MCP Servers for Observability: Connect AI Assistants to Logs, Metrics, and Traces

Manas Sharma
April 24, 2026
8 min read
Don’t forget to share!
What Nobody Tells You About Running AI in Production
Try OpenObserve Cloud today for more efficient and performant observability.

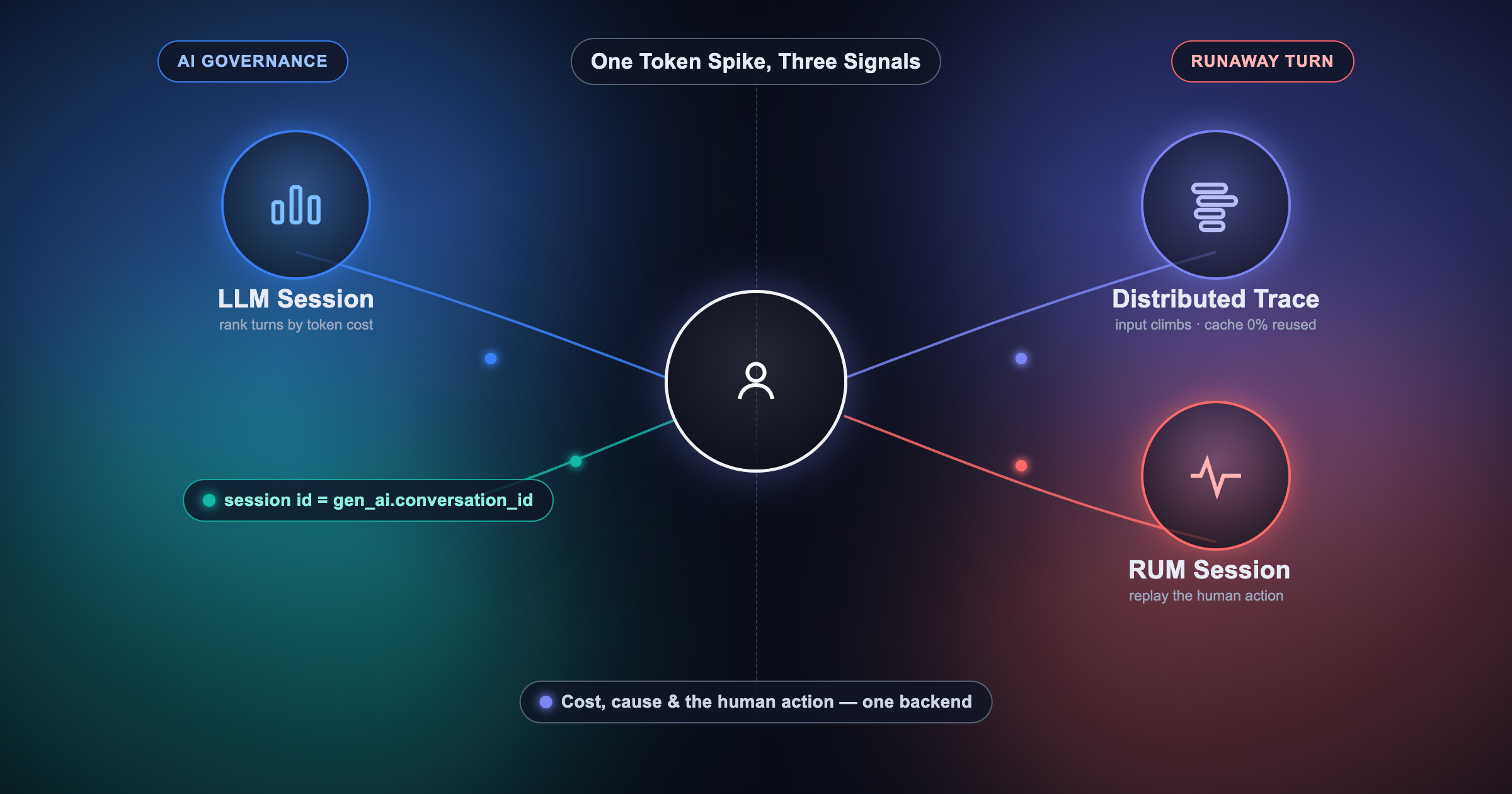
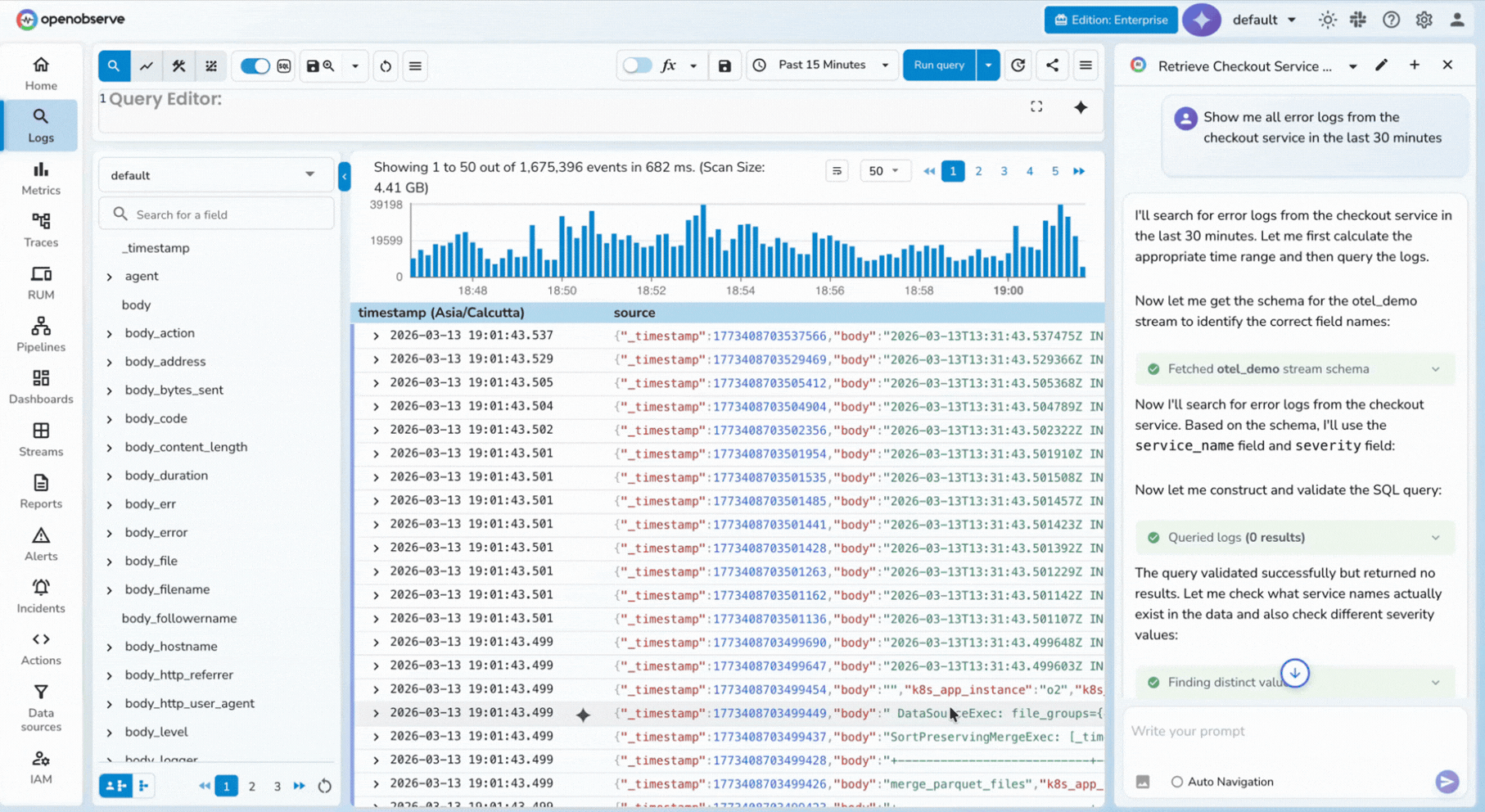