeps fixing it until the tests actually pass. It used to be something I ran by hand, watching over its shoulder. Now it runs the same way DocGen does: an engineer comments /e2e on a feature PR, and the pipeline takes it from there.
The part that makes this trustworthy rather than reckless: nothing gets called "passing" because an AI said it passed. A real, live copy of OpenObserve is built and booted from the actual PR's code, the generated tests are run against it for real, and only an honest green run gets to open a test PR. If a test can't be made to pass honestly, it's flagged for a human, never quietly weakened to force a green checkmark. And even an honest green run doesn't ship itself: the resulting test PR still goes through the same human review process as any other code, someone actually reads it before it merges.
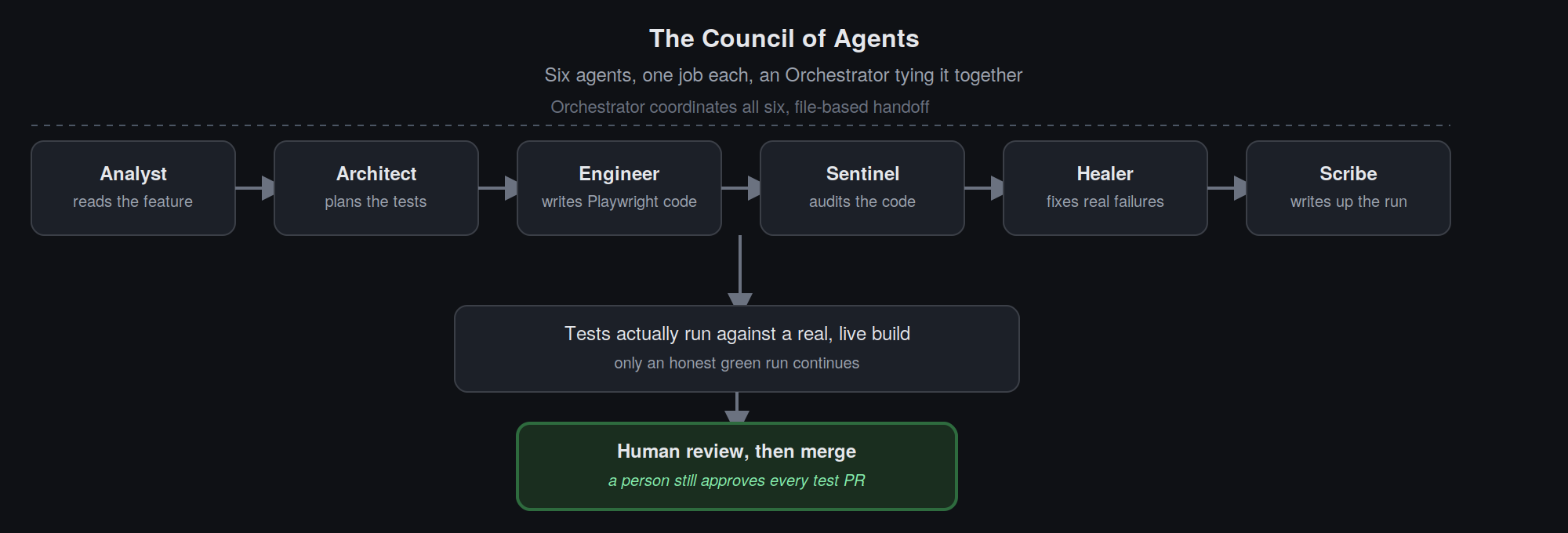
The payoff has been concrete: feature analysis that used to take most of an hour now takes minutes, our flaky-test count dropped by 85%, and our coverage grew by more than 80% without a proportional increase in QA headcount. Along the way, the Council also did something we didn't ask for. While simply writing tests for a new feature, it caught a silent bug already live in production, a URL-parsing mistake in a ServiceNow integration that was quietly failing for every customer using it, before a single one had reported it. Writing tests turned into finding a real, unreported outage.
