What Nobody Tells You About Running AI in Production
Explore latest insights and updates
Add real observability to CrewAI: map Crew, Agent, and Task objects to OpenTelemetry spans, tell CrewAI's own anonymous telemetry apart from your own tracing, and send the full multi-agent trace to OpenObserve.
Helicone entered maintenance mode after Mintlify's March 2026 acquisition, with new signups closed and the roadmap frozen. Here's how to move LLM observability off Helicone's proxy and onto OpenObserve: replace the base-URL proxy with OpenTelemetry instrumentation, map Properties, Users, and Sessions to gen_ai attributes, and get infra correlation in the same backend.
We optimized OpenObserve for speed and cost and let the UI take a backseat. You told us. Here is what we changed, and why we are not done.
You asked, we shipped: make one dashboard the org-wide landing view in OpenObserve. Pin it from the dashboard list or the dashboard header, and everyone on the team sees the same Home tab, server-side and across devices.
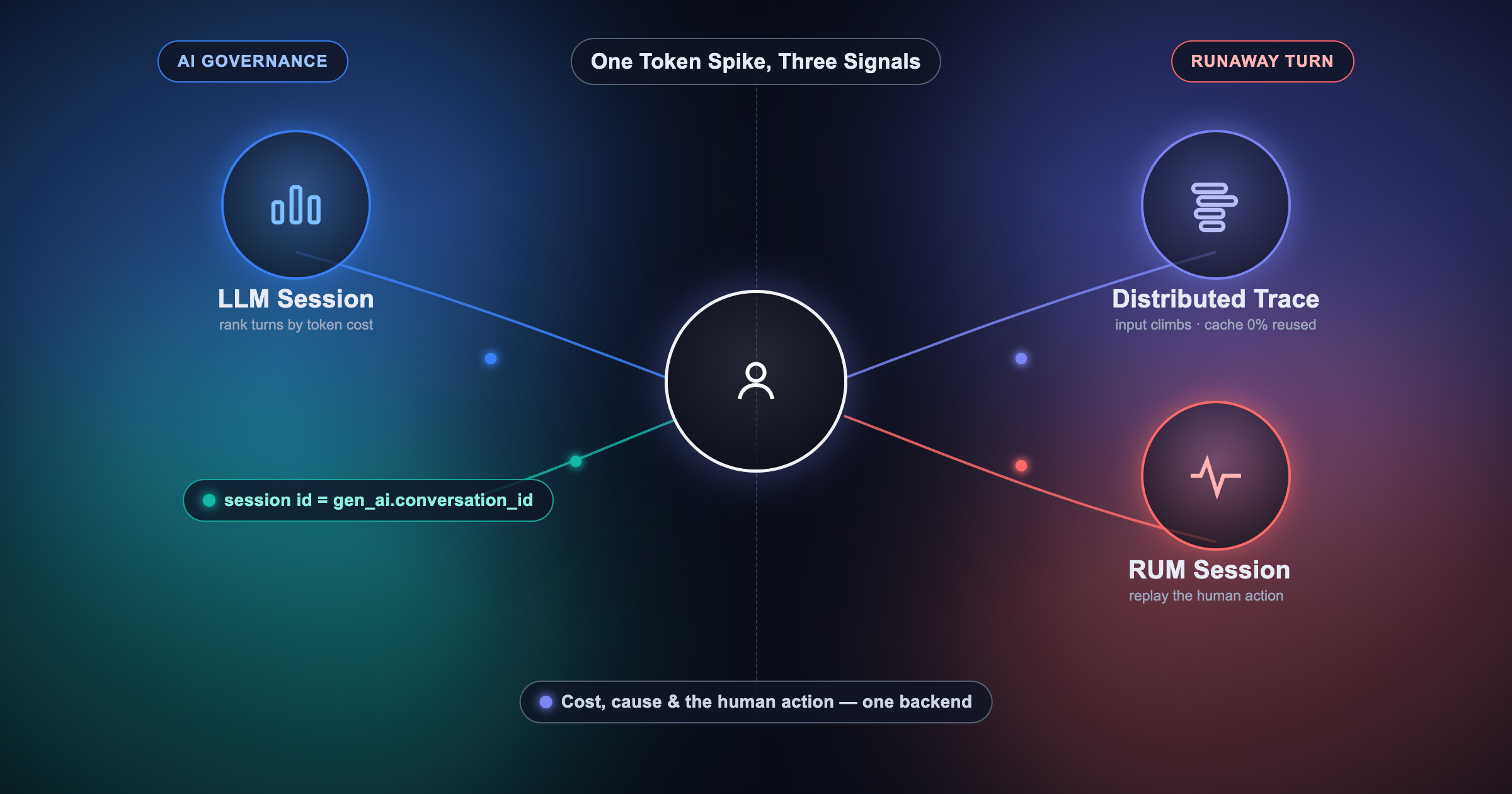
How an AI-governance engineer walks one anomalous LLM turn across three signals in OpenObserve — session, distributed trace, and RUM replay — to pin down cost, cause, and the human action behind a token spike.