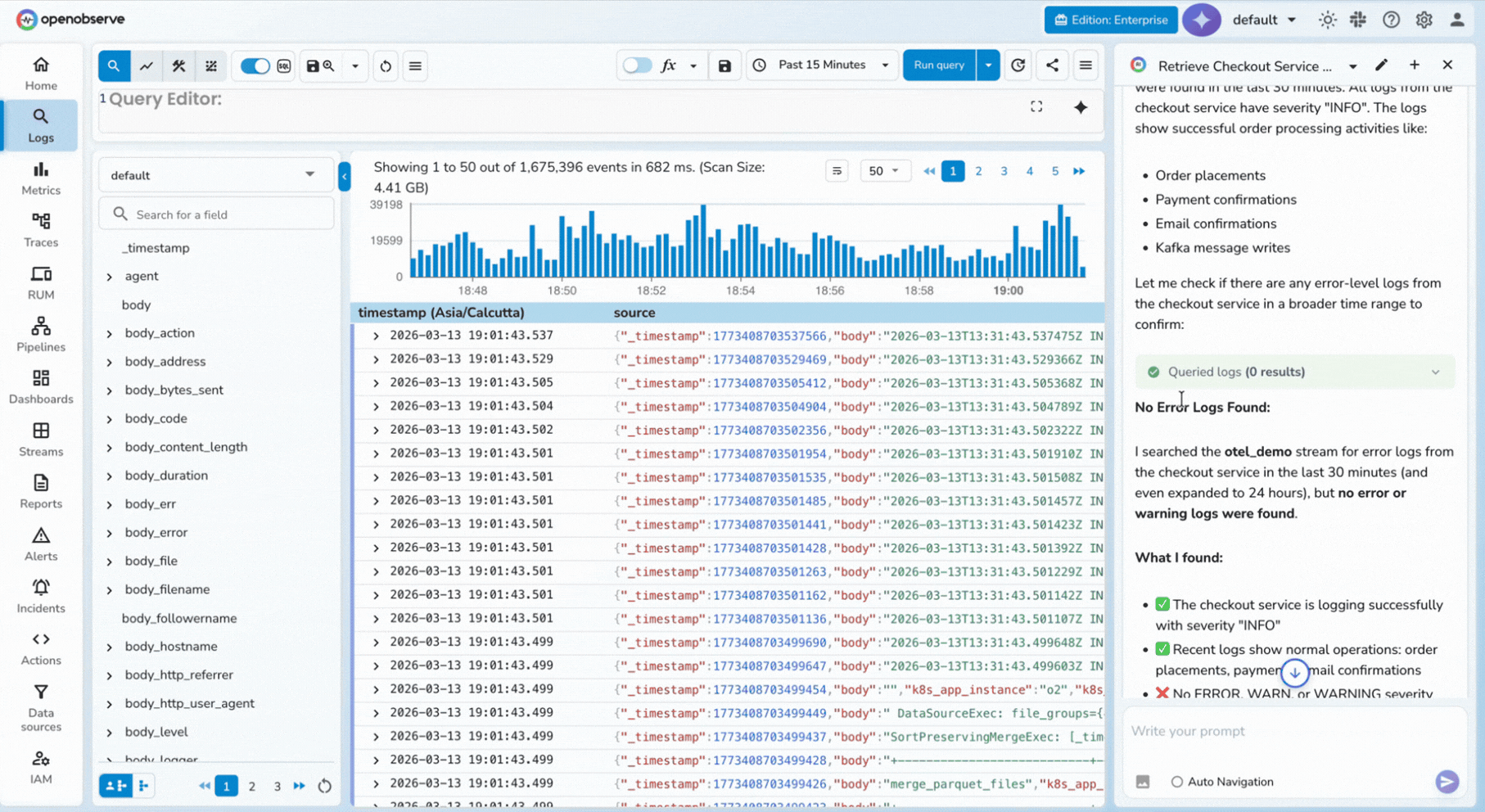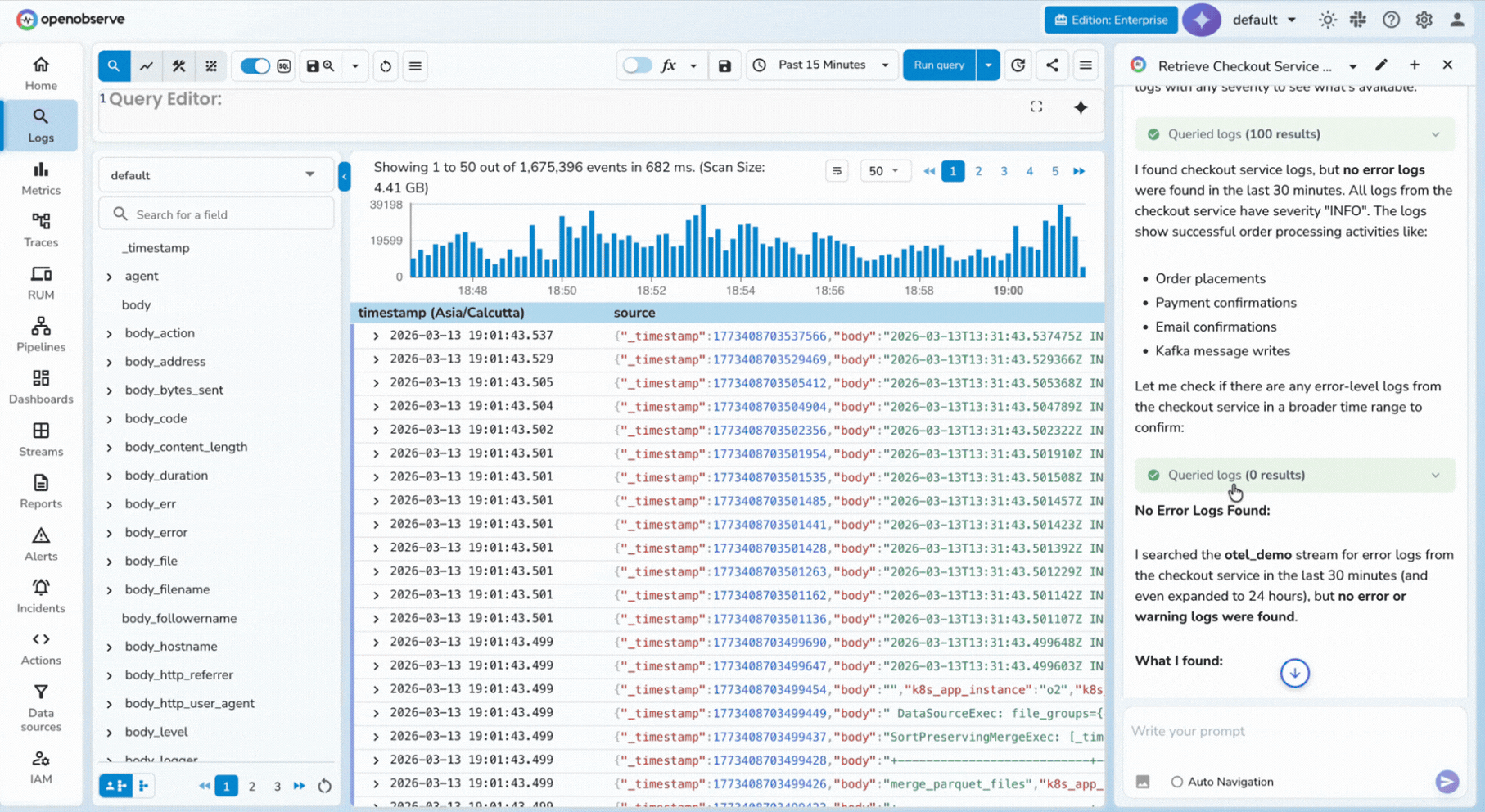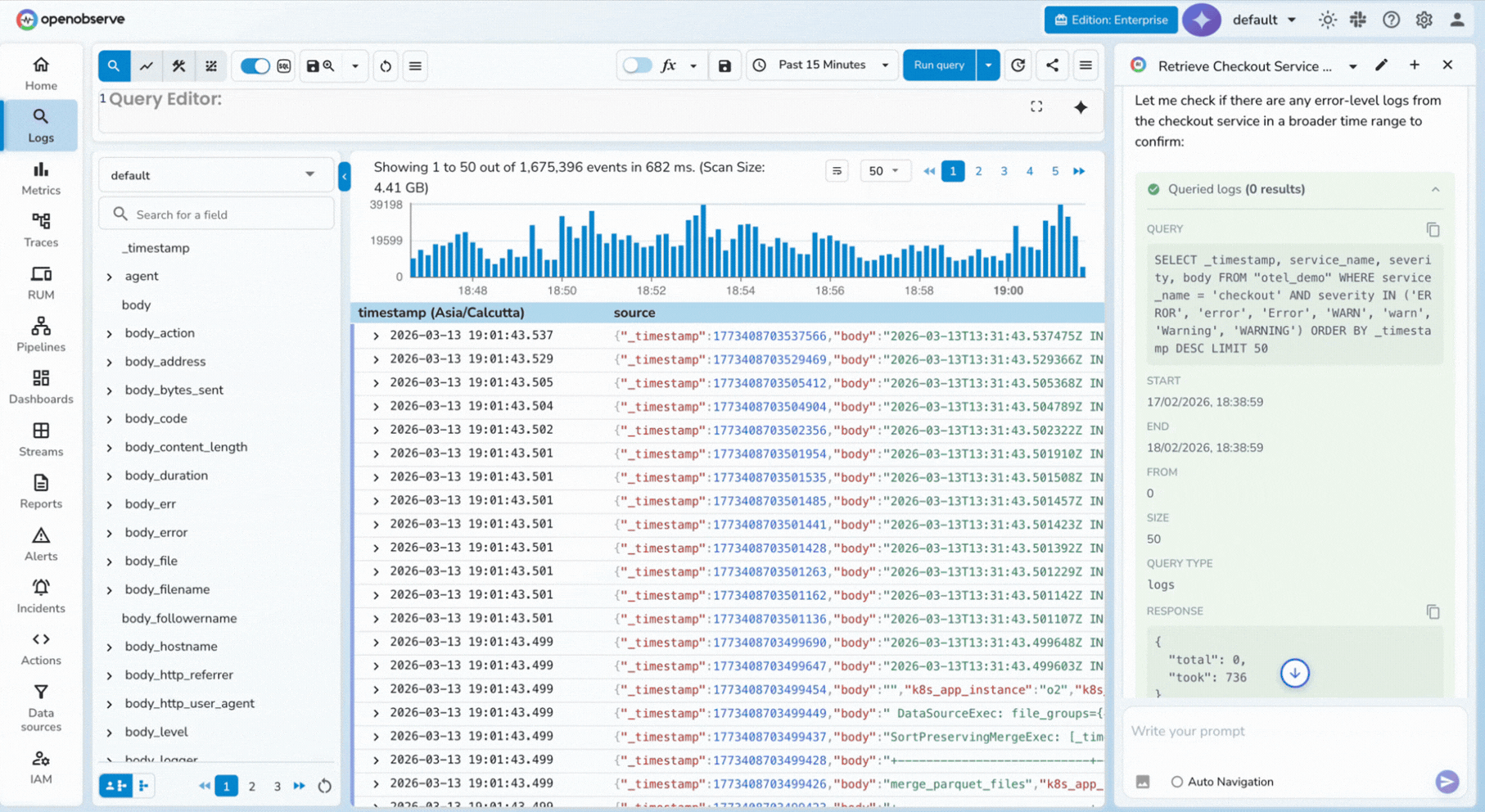
AI assistants are now part of incident response, but most still fail at one practical question: "What happened in production?"