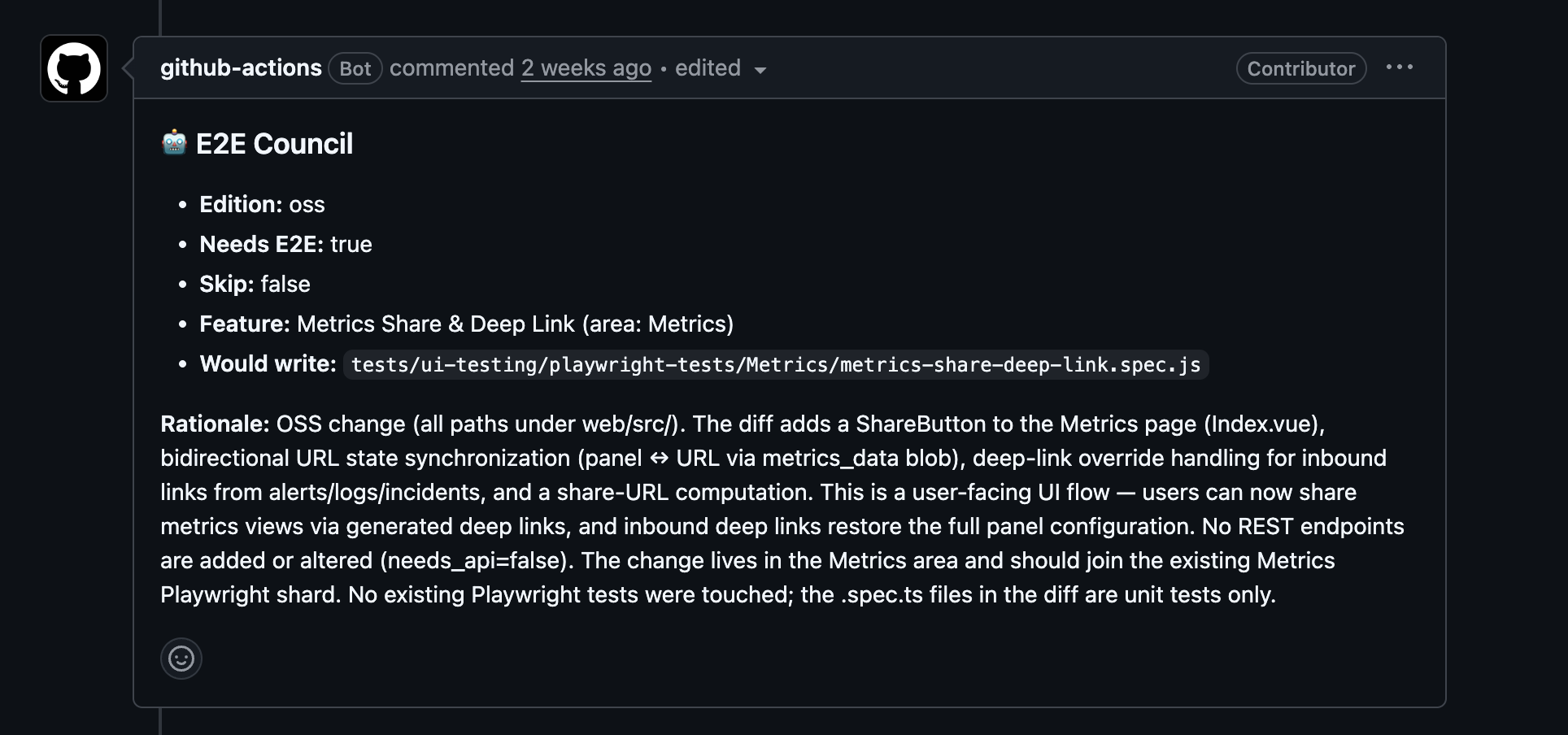
Same as DocGen, the Council shows its reasoning on the PR before it writes a single line of test code: which edition the change touches, whether e2e coverage is actually needed, and where the resulting spec file would live, along with the reasoning behind all of it.
Zoom out for a second and the parallel gets pretty obvious. O2 Assistant (Beta) is a chat copilot built into OpenObserve. You ask it for what you want, a query, a dashboard, an alert, an explanation of why something fired, in plain English, and it produces the real thing. The AI SRE (Beta) does the same for incidents: when something breaks, it can dig through the logs, traces, and alerts around it on its own and explain why, the way an on-call engineer would, then keep working the incident as it evolves.