Trace the OpenAI Agents SDK with OpenTelemetry: map handoffs, guardrails, and agent spans to OTLP and send the full trace to OpenObserve, not OpenAI's backend.
Twelve config-level tactics for observability cost optimization, sampling, pipeline filtering, retention tiers, and cardinality control, with before/after numbers and real config examples for logs, metrics, and traces.
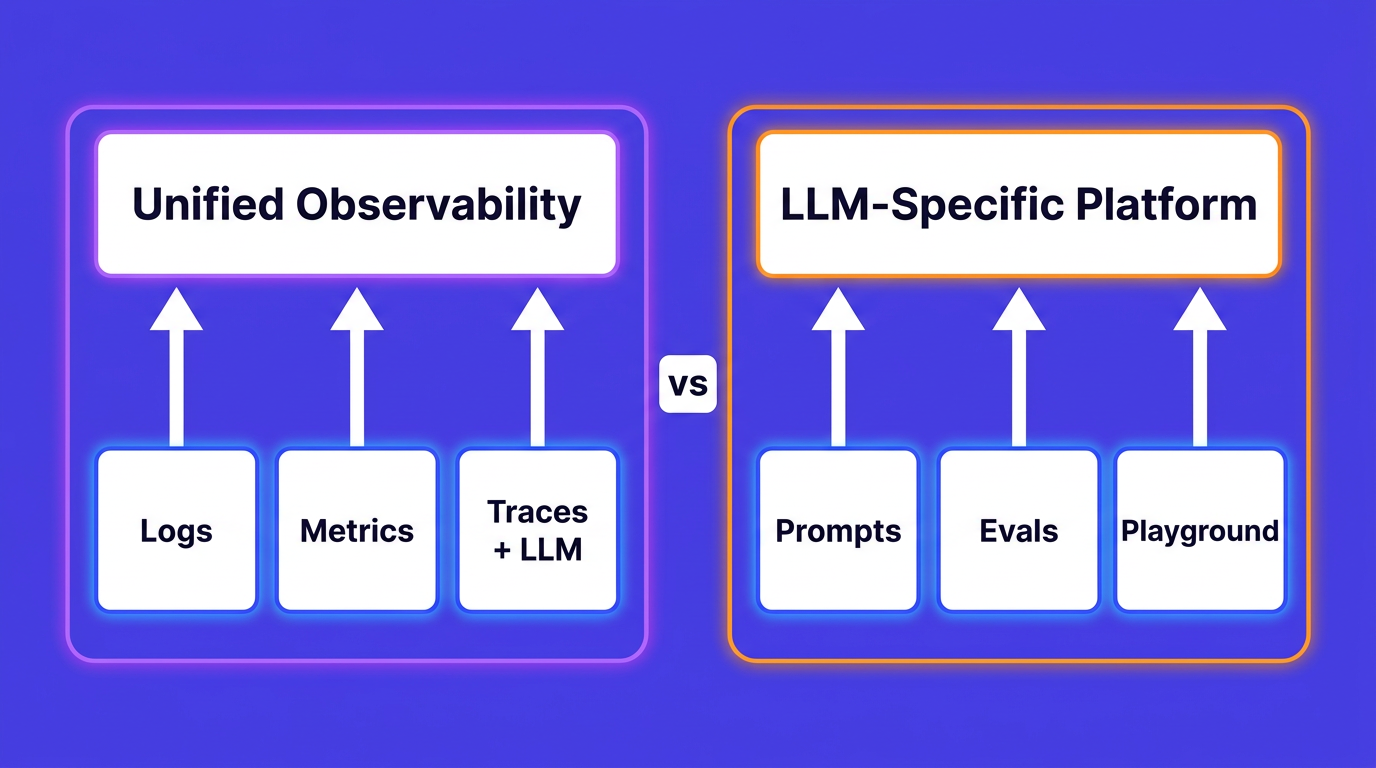
OpenObserve vs Langfuse in 2026: unified infra+LLM observability vs a dedicated LLM platform. Feature matrix, pricing, and when to use each (or both).
Compare the best log visualization tools in 2026: OpenObserve, Kibana, Grafana Loki, Datadog, and Splunk. Covers AI-assisted analysis, dashboard quality, and cost.
Compare the top 10 Datadog competitors in 2026: OpenObserve, Grafana, New Relic, Dynatrace, and Splunk. Pricing breakdowns, feature tables, and migration guidance for DevOps and SRE teams.
A practical guide to the best distributed tracing tools in 2026: OpenObserve, Jaeger, Grafana Tempo, Zipkin, and Honeycomb. Covers OTel compatibility, high-cardinality support, and deployment trade-offs.
Discover the best Elasticsearch alternatives in 2026. Compare OpenObserve, OpenSearch, ClickHouse, Grafana Loki, and Solr on cost, search performance, and deployment options.
A comprehensive comparison of open source LLM observability tools in 2026: OpenObserve, Langfuse, Helicone, and Arize Phoenix. Covers prompt tracing, cost tracking, evaluation frameworks, and unified infrastructure monitoring.