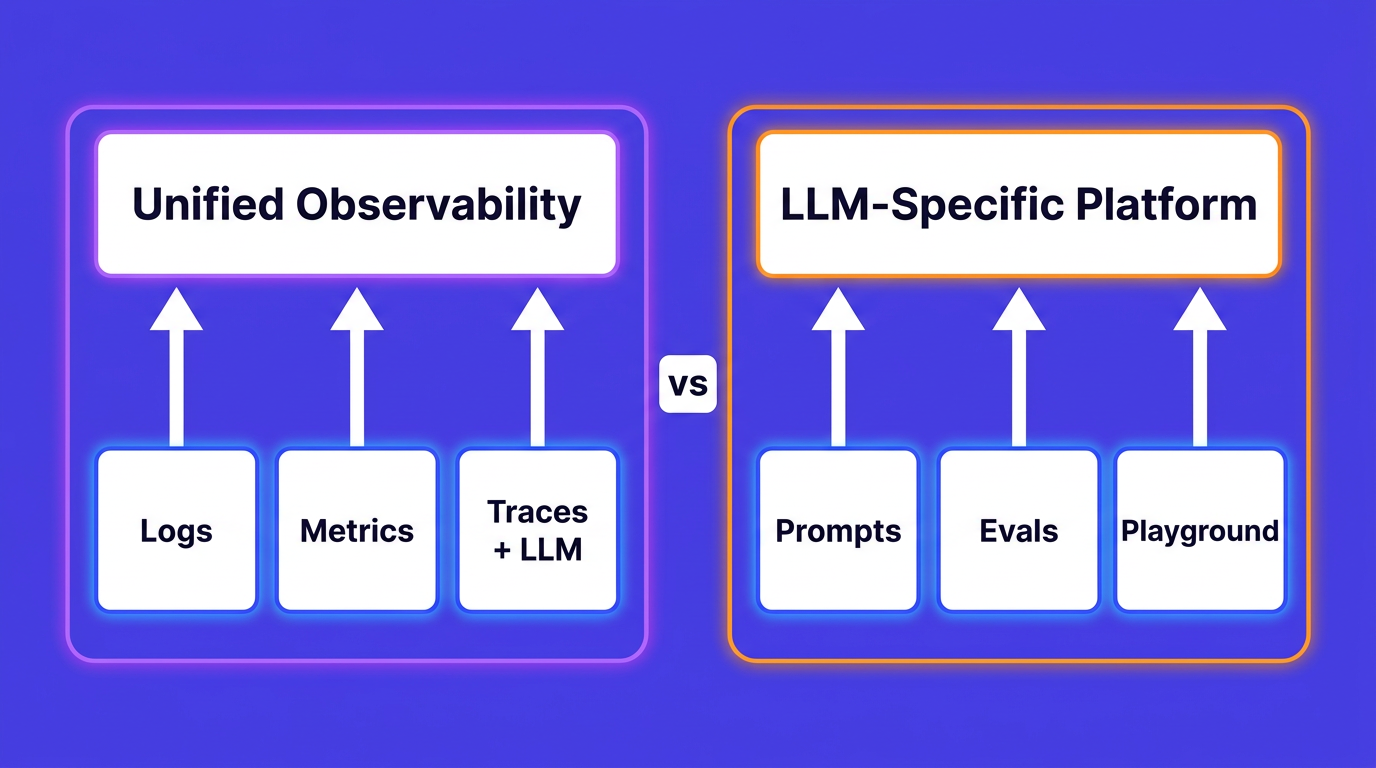
Without access to telemetry, they return generic advice. MCP servers for observability close that gap by connecting assistants to logs, metrics, traces, alerts, and incidents through the Model Context Protocol. Teams can then ask operational questions in natural language and get answers grounded in real production data.
claude mcp addAn MCP server for observability exposes telemetry capabilities as callable tools for AI assistants. Instead of manually switching dashboards, writing ad hoc SQL, and correlating timelines by hand, you can ask the assistant to fetch and analyze data for you.
