How to Redact PII from LLM Telemetry Without Losing Debuggability

Simran Kumari
June 24, 2026
14 min read
Don’t forget to share!
What Nobody Tells You About Running AI in Production
Try OpenObserve Cloud today for more efficient and performant observability.

You push an LLM feature to production. Something breaks: a hallucination, a bad retrieval result, an unexpected refusal. You open a trace in OpenObserve and see exactly what you need:
gen_ai.prompt: "My name is Alex Johnson, DOB 1990-03-22, SSN 412-73-9021.
I need help with my insurance claim."
Two things are true at once. This trace is exactly what you need to root-cause the failure. And storing it verbatim is a compliance liability under GDPR Article 5, HIPAA minimum-necessary, CCPA, and most enterprise data governance policies.
Most teams handle this badly. They either log everything and cross their fingers, or they redact so aggressively that traces become useless. Both paths are wrong. There is a third option: structured, metadata-preserving redaction that keeps your security team satisfied and your on-call engineer functional at 2 a.m.
This post covers how to implement that using OpenObserve's native capabilities: Sensitive Data Redaction (SDR), VRL pipelines, and the OTel Collector. The approaches build on each other and you can adopt them incrementally.
Before getting to solutions, it helps to be specific about what you lose with naive redaction.
Token count drift is the most common silent failure. If your prompt had 412 tokens before scrubbing and 409 after, your latency-per-token attribution is now wrong. Small, but aggregated across thousands of requests it makes cost dashboards unreliable in ways that are hard to trace back.
Context length blindness is worse. Did the input push close to the model's context window? Was truncation the reason for the bad response? A raw character count replacement wipes out this signal entirely.
Cross-span correlation breaks when you need it most. In OpenObserve, you can pivot from a trace span to its correlated log stream using trace_id. If both your /chat span and your /rag_retrieval span contained "Alex Johnson" and now both say [REDACTED], you have lost the ability to confirm they were talking about the same person. The join key is gone.
Named Entity Recognition (NER) false positives are a separate headache. Generic named-entity models misfire constantly on LLM workloads. "GPT-4" gets tagged as a person name. "Chicago" in "Chicago Manual of Style" gets masked as a location. Every false positive makes traces harder to read and erodes trust in the tooling over time.
The goal is not to log less. It is to log smarter.
OpenObserve gives you three places to intercept and redact PII, each with different tradeoffs:
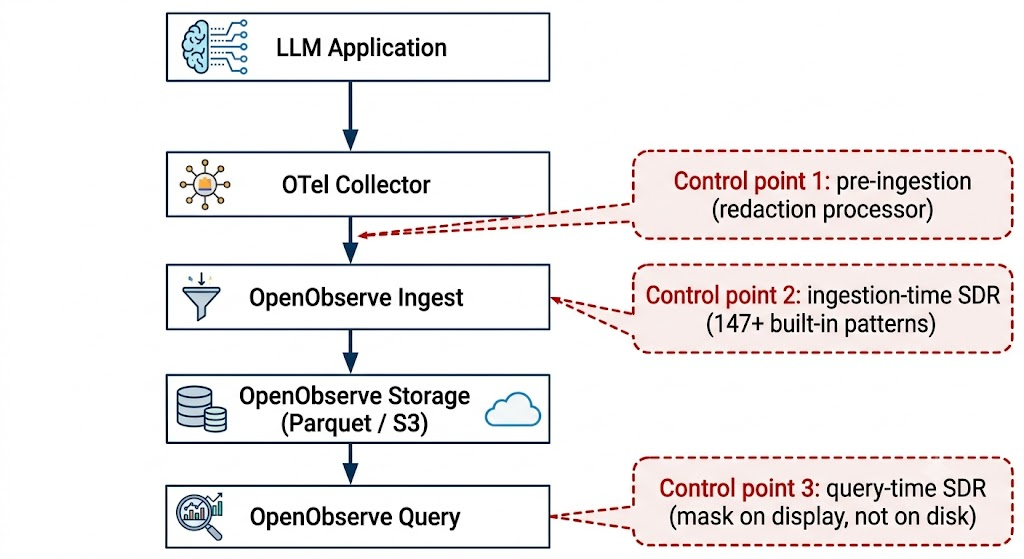
Each control point fits a different compliance posture:
Many teams use all three together. The Collector handles critical PII in transit, ingestion SDR covers regulated identifiers, and query-time SDR controls what different roles can see.