A practical comparison of the top log management tools in 2026: OpenObserve, Splunk, Datadog, Grafana Loki, and Elastic. Covers collection, indexing, retention, and cost for modern DevOps and SRE teams.
A practical guide to the top 10 microservices monitoring tools in 2026: OpenObserve, Grafana LGTM, Datadog, Dynatrace, and Prometheus. Covers unified telemetry, cardinality handling, and cost trade-offs.
A comprehensive comparison of the top 10 open source APM tools in 2026: OpenObserve, SigNoz, Jaeger, Grafana Tempo, and Zipkin. Covers unified observability, OpenTelemetry support, storage efficiency, and self-hosted deployment options.
Discover the best Splunk alternatives in 2026. Compare open-source and enterprise tools for log management, SIEM, and observability. Find cost-effective solutions with our comprehensive guide.
A practical guide to 15 essential SRE tools in 2026: OpenObserve, Datadog, PagerDuty, Prometheus, Jaeger, and LitmusChaos. Covers unified observability, alerting, incident management, SLO tracking, and chaos engineering.
Compare the best Lightstep alternatives following the March 2026 EOL. Covers OpenObserve, Jaeger, Grafana Tempo, Honeycomb, and Datadog APM with OpenTelemetry migration guides, cost comparisons, and high-cardinality tracing analysis.
A comprehensive comparison of the top 10 observability platforms in 2026 highlighting their strengths, trade-offs, and use-cases.
Explore the top observability tools and platforms in 2026. Compare features, use cases, and alternatives to Datadog for logs, metrics, and traces in this complete guide.