

Together AI → OpenObserve
Automatically capture token usage, latency, and model metadata for every Together AI inference call in your Python application. Together AI exposes an OpenAI-compatible API, so instrumentation uses the standard OpenAI instrumentor pointed at the Together AI endpoint.
Prerequisites
- Python 3.8+
- An OpenObserve account (cloud or self-hosted)
- Your OpenObserve organisation ID and Base64-encoded auth token
- A Together AI API key
Installation
Configuration
Create a .env file in your project root:
OPENOBSERVE_URL=https://api.openobserve.ai/
OPENOBSERVE_ORG=your_org_id
OPENOBSERVE_AUTH_TOKEN=Basic <your_base64_token>
TOGETHER_API_KEY=your-together-ai-key
Instrumentation
Call OpenAIInstrumentor().instrument() before creating the OpenAI client. Point the client at the Together AI base URL and pass your Together AI API key.
from dotenv import load_dotenv
load_dotenv()
from openinference.instrumentation.openai import OpenAIInstrumentor
from openobserve import openobserve_init
OpenAIInstrumentor().instrument()
openobserve_init()
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["TOGETHER_API_KEY"],
base_url="https://api.together.xyz/v1",
)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-V3.1",
messages=[{"role": "user", "content": "Explain distributed tracing in one sentence."}],
)
print(response.choices[0].message.content)
What Gets Captured
| Attribute | Description |
|---|---|
llm_model_name |
Model name (e.g. deepseek-ai/DeepSeek-V3.1) |
gen_ai_response_model |
Model that served the response |
llm_provider |
together |
llm_system |
openai (the client library used) |
llm_token_count_prompt |
Tokens in the prompt |
llm_token_count_completion |
Tokens in the response |
llm_token_count_total |
Total tokens consumed |
llm_request_parameters_model |
Model requested |
llm_request_parameters_max_tokens |
Max tokens parameter |
openinference_span_kind |
LLM |
operation_name |
ChatCompletion |
duration |
End-to-end request latency |
span_status |
OK or error status |
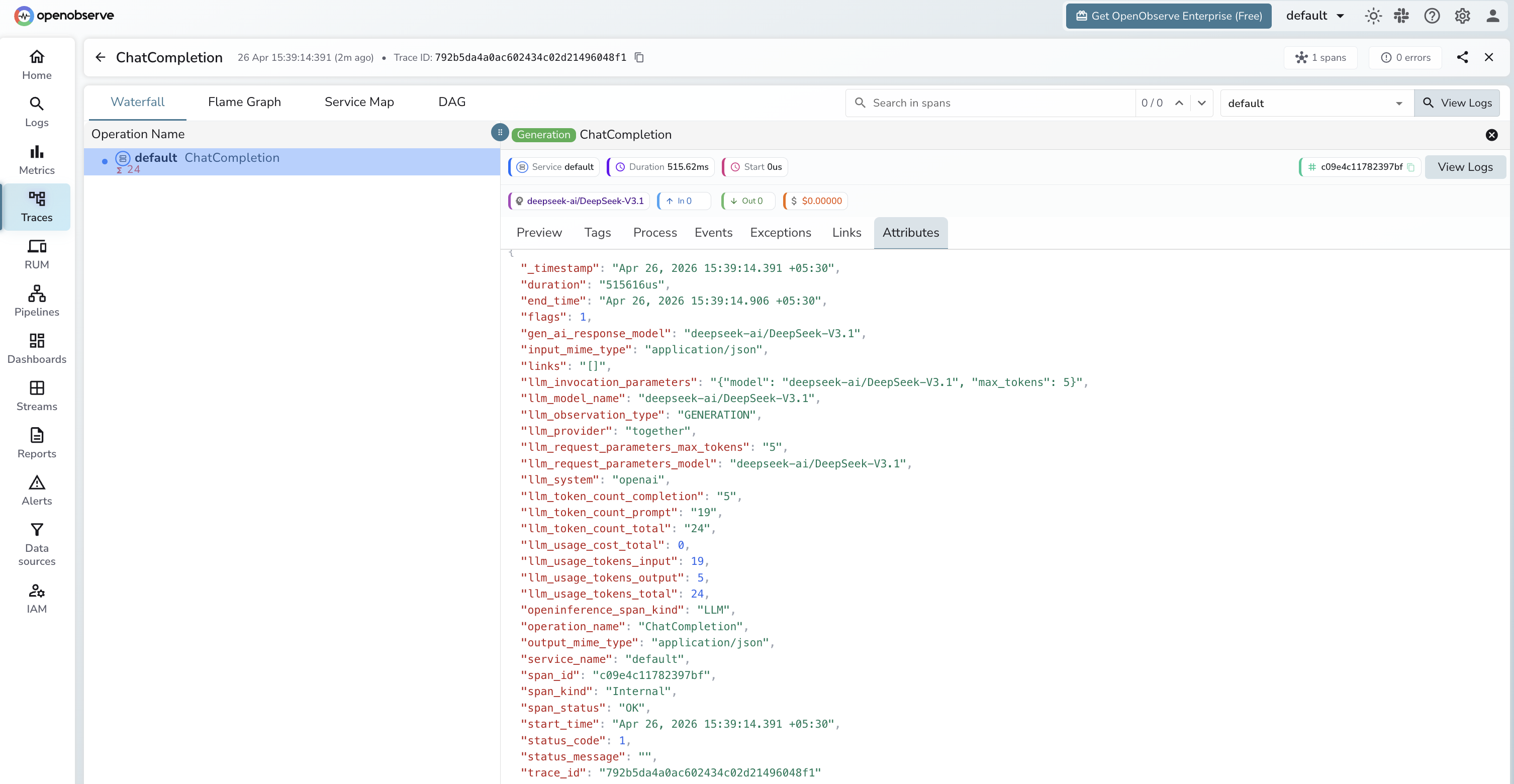
Viewing Traces
- Log in to OpenObserve and navigate to Traces
- Filter by
operation_name = ChatCompletionto find Together AI spans - Click any span to inspect token counts and the full request/response payload
- Filter by
llm_model_nameto compare latency across different Together AI models
Next Steps
With Together AI instrumented, every inference call is recorded in OpenObserve. From here you can compare token throughput across open-source models, monitor latency per model variant, and set alerts on error spans.