If you are sending LLM traces to OpenObserve Cloud, or any remote backend, the Collector is your first line. The redaction processor runs before the exporter, so sensitive prompt content never leaves your network perimeter.
# otel-collector-config.yaml
receivers:
otlp:
protocols:
grpc: { endpoint: 0.0.0.0:4317 }
http: { endpoint: 0.0.0.0:4318 }
processors:
redaction:
allow_all_keys: true
blocked_key_patterns:
# Redact values of LLM span attributes containing prompt/completion content
- "gen_ai\\.prompt"
- "gen_ai\\.completion"
- "llm\\.prompts"
- "llm\\.completions"
summary: debug # Writes a count of redacted fields into span metadata
memory_limiter:
limit_mib: 1500
spike_limit_mib: 512
check_interval: 5s
batch: {}
exporters:
otlphttp/openobserve:
endpoint: https://api.openobserve.ai/api/YOUR_ORG
headers:
Authorization: "Basic <base64(email:password)>"
service:
pipelines:
traces:
receivers: [otlp]
processors: [redaction, memory_limiter, batch]
exporters: [otlphttp/openobserve]
metrics:
receivers: [otlp]
processors: [memory_limiter, batch]
exporters: [otlphttp/openobserve]
logs:
receivers: [otlp]
processors: [batch]
exporters: [otlphttp/openobserve]
The summary: debug setting writes a redaction.redacted.keys attribute to each span with a count of what was removed. OpenObserve receives the signal that PII was present without receiving the content. You can query that:
SELECT trace_id, service_name, "redaction.redacted.keys"
FROM default
WHERE stream_type = 'traces'
AND "redaction.redacted.keys" > 0
AND "gen_ai.system" IS NOT NULL
ORDER BY _timestamp DESC
LIMIT 100
For data reaching OpenObserve directly (self-hosted deployments, or telemetry that skips an external Collector), the built-in Sensitive Data Redaction engine is the right tool. SDR is an Enterprise feature.
SDR inspects field values the moment data arrives and applies one of three actions before writing to storage.
Redact replaces the matched portion with [REDACTED], leaving the rest of the field intact. Useful when a field contains both sensitive and non-sensitive content and you want to retain context for debugging.
Hash replaces the matched value with a deterministic MD5 hash: [REDACTED:907fe4882defa795fa74d530361d8bfb]. The value is unreadable, but because the same input always produces the same hash, you can still trace repeated occurrences across spans and logs without accessing the original. To search by hash later, use the match_all_hash() function in OpenObserve: match_all_hash('alex.johnson@example.com'). This works on fields where full-text search is enabled; turn that on for any field using SDR with hashing.
Drop removes the field entirely before storage. Use this for regulated identifiers (SSNs, PHI, payment card numbers) where even a hash creates compliance exposure.
OpenObserve ships with 147+ built-in patterns covering email addresses, phone numbers, physical addresses, SSNs, passport numbers, credit card numbers across all major networks, API keys, AWS credentials, and IP addresses.
To configure SDR for your LLM trace stream, go to Management > Sensitive Data Redaction in the OpenObserve UI. Create your regex patterns there, then attach them to specific fields via Streams > Stream Details > Schema Settings > Add Pattern. You select the field (for example, gen_ai_input_messages), pick the pattern, choose Redact, Hash, or Drop, and set whether it applies at ingestion, query time, or both.
One constraint worth knowing: patterns can only be applied to fields with a UTF8 data type, and the stream must have ingested data before fields appear in the schema settings. If you are setting this up on a new stream, ingest a few test events first.
Why hash over redact for most LLM fields? Because hashing preserves correlateability. If the same email address appears in a user's /chat span, the subsequent /rag_retrieval span, and an application log, all three will contain the same hash. In OpenObserve you can use that hash as a join key across telemetry types to reconstruct a full user journey without exposing the underlying identity:
SELECT
t.trace_id,
t.service_name,
t."gen_ai.usage.input_tokens",
l._timestamp,
l.log_level,
l.message
FROM traces t
JOIN logs l ON t.trace_id = l.trace_id
WHERE t."gen_ai.prompt" LIKE '%[REDACTED:a3f7c91b2d04]%'
ORDER BY l._timestamp ASC
For the open-source edition of OpenObserve, or for cases where you need transformation logic that goes beyond pattern matching (preserving metadata, conditional routing, custom pseudonymization), VRL (Vector Remap Language) pipelines give you full control.