The main MCP servers currently available for observability are OpenObserve, Datadog, IBM Instana, OneUptime, and Grafana. Grafana ships multiple MCP server implementations: mcp-grafana (covering dashboards, Loki logs, Prometheus metrics, Tempo traces, alerting, OnCall, and incidents), a dedicated loki-mcp, a Tempo MCP server, and Grafana Cloud MCP (currently in public preview). These servers expose logs, metrics, traces, and alert operations as callable tools for AI assistants via the Model Context Protocol, making it possible to query production telemetry in natural language from any compatible client.
| Platform | MCP Support | Query Depth | Alert Ops | Dashboard Ops | Deployment Model | Open Source |
|---|---|---|---|---|---|---|
| OpenObserve | Yes | Logs, metrics, traces via AI and SQL | Full CRUD | Yes | Cloud and self-hosted | Yes |
| Datadog | Yes | Strong query and incident context | Monitor management | Limited write scope | Cloud | No |
| IBM Instana | Yes | Trace-centric workflows | Limited | Limited | Cloud and on-prem | No |
| OneUptime | Yes | Status and incident-focused | Yes | Limited | Cloud and self-hosted | Yes |
| Grafana | Yes (mcp-grafana, loki-mcp, Tempo MCP; Cloud in preview) | Dashboards, Loki logs, Prometheus metrics, Tempo traces | Full rule management | Yes | Cloud and self-hosted | Yes |
When choosing among MCP servers for observability, evaluate:
You can ask: "What caused the latency spike in checkout at 2 AM?"
The assistant can pull errors, latency trends, and trace outliers, then summarize likely causes.
For teams optimizing response time, this pairs well with mean time to resolution best practices.
You can ask: "Create an alert when p95 latency is above 500 ms for 5 minutes in payment service."
With supported platforms, the assistant can create or update alert conditions directly.
You can ask: "Find unusual checkout errors from the last 7 days."
This workflow becomes stronger when combined with AI anomaly detection patterns.
MCP-driven querying is powerful, but data volume still affects cost.
If you process high-cardinality telemetry, review OpenTelemetry cost optimization strategies.
For teams building custom assistants and orchestration flows, combine MCP with AI agent monitoring patterns.
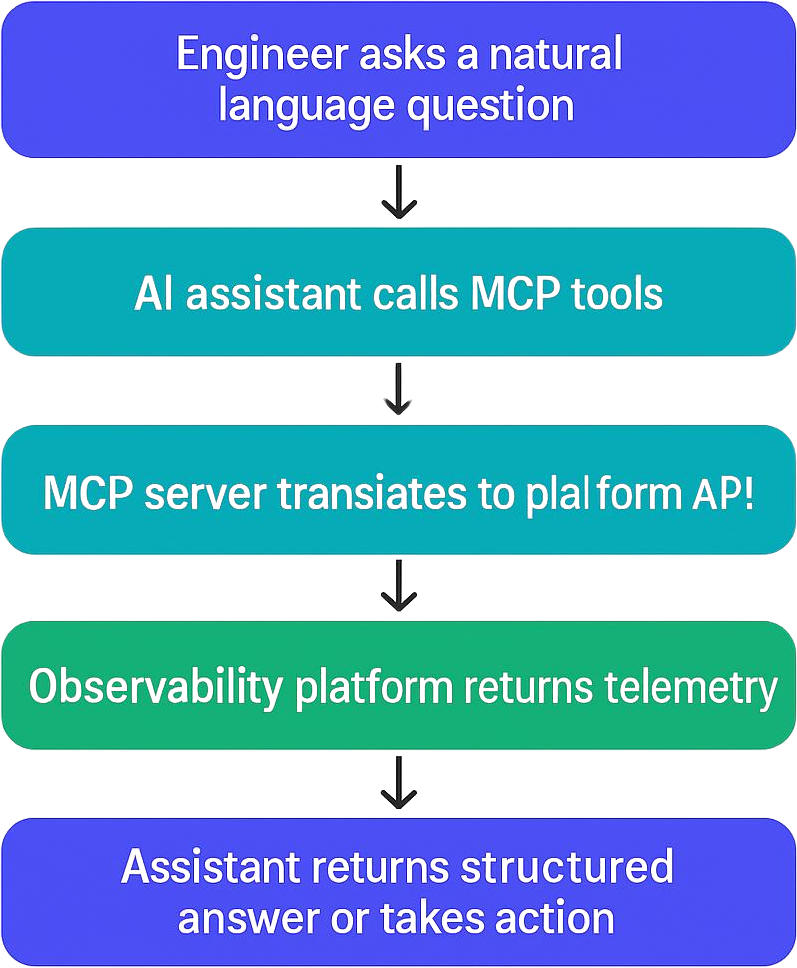
Any MCP-compatible AI client — including Claude Code, Claude Desktop, Cursor, and Cline — can connect to an observability platform through its MCP endpoint. The general pattern is the same regardless of platform or client:
