

OpenAI Assistants API → OpenObserve
Automatically capture thread creation, message handling, and run execution for every OpenAI Assistants API workflow in your Python application using the standard OpenAI instrumentor.
Note
The Assistants API is deprecated by OpenAI in favour of the Responses API. It continues to function and is fully instrumented by the OpenAI instrumentor.
Prerequisites
- Python 3.8+
- An OpenObserve account (cloud or self-hosted)
- Your OpenObserve organisation ID and Base64-encoded auth token
- An OpenAI API key
Installation
Configuration
Create a .env file in your project root:
OPENOBSERVE_URL=https://api.openobserve.ai/
OPENOBSERVE_ORG=your_org_id
OPENOBSERVE_AUTH_TOKEN=Basic <your_base64_token>
OPENAI_API_KEY=your-openai-api-key
Instrumentation
Call OpenAIInstrumentor().instrument() before importing or instantiating the OpenAI client.
import time
from dotenv import load_dotenv
load_dotenv()
from openinference.instrumentation.openai import OpenAIInstrumentor
from openobserve import openobserve_init
OpenAIInstrumentor().instrument()
openobserve_init()
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
assistant = client.beta.assistants.create(
name="Observability Assistant",
instructions="Answer questions about observability concisely in one sentence.",
model="gpt-4o-mini",
)
thread = client.beta.threads.create()
client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="What is OpenTelemetry?",
)
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
)
while run.status in ("queued", "in_progress"):
time.sleep(0.5)
run = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=run.id)
messages = client.beta.threads.messages.list(thread_id=thread.id)
print(messages.data[0].content[0].text.value)
client.beta.assistants.delete(assistant.id)
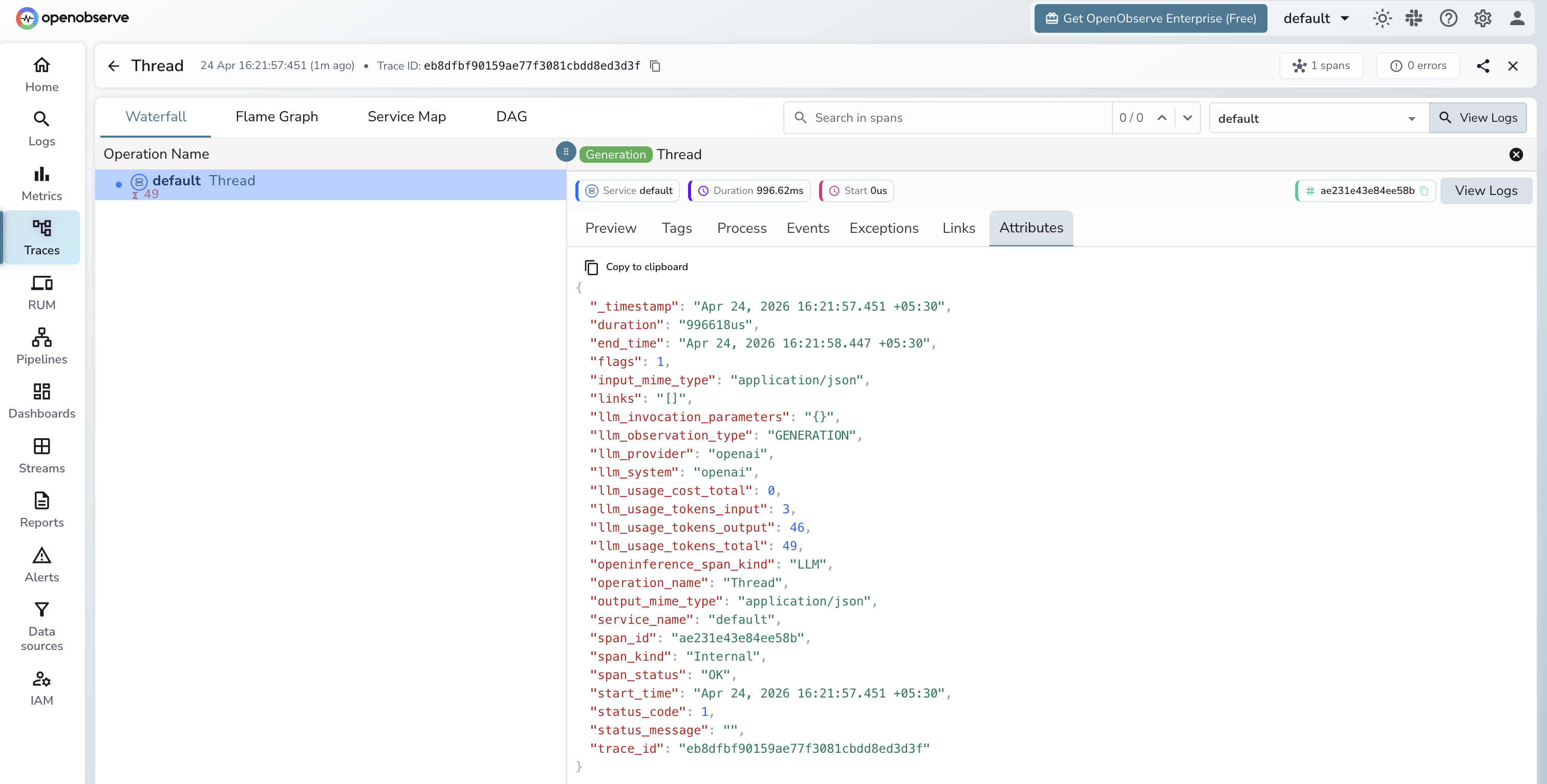
What Gets Captured
Each Assistants API workflow produces multiple spans — one per API call (thread creation, message creation, run creation, run retrieval, message listing).
| Attribute | Description |
|---|---|
openinference_span_kind |
LLM |
operation_name |
API resource called (e.g. Thread, Run) |
llm_provider |
openai |
llm_system |
openai |
llm_observation_type |
GENERATION |
llm_usage_tokens_input |
Input tokens consumed |
llm_usage_tokens_output |
Output tokens generated |
llm_usage_tokens_total |
Total tokens consumed |
llm_invocation_parameters |
Request parameters sent to the API |
input_mime_type |
application/json |
output_mime_type |
application/json |
duration |
Span latency |
span_status |
OK on success, ERROR on failure |
Viewing Traces
- Log in to OpenObserve and navigate to Traces in the left sidebar
- Each assistant interaction appears as a group of spans covering thread setup, run execution, and message retrieval
- Filter by
llm_provider = openaiandopeninference_span_kind = LLMto isolate Assistants API spans - Click any span to inspect token counts and run status
Next Steps
With the Assistants API instrumented, every thread run is recorded in OpenObserve. From here you can track token usage per assistant, monitor run latency across threads, and set alerts on failed runs.