The key idea is to replace content with structure. Strip the sensitive value, but preserve the metadata that makes the trace useful.
# Preserve original length before redaction — critical for token attribution
.gen_ai_prompt_original_chars = length!(.gen_ai.prompt)
# Redact emails
email_pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
.gen_ai.prompt = redact!(.gen_ai.prompt, filters: [email_pattern], redactor: "full")
# Redact phone numbers (10-digit)
phone_pattern = r'\b\d{10}\b'
.gen_ai.prompt = redact!(.gen_ai.prompt, filters: [phone_pattern], redactor: "full")
# Track how much was redacted
.gen_ai_prompt_redacted_chars = length!(.gen_ai.prompt)
.gen_ai_prompt_pii_chars_removed = .gen_ai_prompt_original_chars - .gen_ai_prompt_redacted_chars
For a prompt like "My email is alexander.johnson@acme.com, phone 9876543210. I need help with my insurance claim.", after this pipeline runs, your span in OpenObserve looks like:
{
"gen_ai.prompt": "My email is [REDACTED], phone [REDACTED]. I need help with my insurance claim.",
"gen_ai_prompt_original_chars": 94,
"gen_ai_prompt_redacted_chars": 78,
"gen_ai_prompt_pii_chars_removed": 16
}
You can still answer: was this an unusually long prompt? Did redaction significantly change the apparent context length? Is there a correlation between prompts with high pii_chars_removed and hallucination rates?
gen_ai_input_messages — the field most teams missIf you are using LangChain, LlamaIndex, or the OpenAI SDK, the full conversation history lands in a field called gen_ai_input_messages as a JSON array serialized to a string. This field is dangerous because it contains both user PII and your internal system prompt. Both leak into storage if you do not handle it explicitly.
VRL's for_each and map_values closures do not accept array elements, and variable-based array indexing (messages[i]) is not supported. The while keyword is reserved. The approach that actually works in OpenObserve's VRL implementation is to operate on the raw JSON string directly using replace():
if exists(.gen_ai_input_messages) {
s = string!(.gen_ai_input_messages)
# Redact phone numbers (10-digit)
s = replace(s, r'\b\d{10}\b', "[PHONE_REDACTED]")
# Redact email addresses
s = replace(s, r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b', "[EMAIL_REDACTED]")
.gen_ai_input_messages = s
}