The following example uses OpenObserve and Claude Code, but the same three-step pattern applies to Datadog, IBM Instana, OneUptime, and Grafana.
This setup pattern applies broadly to any MCP-compatible observability endpoint.
echo -n "your-email@example.com:your-password" | base64
claude mcp add o2 https://api.openobserve.ai/api/default/mcp \
-t http \
--header "Authorization: Basic <BASE64_TOKEN>"
claude mcp list
Inside Claude Code:
/mcp
Show me all 500 errors in payment service during the last hour
If your setup is correct, the assistant should discover tools with the mcp__o2__* prefix and return real telemetry-backed output.
Quick extraction format:
claude mcp add ... -t http --header "Authorization: Basic <TOKEN>"claude mcp list and /mcpOpenObserve goes beyond a single MCP connection — it has built a three-layer AI stack designed to transform incident response end to end.
OpenObserve's native MCP server lets you interact with your observability platform using LLMs like Claude directly from the tools your team already uses:
The OpenObserve AI Assistant is deeply integrated with the platform for everyday troubleshooting:
The O2 SRE Agent is an always-on SRE designed to optimize MTTD and MTTR:
| Lowest TCO | Ingestion-based pricing with no per-seat or per-host fees — 140x lower storage costs than traditional platforms |
| Unified platform | Logs, metrics, traces, and business events in one place — no tool sprawl |
| Native OpenTelemetry | Prevents vendor lock-in with open standards and seamless GenAI instrumentation |
| Three-layer AI stack | MCP + AI Assistant + SRE Agent working together for autonomous operations |
| Transparent AI | Complete visibility into AI decision-making with correlated data, alert graphs, and evidence chains |
| Deployment flexibility | Self-hosted on-prem for compliance or fully managed cloud |
| SQL + PromQL | Flexible analytics familiar to most engineering teams |
| Community maturity | The AI agent layer is newer compared to established vendors — factor in if you need a large existing ecosystem |
New to OpenObserve? Register for our Getting Started Workshop for a quick walkthrough.
MCP servers for observability are becoming a practical standard for AI-native operations. They let teams connect AI assistants to logs, metrics, and traces, reduce manual triage work, and speed up diagnosis with better context.
Manas is a passionate Dev and Cloud Advocate with a strong focus on cloud-native technologies, including observability, cloud, kubernetes, and opensource. building bridges between tech and community.