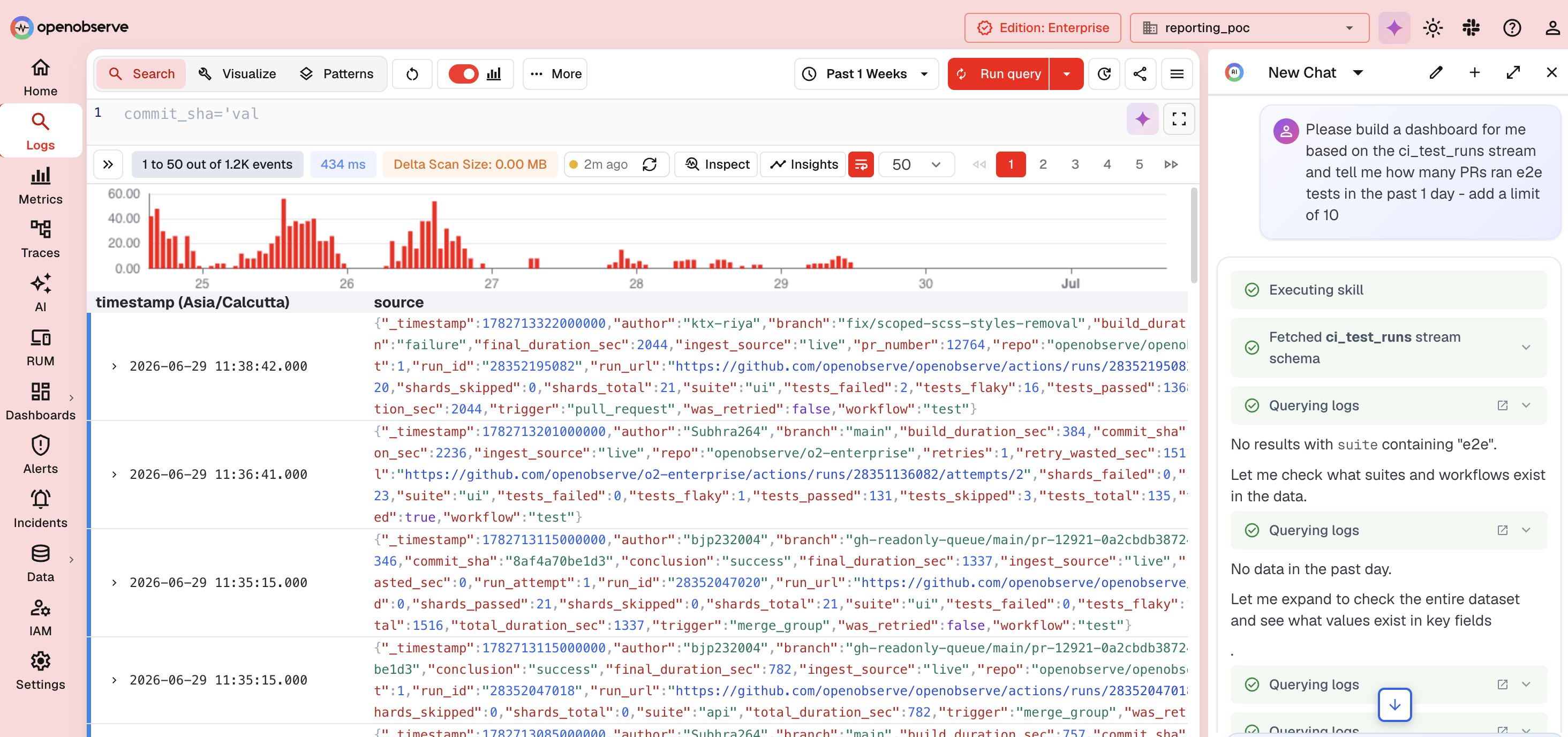
Here's what that actually looks like. Someone asked O2 Assistant to build a dashboard from our own ci_test_runs stream and report how many PRs ran e2e tests in the last day. It queried the logs itself, checked what fields and values actually existed in the data rather than guessing, noticed there were no e2e suites in that window, said so plainly, and then went ahead and built the dashboard anyway, panel by panel, narrating each step as it went.
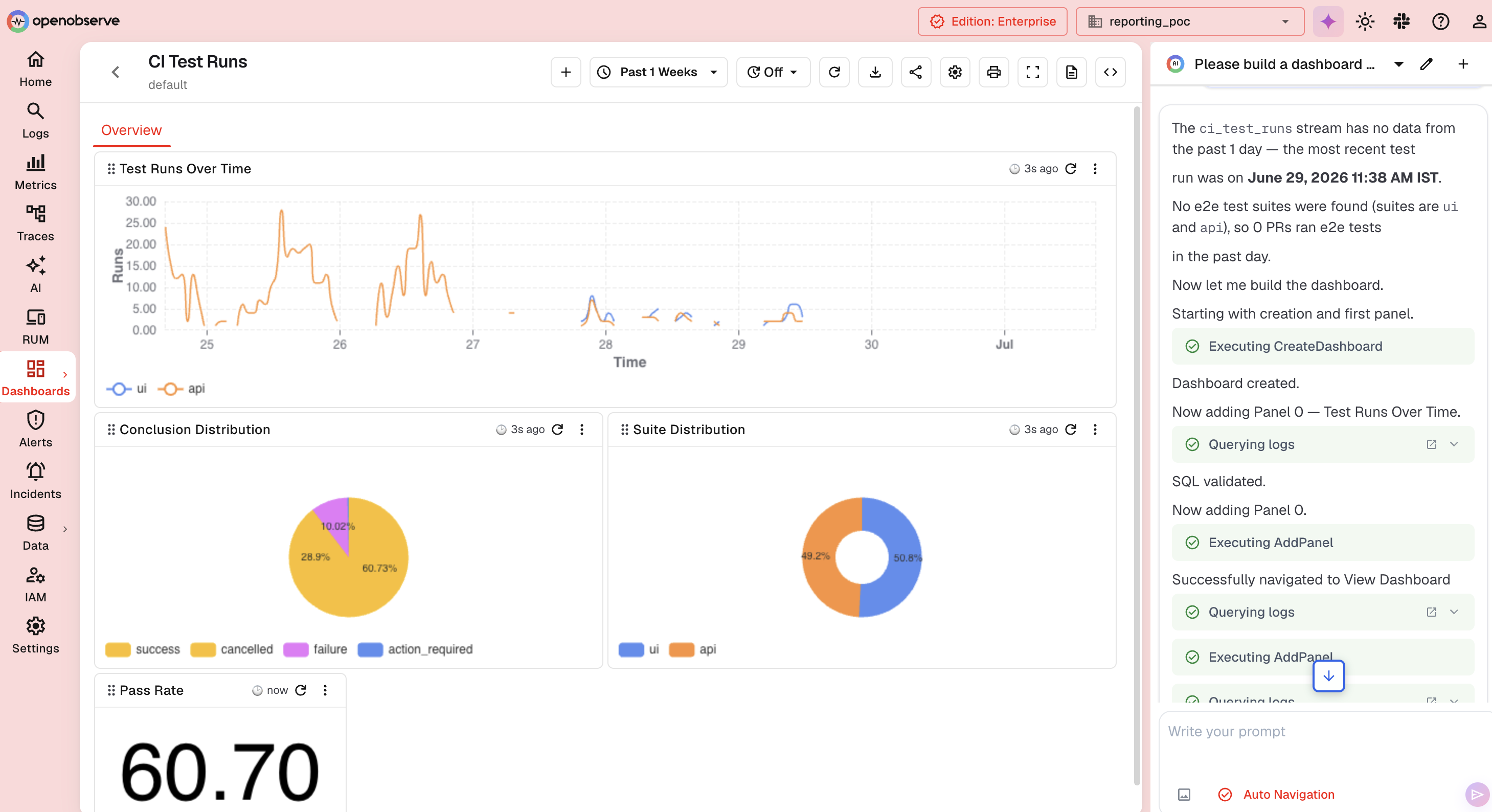
That same conversation is grounded in the real underlying data the whole time, not a canned response. You can see it pulling directly from the ci_test_runs logs, checking field values like suite before drawing conclusions, and being upfront when a query comes back empty instead of quietly fabricating something that looks plausible.

Put next to DocGen and the Council, the shape of the idea repeats. One pair helps our users get through observability busywork faster. The other pair helps us get through engineering busywork faster. Different audience, same move: stop asking a person to grind through tedious, repetitive work, and give an agent enough real access to actually do it.
That's what "AI-first" means to us in practice. It shows up in how we build the product, and it shows up inside the product itself.
Notice the pattern running through everything above: in every case, the win didn't come from an AI talking about the work. It came from giving the agent enough access to actually do it: a browser, an ingestion API, a real running instance of the product, a real test runner. An agent that can only comment on your work is an assistant. An agent that can build, seed, click, and verify your work is something closer to a teammate.
But notice the other pattern too: at no point does an agent get the final word. Every doc DocGen drafts and every test the Council writes goes through multiple human reviews before it ships, and the same is true of how we think about O2 Assistant and the AI SRE: they do the legwork, a person still signs off. That's not a limitation we're working around, it's the whole point. It's what lets us hand off this much work without worrying about getting it wrong in front of users.
That's the bar we hold both halves of this story to: the agents that build OpenObserve, and the agents living inside it.
Want to see O2 Assistant (Beta) and the AI SRE (Beta) in action, or curious how we build agentic workflows into OpenObserve itself? Talk to us at hello@openobserve.ai. We're always happy to walk through how any of this works, in the product or behind the scenes.
Join the conversation in our community Slack.
Try OpenObserve, built by a team that uses AI to move fast without losing quality, for a product built to help you do the same. Get started in the cloud or download it.
Watch the Council in action — building an autonomous QA team with subagents:
Shrinath Rao is Lead QA Engineer at OpenObserve, running QA through an AI-driven operating model. He architects autonomous testing systems using Claude Code and AI sub-agents for analysis, validation, and release workflows. With 9+ years in automation-first testing across observability and enterprise platforms, he's an active code contributor who embeds AI capabilities into CI/CD pipelines to strengthen quality engineering