replace() applies each regex globally across the entire serialized string, so it catches PII in any message object in the array regardless of position. No parsing required, no closure type errors.
Here is a concrete example of what this does.
Before the pipeline runs, OpenObserve receives:
{
"gen_ai_input_messages": "[{\"role\":\"system\",\"content\":\"You are a helpful assistant.\"},{\"role\":\"user\",\"content\":\"My name is Alex, my phone number is 9876543210, I need some help\"}]"
}
After the VRL pipeline:
{
"gen_ai_input_messages": "[{\"role\":\"system\",\"content\":\"You are a helpful assistant.\"},{\"role\":\"user\",\"content\":\"My name is Alex, my phone number is [PHONE_REDACTED], I need some help\"}]"
}
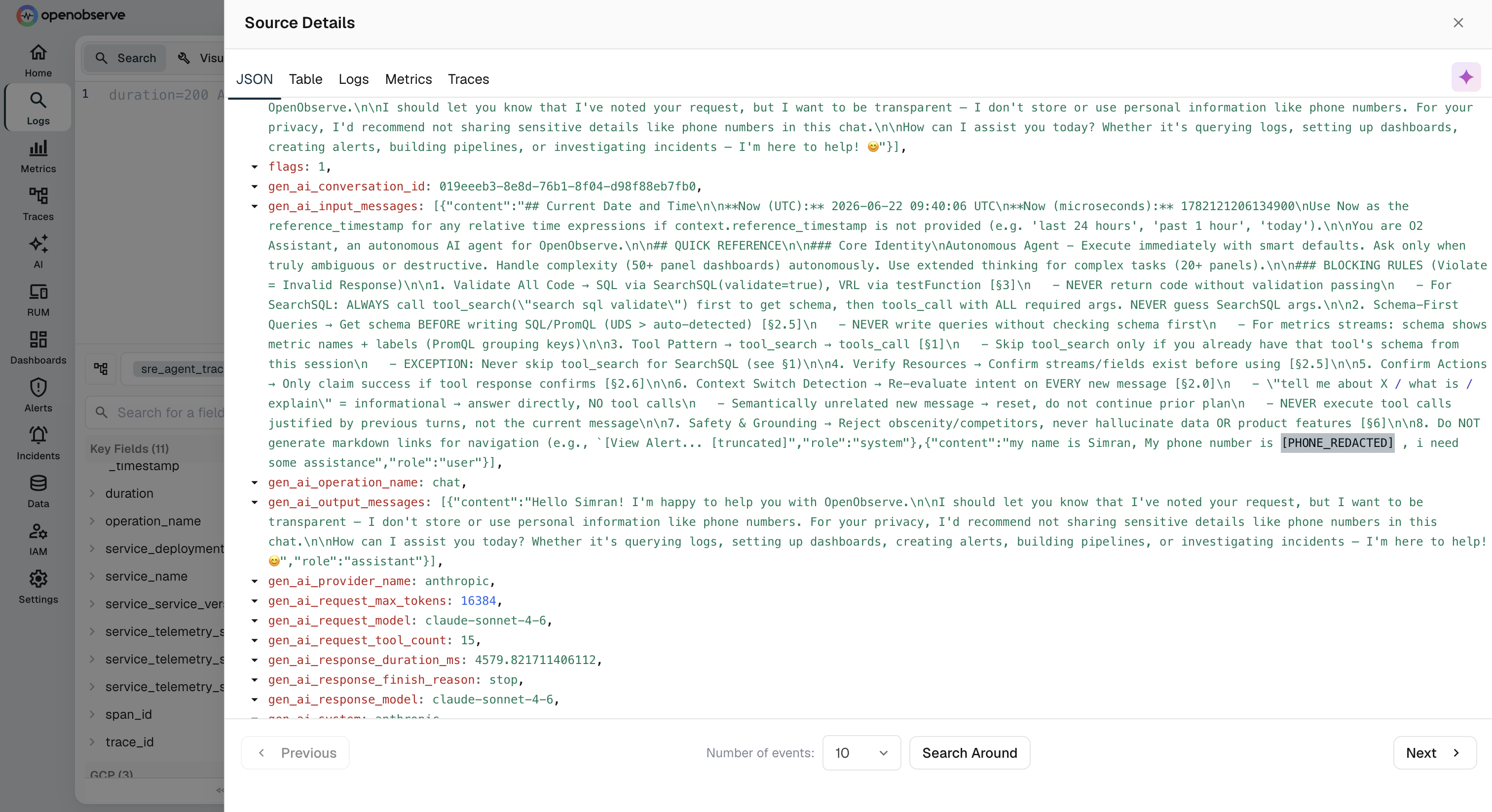
The user's first name stays (low sensitivity, useful for debugging). The phone number is gone. You still have enough context to understand what kind of request this was and debug a bad response.
If you also need to redact system prompt content, note that gen_ai_input_messages is a serialized JSON string whose key ordering varies by SDK and framework version. A regex targeting "role":"system","content":"..." will silently fail if the serializer writes "content" before "role", or if it adds whitespace between keys. Before shipping any system-prompt regex to production, pull a raw sample from your actual trace stream in OpenObserve and verify the pattern matches your payload shape.
# Deterministic pseudonym for user identity
# The same user_id always produces the same pseudonym within a key rotation period
if exists(.user_id) {
.user_pseudonym = sha256(string!(.user_id) + "${PSEUDO_SALT}")
del(.user_id)
}
if exists(.user_email) {
.user_pseudonym = sha256(string!(.user_email) + "${PSEUDO_SALT}")
del(.user_email)
}
Every span and log emitted by the same user now carries the same .user_pseudonym. You can query across them in OpenObserve without ever touching the underlying identity:
SELECT
_timestamp,
service_name,
"gen_ai.operation.name",
"gen_ai.usage.input_tokens",
"gen_ai.usage.output_tokens",
"gen_ai.response.finish_reasons"
FROM default
WHERE stream_type = 'traces'
AND user_pseudonym = 'a3f7c91b2d04e8f91234...'
ORDER BY _timestamp ASC
Rotating PSEUDO_SALT quarterly limits correlation exposure to a 90-day window.
Most teams focus on redacting prompt inputs. Output redaction is more subtle because the model can generate PII it was never given, either hallucinated or inferred from training data.
OpenObserve's LLM observability tracks both input and output token counts, completion content, and finish reasons on gen_ai.* span attributes. Treat output redaction as a separate pipeline stage and add a field that distinguishes echoed PII (present in the input) from generated PII (not present in the input):
# Track PII found in output
completion_email_matches = match_array(.gen_ai.completion, [r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'])
prompt_email_matches = match_array(.gen_ai.prompt, [r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'])
.gen_ai_output_pii_count = length(completion_email_matches)
.gen_ai_output_pii_generated = length(completion_email_matches) - length(prompt_email_matches)
# Redact the completion
email_pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
.gen_ai.completion = redact!(.gen_ai.completion, filters: [email_pattern], redactor: "full")
Set up an alert in OpenObserve on gen_ai_output_pii_generated > 0:
name: "LLM generating novel PII"
stream_type: traces
condition: "gen_ai_output_pii_generated > 0"
threshold: 5 # per 5-minute window
severity: high
channels: [slack-oncall, pagerduty]
A sustained spike in gen_ai_output_pii_generated means your model is producing personal information it was not given. That is both a data governance issue and a model behavior issue worth a separate investigation.
Not all PII in LLM telemetry carries equal risk. A simple tier model helps decide which OpenObserve mechanism to use for each field:
| Tier | Examples | Action |
|---|---|---|
| T0 — Structural | City name, product category, intent label | Log verbatim |
| T1 — Low-sensitivity | First name only, job title | Hash (preserves correlation) |
| T2 — High-sensitivity | Full name + address, date of birth | Redact (placeholder preserves context) |
| T3 — Regulated identifiers | SSN, PHI, payment card, auth tokens | Drop at ingestion; never stored |
Apply T3 drops at ingestion time via SDR. These fields should never reach the Parquet files on your object storage. Apply T2 redaction at ingestion time if you are in a regulated industry; use query-time redaction if you need raw data available for internal audit workflows. Hash T1 to maintain the cross-span correlation that makes LLM debugging tractable.
After implementing redaction, verify you can still answer these questions from OpenObserve without touching the original sensitive values:
| Question | Preserved signal |
|---|---|
| Was this prompt unusually long? | gen_ai_prompt_original_chars |
| Did redaction significantly change the apparent context length? | gen_ai_prompt_pii_chars_removed |
| Did the same user trigger this failure repeatedly? | user_pseudonym (hashed, stable) |
| What types of PII were present in the prompt? | SDR redacted field summary attribute |
| Did the model generate PII it was not given? | gen_ai_output_pii_generated |
| Was retrieval context relevant? | Document IDs and similarity scores, not content |
| Which prompt template produced this output? | template_id and template_version from your instrumentation |
If you can answer all seven from a redacted trace, the strategy is working.
A common mistake is applying the same redaction config everywhere. Local dev with synthetic data does not need T2 redaction; it gets in the way. Staging with production-shape data needs T3 drops only. Production needs the full stack.
OpenObserve's multi-stream architecture makes this straightforward. Use separate stream names per environment (llm_traces_prod, llm_traces_staging) and configure SDR rules per stream. Drive the stream name from deployment.environment in your OTel resource attributes. This is much cleaner than branching it in application code.
Running redaction synchronously in your request path is the most common performance mistake. NER models take 50-200ms. Run redaction in your VRL pipeline at ingest, after the LLM call completes, not in the hot path.
Logging a "sanitized" copy alongside the original is the most common compliance mistake. Even with different access controls on each store, you now have two breach surfaces and a harder audit story. Pick one canonical representation.
Trusting SDR pattern matching alone for gen_ai_input_messages does not work well when the field is a JSON array serialized to a string. SDR operates on the field value as a flat string and will correctly catch PII patterns like emails and phone numbers anywhere in that string. For system prompt content specifically, regex-based redaction over a serialized JSON string is fragile — key ordering, whitespace, and escaping all vary by SDK. Validate any such pattern against real traces from your environment before treating it as reliable.
Redacting PII from LLM telemetry does not have to trade compliance for debuggability. With OpenObserve you have three control points: the OTel Collector for data in transit, ingestion-time SDR for fields that must never be stored unredacted, and query-time SDR for access control without losing the underlying data. VRL pipelines handle the cases SDR cannot, particularly serialized JSON fields like gen_ai_input_messages and structural metadata preservation. Tier your sensitivity, hash where you need correlation, drop where regulations require it, and make gen_ai_output_pii_generated a first-class alert.
Running LLM workloads in production and want to test this against your own traces? Start a free trial — no infrastructure setup, LLM observability available immediately.
Passionate about observability, AI systems, and cloud-native tools. All in on DevOps and improving the developer experience.